
...making Linux just a little more fun!
Ben Okopnik [ben at linuxgazette.net]
Run the following, one at a time:
aptitude -v moo aptitude -vv moo aptitude -vvv moo aptitude -vvvv moo aptitude -vvvvv moo aptitude -vvvvvv moo

-- * Ben Okopnik * Editor-in-Chief, Linux Gazette * http://LinuxGazette.NET *
[ Thread continues here (2 messages/1.58kB) ]
Dr. Parthasarathy S [drpartha at gmail.com]
I have received quite a few comments and suggestions concerning my "linusability" project. thank you all. I am trying to make a consoldiated summary of all suggestions I have received. I seem to have misplaced/lost some of the mails. I would like to retrieve them from the TAG mailing list. Is there an archive of TAG mails somewhere ? I tried but could get to only the archives of LG issues. Cat find TAG mail, back issues though.
Can someone guide me please ?
partha
PS You can follow my progress in the "linusability" project, from : http://www.profpartha.webs.com/linusability.htm
-- --------------------------------------------------------------------------------------------- Dr. S. Parthasarathy | mailto:drpartha at gmail.com Algologic Research & Solutions | 78 Sancharpuri Colony | Bowenpally P.O | Phone: + 91 - 40 - 2775 1650 Secunderabad 500 011 - INDIA | WWW-URL: http://algolog.tripod.com/nupartha.htm ---------------------------------------------------------------------------------------------
[ Thread continues here (4 messages/4.02kB) ]
Jimmy O'Regan [joregan at gmail.com]
On 27 June 2010 18:46, Jimmy O'Regan <joregan at gmail.com> wrote:
> Since I got commit access to Tesseract, I've been getting a little > more interested in image recognition in general, and I was pleased to > find a Java-based 'face annotation' system on Sourceforge: > http://faint.sourceforge.net >
I just saw this headline on ReadWriteWeb: "Facebook Adds Facial Recognition" (http://www.readwriteweb.com/archives/facebook_adds_facial_recognition.php). Of course, being a blog aimed more at management types, they are, of course, wrong. According to Facebook (http://blog.facebook.com/blog.php?post=403838582130) they've added face detection...
They're probably either using OpenCV or the part of the Neven code that Google added to Android (http://android.git.kernel.org/?p=platform/external/neven.git;a=summary)
-- <Leftmost> jimregan, that's because deep inside you, you are evil. <Leftmost> Also not-so-deep inside you.
Jimmy O'Regan [joregan at gmail.com]
This is, hands down, the single dumbest bug report I've ever seen: http://code.google.com/p/tesseract-ocr/issues/detail?id=337
I'm kind of reminded of the usability thread, because whenever I see a dumb question on the Tesseract list, or in the issue tracker, it's always a Windows user.
But mostly, I'm just wondering: can anybody think of a valid reason why anyone would want to OCR a CAPTCHA?
-- <Leftmost> jimregan, that's because deep inside you, you are evil. <Leftmost> Also not-so-deep inside you.
[ Thread continues here (9 messages/11.70kB) ]
Ben Okopnik [ben at linuxgazette.net]
Hi, all -
I've been trying to do some research on this topic, but am coming up dry (or at least very sparse on good choices.) I'm hoping that someone here will have an answer.
A few days ago, I got an AirPort Extreme - a wireless bridge + USB gadget from Apple - so I could "unwire" my poor spiderwebbed laptop. Had to set it up on a Windows machine [1], then started playing around with the possibilities. Plugged in my new high-gain "client bridge" that's up my mast (really, really impressive gadget, by the way - http://islandtimepc.com/marine_wifi.html) - PoE connector snaps right into the WAN plug, AirPort hooks into it, life is good. Plugged in a USB hub, hooked up my HP printer, told the AirPort software to share it - OK, that's all fine too. Hooked up the external hard drive... um. Well, OK, a few hours of struggling with Windows file sharing, and Samba, and more file sharing, and... argh. My external HD is formatted as ext3, so - no joy there, despite Macs running BSD these days. No way am I going to reformat it. Also, plugging in an external CD-ROM was a total fail: the AirPort doesn't recognize it, even when plugged in directly without a hub. In addition, there's no HTTP interface on this thing: you have to use their (Windows or Mac only) software to talk to it.
So, the AirPort is going back to the store - but now, I'm stuck with a dream. It would be really, really nice to just connect power and maybe an external monitor to the laptop, and have the external drive, a CD-ROM, the printer, and the network all available wirelessly. After noodling on this for a bit, a small light went on. I said to myself: "Self... what if you had a small beige box of some sort that was running Linux and had all that stuff plugged into it?" At that point, none of the above peripherals would present a problem: they'd just be available stuff, accessible via standard protocols.
The only question is, what's the cheapest, smallest box that I can get? Obviously, it needs to have at least one USB port, one Ethernet port, and be accessible via WiFi. If it runs on 12 volts, that would be a great plus. Recommendations on a flavor of Linux to run on this gadget would also be welcome.
Thanks in advance for any suggestions!
[1] All FOSS-vs.-proprietary rhetoric aside... how the HELL do people put up with Windows? I had to struggle through so many "YOUR MACHINE MAY BE INFECTED!!! BUY OUR SOFTWARE ***NOW!!!***" warnings, update-and-reboot repeats, instances of software automatically firing up a browser and taking you to the company webpage, and completely senseless procedures ("sharing" a network-accessible disk is a complete lather-rinse-repeat nightmare) that I found myself literally screaming "STOP already!" in frustration. And I'm not what you'd call computer-illiterate, nor completely unfamiliar with Windows - although I haven't used it in several years. That was just a horrible experience that I hope I never have to repeat.
-- * Ben Okopnik * Editor-in-Chief, Linux Gazette * http://LinuxGazette.NET *
[ Thread continues here (12 messages/21.75kB) ]
Dr. Parthasarathy S [drpartha at gmail.com]
One frequent problem faced by Linux adherents like me is the difficulty of finding hardware which is supported by Linux. Here is some hope for us::
http://www.linuxpromagazine.com/Online/News/Open-Source-Hardware-Gets-Defined
Take a look.
partha
-- --------------------------------------------------------------------------------------------- Dr. S. Parthasarathy | mailto:drpartha at gmail.com Algologic Research & Solutions | 78 Sancharpuri Colony | Bowenpally P.O | Phone: + 91 - 40 - 2775 1650 Secunderabad 500 011 - INDIA | WWW-URL: http://algolog.tripod.com/nupartha.htm ---------------------------------------------------------------------------------------------
[ Thread continues here (2 messages/3.59kB) ]
Ben Okopnik [ben at linuxgazette.net]
----- Forwarded message from "Mikko V. Viinam?ki" <Mikko.Viinamaki at students.turkuamk.fi> -----
Date: Sat, 10 Jul 2010 20:35:36 +0300 From: "Mikko V. Viinam?ki" <[email protected]> To: TAG <[email protected]> To: "editor at linuxgazette.net" <editor at linuxgazette.net> Subject: On the use of flashI just wanted to object. No cartoon is way better than a flash cartoon.
I see you've hashed it somewhat already. Just my 2 cents.
I really like the gazette otherwise.
Mikko
----- End forwarded message -----
-- * Ben Okopnik * Editor-in-Chief, Linux Gazette * http://LinuxGazette.NET *
[ Thread continues here (7 messages/11.63kB) ]
Neil Youngman [ny at youngman.org.uk]
A family member has a number of directories containing photos in JPEG format. 3 directories contain different versions of the same collection of photos. One is the current master and the others are earlier snapshots of the same collection. I believe that all the photos in the older snapshots are present in the current master, but I would like to verify that before I delete them. Also many other directories probably contain duplicates of photos in the master collection and I would like to clean those up.
Identifying and cleaning up byte for byte identical JPEGs in the snapshots has freed up a considerable amount of disk space. A sample of the remaining photos suggests that they are probably in the master, but the tags and position in the directory tree have changed. I don't want to go through comparing them all by hand.
Initial research suggests that ImageMagick can produce a "signature", which is a SHA256 checksum of the image data. I believe that this would be suitable for identifying identical images, on which the tags have been altered.
Are there any graphics experts in the gang who can confirm this? Alternatively suggestions of existing tools that will do the job, or better approaches, would be most welcome.
Neil
[ Thread continues here (26 messages/33.37kB) ]
Neil Youngman [ny at youngman.org.uk]
Recently I've needed to recover photos from 2 compact flash cards, one of which was accidentally formatted and one of which was faulty. Subsequently I have used the "expertise" acquired to recover photos from a formatted SD card as a favour to a random stranger on the internet.
The first thing I did was backup the card, using a simple dd if=/dev/sdX1 of=/path/to/data
The first time I did this, I was in a hurry. I had seen a lot of recommendations for a Windows tool called Recuva and I didn't want to spend much time on research, so I just grabbed a copy of that. It seemed to work just fine "recovering" 1045 files, but on closer inspection, none of them were complete. They should have been 3-5 MB jpegs, but they were all about 1.5MB and only the thumbnails were viewable. I messed about with the settings, to no effect and looked at a couple of other Windows tools, before I saw a recommendation for photorec, which is part of Christophe Grenier's testdisk suite. http://www.cgsecurity.org/wiki/PhotoRec
Photorec looked like a Unix native tool, so I downloaded the appropriate tarball, unpacked it and ran it. It took the file name of my backup as an argument, so I didn't even need to have the card handy. I walked through a few simple menu options and it recovered just over 1000 photos. This time they all appeared to complete, full resolution photos. As far as I could tell there was nothing missing.
Reading through the instructions, I found that there was probably junk data at the end of the photos, which could be removed by running convert (from the ImageMagick suite) on the jpeg.
The sequence of commands below is how I recovered the photos from the SD card.
$ dd if=/dev/sdd1 of=/tmp/sdcard.bin $ ~/testdisk-6.11.3/linux/photorec_static /tmp/sdcard.bin $ mkdir /tmp/recovered $ for file in /tmp/recup_dir.1/*.jpg; do convert "$file" "/tmp/recovered/$(basename $file)"; done
The first command is just a binary copy of the raw data from the SD card to a file.
The next command obviously runs photorec itself. In the menus, just accepting the defaults is usually sufficient, but you have to select a directory in which to store the results. Photorec actually creates subdirectories under that directory, called recup_dir.N. In this case I selected /tmp/ to store the recovered photos in.
Having recovered the photos, I created the directory /tmp/recovered and ran a loop, calling convert on the files, as explained above. That directory, containing the final results was then burned to a CD, which was sent to the owner of the photos.
As you can see photorec is a very simple tool to use and as far as I could, it recovered all the files that we expected to find on the various flash cards. I would recommend it to anyone who has a need to recover photos from a corrupt, defective or formatted flash card.
Neil Youngman
[ Thread continues here (2 messages/3.82kB) ]
Deividson Okopnik [deivid.okop at gmail.com]
Hello TAG!
Im doing some research in here, and was wondering if any of you ever worked with external sensors.
What i had in mind was having temp/humidity sensors plugged into my computer and reading theyr values on linux to use on some program ill write.
If anyone ever did this, what kind of hardware did you use?
[ Thread continues here (5 messages/8.48kB) ]
Dr. Parthasarathy S [drpartha at gmail.com]
Linux usability -- an introspection (Code name :: linusability)
In spite of all claims and evidence regarding the superiority of Linux, one aspect of Linux remains to be its major weakness -- usability. This may be the reason for its slow acceptance by the not-so-geeky user community. I am launhing a serious study into various aspects of the usability aspects of Linux, so as to list out the problems and hopefully help some people offer solutions.
I need help. Please, if you have any ideas on this subject, or if you know any sources where I can get directions, or if there is something I should (or should not) do, let me know directly, by email. I will compile all my findings, and post them back in this forum. Let us make Linux more enjoyable by more people.
Many thanks,
partha AT gmail DOT com
-- --------------------------------------------------------------------------------------------- Dr. S. Parthasarathy | mailto:drpartha at gmail.com Algologic Research & Solutions | 78 Sancharpuri Colony | Bowenpally P.O | Phone: + 91 - 40 - 2775 1650 Secunderabad 500 011 - INDIA | WWW-URL: http://algolog.tripod.com/nupartha.htm ---------------------------------------------------------------------------------------------
[ Thread continues here (19 messages/62.99kB) ]
Kiniti Patrick [pkiniti at techmaxkenya.com]
Hi Tag,
I am currently running Fedora 11 on my Laptop and have run into some problem. My Laptop has been spewing random errors on boot up, displaying the following "crc error kernel panic - not Syncing VFS unable to mount root fs on unknown block (0,0). The boot process fails at this point. Following this, i tried to boot the Laptop using a Linux Dvd and run into the following roadblock. The error message displayed is " RAMDISK: incomplete write (13513 != 32768) write error Kernel Panic - not Syncing: VFS : unable to mount root fs on unknown block (0, 0). Has anyone experienced a similar problem. Kindly assist on how i can recover from the error. Thanks in advance.
Regards,
Kiniti Patrick
[ Thread continues here (8 messages/12.66kB) ]
Ben Okopnik [ben at linuxgazette.net]
Hi, Silas -
On Mon, Jul 12, 2010 at 03:41:55PM +0100, Silas S. Brown wrote:
> (This message contains Chinese characters > in the UTF-8 encoding.)
That should show up fine in LG; all our HTML has 'UTF-8' specified as the encoding.
> I'd like to add two comment to my article > about using the Chinese instant messaging > service "QQ" on Linux, at > http://linuxgazette.net/167/brownss.html
Just FYI - we generally avoid changing articles after publication. Given that we have quite a few mirror sites, all of which pull our new issues shortly after publication (and then never touch them again), changing our copy would just put us out of sync with the rest of the world.
The best way to "update" an article is either by writing a new one about the updated state of things - or do what you've done here, i.e. post to TAG.
祝 一切顺利!
-- * Ben Okopnik * Editor-in-Chief, Linux Gazette * http://LinuxGazette.NET *
[ Thread continues here (5 messages/3.92kB) ]
| Share |

|
Mulyadi Santosa [mulyadi.santosa at gmail.com]
Probably one of my shortest tips so far:
Confused with all those /proc, /sys, /dev, /boot etc really mean and
why on Earth they are there? Simply type "man hier" in your shell and
hopefully you'll understand
-- regards,
Mulyadi Santosa Freelance Linux trainer and consultant
blog: the-hydra.blogspot.com training: mulyaditraining.blogspot.com
[ Thread continues here (4 messages/3.80kB) ]
Ben Okopnik [ben at linuxgazette.net]
I was doing some PDF to HTML conversions today, and noticed some really ugly, borken content in the resulting files; the content had obviously been created via some Microsoft program (probably Word):
Just say ?<80><98>hello, world!?<80><99>?<80><9d>
I had a few dozen docs to fix, and didn't have a mapping of the characters with which I wanted to replace these ugly clumps of hex. That is, I could see what I wanted, but expressing it in code would take a bit more than that.
Then, I got hit by an idea. After I got up, rubbed the bruise, and took an aspirin, I wrote the following:
#!/usr/bin/perl -w
# Created by Ben Okopnik on Fri Jul 23 12:05:05 EDT 2010
use encoding qw/utf-8/;
my ($s, %seen) = do { local $/; <> };
# Delete all "normal" characters
$s =~ s/[\011\012\015\040-\176]//g;
print "#!/usr/bin/perl -i~ -wp\n\n";
for (split //, $s){ next if $seen{$_}++; print "s/$_//g;\n"; }
When this script is given a list of all the text files as arguments, it collects a unique list of the UTF-8 versions of all the "weird" characters and outputs a second Perl script which you can now edit to define the replacements:
#!/usr/bin/perl -i~ -wp s/\xFE\xFF//g; s/?//g; s/?//g; s/?//g; s/?//g; s/?//g; s/?//g; s/?//g; s/?//g;
Note that the second half of each substitution is empty; that's where you put in your replacements, like so:
#!/usr/bin/perl -i~ -wp s/\xFE\xFF//g; # We'll get rid of the 'BOM' marker s/?/"/g; s/?/-/g; s/?/'/g; s/?/"/g; s/?/-/g; s/?/.../g; s/?/'/g; s/?/©/g; # We'll make an HTML entity out of this one
Now, just make this script executable, feed it a list of all your text files, and live happily ever after. Note that the original versions will be preserved with a '~' appended to their filenames, just in case.
-- * Ben Okopnik * Editor-in-Chief, Linux Gazette * http://LinuxGazette.NET *
[ Thread continues here (5 messages/7.54kB) ]
| Share |
|
By Deividson Luiz Okopnik and Howard Dyckoff

|
Contents: |
Please submit your News Bytes items in plain text; other formats may be rejected without reading. [You have been warned!] A one- or two-paragraph summary plus a URL has a much higher chance of being published than an entire press release. Submit items to [email protected]. Deividson can also be reached via twitter.
 Rackspace and NASA Open Source Cloud Platform
Rackspace and NASA Open Source Cloud PlatformIn July, Rackspace Hosting announced the launch of OpenStack, an open-source cloud platform designed to foster the emergence of technology standards and cloud interoperability. Rackspace is donating the code that powers its Cloud Files and Cloud Servers public-cloud offerings to the OpenStack project.
The project will also incorporate technology that powers the NASA Nebula Cloud Platform.
Rackspace and NASA plan to actively collaborate on joint technology development and leverage the efforts of open-source software developers worldwide.
"We are founding the OpenStack initiative to help drive industry standards, prevent vendor lock-in and generally increase the velocity of innovation in cloud technologies," said Lew Moorman, President, Cloud and CSO at Rackspace. "We are proud to have NASA's support in this effort. Its Nebula Cloud Platform is a tremendous boost to the OpenStack community. We expect ongoing collaboration with NASA and the rest of the community to drive more-rapid cloud adoption and innovation, in the private and public spheres."
A fully distributed object store based on Rackspace Cloud Files is now at OpenStack.org. The next component planned for release is a scalable compute-provisioning engine based on the NASA Nebula cloud technology and Rackspace Cloud Servers technology. It is expected to be available later this year. Using these components, organizations would be able to turn physical hardware into scalable and extensible cloud environments using the same code currently in production serving tens of thousands of customers and large government projects.
Marvell Open-sources Easy Plug Computer InstallerMarvell announced the availability of the open source Easy Plug-Computer Installer (EPI) to simplify Plug Computing software deployment. EPI is a wizard-based installation tool for Marvell's Plug Computer design, providing Plug Computer developers with a faster way to build their low-power Plug Computing solutions. Plug Computers are headless servers with open source HW and SW specifications. Some of the common parts are used in mobile phones and run at very low power.
The award-winning Plug Computer design makes always on, green computing readily available for developers and end-users. Plug Computers feature a 2 GHz Marvell ARMADA 300 processor, and optional built-in hard-disk drive and embedded Marvell Wi-Fi and Bluetooth technologies. The enclosure can be just a few cubic inches with an ethernet port and a USB port. Additional peripherals such as Direct Attached Storage (DAS) can be connected using the USB 2.0 port. Multiple standard Linux 2.6 kernel distributions are supported on the Plug Computer development platform. The enclosure plugs directly into a standard wall socket and draws less than one tenth of the power of a typical PC being used as a home server. For more information, please visit http://www.plugcomputer.org.
Bob Salem, director of marketing at Marvell, told Linux Gazette that "... its a bit tedious to reprogram the plug. Our new EP installer makes this simpler and faster. There is no jtag, no set up. EPI allows our partners to remotely upgrade their hardware in the field."
"Marvell wants to encourage more developers to explore Plug Computing and the high performance, eco-friendly open source computing platform,"said Viren Shah, Senior Director of Marketing Embedded Systems at Marvell's Enterprise Business Unit.
Examples of Plug Computers currently available for purchase at $89-$99 are Cloud Engines' PogoPlug, Axentra's HipServ for PlugTop Computing, and the TonidoPlug low-power, personal server and NAS device which uses embedded Ubuntu 9.04 Linux.
EPI can be used to install Linux distributions, file systems, file system images or single applications. The application provides USB key and HTTP-based list retrieval, further expanding the ways in which developers can access and update Plug Computers. Developers also will have access to step-by-step instructions for successful deployment, along with access to new developments put forth by the Plug Computing community. The EPI is compatible with Fedora 11, Ubuntu 9.04, Windows XP SP2/3, and Mac OSX (Leopard).
The Easy Plug-Computer Installer and Marvell Plug Computers were on display at the OSCON 2010 tradeshow in Portland, Oregon in July. EPI and supporting information is currently available for download at http://sourceforge.net/projects/esia/.
Marvell will host first meeting of the new devleoper community at the Plugin Developer Day at their Santa Clara headquarters on Aug 18.
MeeGo Platform Chosen by the GENIVI AllianceThe Linux Foundation announced that GENIVI, an auto-alliance driving the adoption of In-Vehicle Infotainment (IVI), will adopt MeeGo as the standard for IVI in vehicles manufactured by car companies like BMW and General Motors. It had voiced support for MeeGo before but is now officially using it for its next IVI reference release (called Apollo).
MeeGo is an open source platform hosted by the Linux Foundation that brings together Intel and Nokia's previous mobile projects for computing devices such as smartphones, netbooks, tablets, mediaphones, connected TVs and IVI systems. MeeGo's platform contains a Linux base, middleware, and an interface layer that powers these rich applications.
IVI is a rapidly evolving field that encompasses the digital applications that can be used by all occupants of a vehicle, including navigation, entertainment, location-based services, and connectivity to devices, car networks and broadband networks. MeeGo will provide the base for the upcoming GENIVI Apollo release that will be used by members to reduce time to market and the cost of IVI development.
"We selected MeeGo as the open source basis for our platform because it is technically innovative and can provide the cross architecture build support we require for our references," said Graham Smethurst, President of GENIVI. "Working with MeeGo we expect to establish a solution that effectively merges IVI needs with those of the other MeeGo target device categories."
GENIVI is a nonprofit industry alliance with founding members BMW Group, Wind River, Intel, GM, PSA, Delphi, Magneti-Marelli, and Visteon.
An initial release of the MeeGo platform is available now from http://www.meego.com/downloads. The MeeGo project encourages all automakers or industry groups to participate in the MeeGo project or make use of its software to power their own distributions.
OpenDocument 1.2 available for review for 60 daysThe complete draft of version 1.2 of the OpenDocument (ODF) standard was made publicly available in early July. Developers, potential users and others are invited to submit their comments on the draft before the 6th of September. Before the end of the fourth quarter of 2010, the members of the OASIS working group lead by Rob Weir, followed by the entire OASIS (Organisation for the Advancement of Structured Information Standards) membership, will vote then on whether to adopt the draft as an official OASIS standard.
If approved, the standard will then be presented to the ISO (International Standardisation Organisation) to be ratified as the current version of the ISO 26300 standard. OASIS is in charge of maintaining this standard, which will promote the exchange of documents between different office suites.
Version 1.2 of the ODF has been particularly improved in terms of mathematical formulae. According to a blog post by Rob Weir, the use of OpenFormula is not just designed to be used as a part of ODF, but also as a stand-alone syntax for other applications such as a separate equation parser.
Microsoft in particular had repeatedly criticised the previously only rudimentary definition of mathematical formulae in ODF spreadsheets as an interoperability flaw of the OpenDocument standard. The competing OOXML standard, driven by MS, describes every mathematical function that may appear as part of a formula in an Excel spreadsheet cell in great detail - which is one of the reasons why the Microsoft standard in turn has been heavily criticised for its more than 6,000 printed pages. The ODF 1.2 specification including OpenFormula comprises 1,100 pages.
LinuxCon is the industry's premiere Linux conference that provides an unmatched collaboration and education space for all matters Linux. LinuxCon brings together the best and brightest that the Linux community has to offer,including core developers, administrators, end users, business executives and operations experts - the best technical talent and the decision makers and industry experts who are involved in the Linux community. Registration and information: http://events.linuxfoundation.org/events/linuxcon
Please register at the link below using this 20% discount code: LCB_LG10
http://events.linuxfoundation.org/component/registrationpro/?func=details&did=27

Join us at the 19th USENIX Security Symposium, August 11–13, 2010, in Washington, D.C.
Whether you're a researcher, a system administrator, or a policy wonk, come to USENIX Security '10 to find out how changes in computer security are going to affect you. The 3-day program includes an innovative technical program, starting with a keynote address by Roger G. Johnston of the Vulnerability Assessment Team at Argonne National Laboratory; invited talks, including "Toward an Open and Secure Platform for Using the Web," by Will Drewry, Google; a refereed papers track, including 30 papers presenting the newest advances; and a Poster session displaying the latest preliminary research. Gain valuable knowledge on a variety of subject areas, including detection of network attacks, privacy, Internet security, Web security, and more.

 .Red Hat Enterprise Virtualization 2.2 Integrates Server and Desktop
.Red Hat Enterprise Virtualization 2.2 Integrates Server and DesktopFrom the RED HAT SUMMIT & JBOSS WORLD in June, Red Hat announced the general availability of Red Hat Enterprise Virtualization 2.2. In addition to providing the first release of Red Hat Enterprise Virtualization for Desktops, the 2.2 update includes new scalability capabilities, migration tools and features to expand the performance and security of the solution.
Red Hat Enterprise Virtualization 2.1, which introduced Red Hat Enterprise Virtualization for Servers, was released in November 2009. Designed as a foundation for the virtualization of Red Hat Enterprise Linux and Microsoft Windows, with Microsoft SVVP certification, as well as for cloud computing environments, Red Hat Enterprise Virtualization has gained momentum with customers, including Fujitsu, IBM and NTT Communications, for their cloud deployments.
"As enterprises look to move beyond initial server consolidation to a more pervasive datacenter-wide virtualization strategy, they are looking to Red Hat Enterprise Virtualization to provide leading scalability and economics," said Navin Thadani, senior director, Virtualization Business at Red Hat. "Already experiencing traction with server and cloud deployments, the solution expands its reach today with the delivery of our desktop virtualization management capabilities to help more customers to break down the barriers to virtualization adoption."
Red Hat Enterprise Virtualization for Desktops, introduced in today's 2.2 update, allows customers to deploy Hosted Virtual Desktop (HVD) configurations, also known as Virtual Desktop Infrastructure (VDI), bringing scalable, centralized provisioning and management of their desktop systems. It provides a web-based connection broker that allows end users to access their hosted virtual desktops, coupled with the open source SPICE remote rendering technology, which offers a rich multimedia experience, including multiple monitors, HD-quality video and bi-directional audio/video for video conferences. Other features, such as templating, thin provisioning and desktop pooling, are also included. Red Hat Enterprise Virtualization for Desktops supports Microsoft Windows XP, Windows 7 and Red Hat Enterprise Linux Desktop.
With the 2.2 release, Red Hat Enterprise Virtualization also features industry-leading scalability, supporting guests with up to 16 virtual CPUs and 256 gigabytes of memory per virtual machine. The release additionally provides new virtual machine conversion capabilities through a V2V tool designed to automate the conversion of VMware or Xen virtual machines for use within Red Hat Enterprise Virtualization. To further simplify moving virtual machine images between environments, Red Hat Enterprise Virtualization 2.2 also includes the ability to import and export virtual machine images and templates with the Open Virtualization Format (OVF).
"With today's announcement of Red Hat Enterprise Virtualization 2.2, customers can utilize the Cisco Unified Computing System and the Virtual Interface Card to drive virtualization efficiency through Cisco's extended memory and I/O virtualization technology," said Ed Bugnion, vice president and chief technology officer for Cisco's Server Access & Virtualization Business Unit. "We look forward to continued collaboration with Red Hat to offer our customers more choices, allowing them to take advantage of virtualization in their datacenter infrastructures."
"This release of Red Hat Enterprise Virtualization is a major milestone toward establishing KVM as a world-class open source hypervisor," said Bob Sutor, vice-president of Linux and Open Source at IBM.
Red Hat Enterprise Virtualization 2.2 is globally available today. To learn more about Red Hat Enterprise Virtualization, visit http://www.redhat.com/rhev.
openSUSE 11.3 is OutThe openSUSE Project has announced the release of the openSUSE 11.3, with support for 32-bit and 64-bit systems. openSUSE 11.3 has new features and updates including SpiderOak to sync files across the Internet for free, Rosegarden for free editing audio files, improved indexing with Tracker, and updates to Mozilla Firefox, and Thunderbird.
Among these new features, openSUSE also provides support for netbooks and the Btrfs file system. Users can expect to see improved hardware support with the 2.6.34 Linux kernel and updated graphics drivers. And there is support for the next generation of interactive touchscreens like the HP TouchSmart.
openSUSE continues to deliver the popular KDE, GNOME and Xfce desktop environments, and now also provides the lightweight LXDE desktop environment. GNOME uses the 2.30.1 version and a preview of the upcoming GNOME 3.0. Or choose to use KDE SC 4.4.4.
The openSUSE community also announced the availability of openSUSE Edu: Linux for Education (or Li-f-e). Li-f-e is built on openSUSE 11.3 but also provides education and development resources for parents, students, teachers as well as IT admins running labs at educational institutions. It comes bundled educational software covering subjects such as IT, mathematics, chemistry, astronomy, electronics, etc.
The next release will be openSUSE 11.4 in March, 2011.
IBM Announces Open Beta Program AIX 7IBM has announced an open beta program for AIX 7, the company's open standards-based UNIX operating system. AIX 7 builds on the capabilities of previous releases of AIX and can use the energy management capabilities of the new POWER7 servers.
AIX 7 provides full binary compatibility for programs created on earlier versions of AIX including AIX 6, AIX 5, and 32-bit programs created on even earlier versions of AIX. This means that clients can protect previous investments in Power Systems by moving existing applications up to AIX 7 without having to recompile them. AIX 7 will also be supported on systems based on earlier generations of processors including POWER6, POWER5, and POWER4.
Many clients running prior generations of POWER hardware would like to consolidate on newer, more efficient POWER7 servers, but simply do not have the administrative resources to upgrade a large number of servers. AIX 7 introduces new technology to help simplify consolidation of these older workloads onto new systems. Clients can back up an existing AIX 5.2 environment and restore it inside of a Workload Partition on AIX 7, which can allow them to quickly take advantage of the advances in POWER technology.
Some of the key features of AIX 7 include:
* New support for very large workloads with up to 256 cores/1024
threads in a single AIX logical partition - four times greater than
that of AIX 6;
* Built-in clustering to simplify configuration and management of
multiple AIX systems for high availability;
* Simplified AIX configuration management for pools of AIX systems.
"The planned release of AIX 7 underscores the IBM commitment to continued UNIX innovation. ...Building on the success of AIX 6's open beta that helped hundreds of ISV's deliver certified applications at general availability, our AIX 7 open beta will help deliver smarter applications as well." said Jeff Howard, director of marketing for IBM Power Systems.
The beta program is open to all, and is designed to provide clients and independent software vendors (ISVs) with early access to the AIX 7 operating system. Clients and other interested parties can participate in the beta by visiting ibm.com/aix and following the links to the open beta Web page at http://www14.software.ibm.com/iwm/web/cc/earlyprograms/websphere/aix7ob/. The beta code is packaged as a DVD ISO image that beta participants can burn to physical media.
PC-BSD 8.1 ReleasedThe PC-BSD Team has released PC-BSD 8.1 (Hubble Edition) with KDE 4.4.5 Version 8.1 contains a number of enhancements and improvements. For a full list of changes, please refer to the changelog at http://www.pcbsd.org/content/view/163/content/view/170/11/.
Some of the notable changes are:
* KDE 4.4.5;
* Numerous fixes to the installation backend;
* Support for creating dedicated disk GPT partitioning;
* Improved ZFS support;
* Bugfixes to desktop tools / utilities.
Version 8.1 of PC-BSD is available for download from http://www.gotbsd.net.
Mozilla releases first Firefox 4 betaThe Mozilla development team has released the first beta for version 4.0 of the Firefox web browser. Changes include better HTML 5 support and UI improvements.
According to Firefox development director Mike Beltzner, this beta is aimed at providing "an early look at what's planned" for the browser update. Firefox 4 will be the next major release of Mozilla's popular open source browser and will include a number of improvements, updates and new features.
Firefox 4 Beta 1 is based on version 2.0 of the Gecko rendering platform - the Firefox 3.6 branch uses Gecko 1.9.2 - and features a new Add-ons Manager and extension management API, and a number of Windows only changes, such as a new default 'tabs on top' layout for Windows systems. Mac OS X and Linux systems will receive the new tabs on top layout in a future update "when the theme has been modified to support the change". Other Windows improvements include a new Firefox Button on Vista and Windows 7 systems, replacing the menu bar, and an experimental Direct2D rendering back end - currently disabled by default.
Other changes include API improvements for JS-ctypes, a new HTML5 parser, more responsive page rendering, support for additional HTML5 form controls and partial support for CSS Transitions. User interface (UI) updates include a new default Bookmarks Button that replaces the Bookmarks Toolbar and a new single button for stop and reload. Native support for the HD HTML5 WebM / VP8 video format and full support for WebGL - a JavaScript binding to OpenGL ES 2.0 with industry support from Google, Mozilla and Opera - (currently disabled by default) have also been added.
Originally introduced in Firefox 3.6.4, version 4.0 includes enhanced crash protection technology from the Mozilla Lorentz Project. This is aimed at bringing full process isolation to Firefox, separating web pages and plug-ins from the main browser by running them in their own processes. Crash protection is now supported on Windows, Mac OS X and Linux, and currently protects the browser against crashes in the Adobe Flash, Apple QuickTime or Microsoft Silverlight plug-ins.
Beltzner notes that the developers plan to release a new beta version "every two to three weeks". A first release candidate (RC) for Firefox 4 is currentlyscheduled to arrive in October of this year. A final release date, however, has yet to be confirmed.
Firefox 4.0 Beta 1 is available to download for Windows, Mac OS X and Linux. The latest stable release of Firefox is version 3.6.6 from the end of June.
Firefox binaries are released under the Mozilla Firefox End-User Software License Agreement and the source code is released under disjunctive tri-licensing that includes the Mozilla Public Licence, GPLv2 and LGPLv2.1.
Apache Announces Tomcat Version 7.0The Apache Software Foundation (ASF) announced Version 7.0 release of Apache Tomcat, the award winning Open Source Java Application Web server. One of the ASF's earliest projects, the Tomcat code base was first donated to the ASF in 1999; the first Apache release, v.3.0, was made later that year. Apache Tomcat 7 is the project's first major release since 2006, fully implementing the Java Servlet 3.0, JavaServer Pages (JSP) 2.2, and Expression Language (EL) 2.2 specifications for easier Web framework integration.
Tomcat 7 provides out-of-the-box support for development features that would otherwise be coded manually. Apache Tomcat is shepherded by dozens of volunteers who contribute updates to its code base; its day-to-day operations, including community development and product releases, are overseen by a Project Management Committee.
With more than 10 million downloads to date, Apache Tomcat powers a broad range of mission-critical Websites and applications across multiple industries and use cases, from Fortune 500 conglomerates to service providers to eCommerce systems.
"I am delighted to see this first release of Apache Tomcat 7. Tomcat has always been the most popular deployment platform for Spring-based applications and this new release adds some great production technology," says Rod Johnson, general manager of the SpringSource division of VMware. "Tomcat's small footprint and reliable execution make it the ideal choice for the runtime component of SpringSource's tc Server. These features are also proving particularly important as organizations move their workloads to the cloud."
Developers using Tomcat 7 will also benefit from improved memory leak detection and prevention and support for 'aliasing' directories into an application's URL space. All known bugs reported in previous versions of Tomcat have been fixed in v.7.0.
Tomcat versions 5.5.x and 6.0.x will continue to be supported, however, bug fixes or updates to possible security vulnerabilities in earlier versions may be slightly delayed.
Tomcat 7 is released under the Apache Software License v2.0. Downloads, documentation, and related resources are available at http://tomcat.apache.org/.
Suricata: Free intrusion detection & prevention engineThe Open Information Security Foundation(OISF) has released version 1.0 of its open source intrusion detection and prevention engine - Suricata. Unlike Snort, another popular open source network intrusion prevention and detection system, Suricata runs multi-threaded and offers a number of advanced configuration options.
This first stable release includes a number of improvements and new features over the previous development releases, such as support for DCERPC (Distributed Computing Environment / Remote Procedure Calls) over UDP and the tag keyword. Additionally, CUDA (for Compute Unified Device Architecture) issues were fixed and it's performance was improved.
The OISF is funded by several US agencies, such as the Department of Homeland Security's Directorate for Science and Technology HOST program (Homeland Open Security Technology) and various members of the OISF Consortium, including a number of specialist IT security companies.
Suricata 1.0 source is available to download from the foundation's web site and is licensed under version 2 of the GNU General Public License (GPLv2). The sourc courd can be used for Linux/FreeBSD/UNIX, Mac, and Windows platvorms.
For more info see: http://www.openinfosecfoundation.org/.
Apache Announces Cayenne Version 3.0Version 3.0 release of Apache Cayenne, an easy-to-use, Open Source Java framework for object relational mapping (ORM) and persistence services and caching, was released in July.
In development for nearly 10 years, and an Apache Top-Level Project since 2006, Apache Cayenne is designed for high-demand applications and Websites accessed by millions of users each day. Cayenne is used by the Law Library of Congress, the world's largest publicly-available legal index.
The Apache Cayenne Project Management Committee has released a new Technical Fact Sheet detailing the state of Cayenne, including dozens of technical features, release highlights, and the Project's future direction. The Cayenne v.3.0 Technical Fact Sheet is available at https://blogs.apache.org/foundation/entry/apache_cayenne_v_3_0.
| Share |
|
Talkback: Discuss this article with The Answer Gang
![[BIO]](../gx/authors/dokopnik.jpg)
Deividson was born in União da Vitória, PR, Brazil, on 14/04/1984. He became interested in computing when he was still a kid, and started to code when he was 12 years old. He is a graduate in Information Systems and is finishing his specialization in Networks and Web Development. He codes in several languages, including C/C++/C#, PHP, Visual Basic, Object Pascal and others.
Deividson works in Porto União's Town Hall as a Computer Technician, and specializes in Web and Desktop system development, and Database/Network Maintenance.
Howard Dyckoff is a long term IT professional with primary experience at
Fortune 100 and 200 firms. Before his IT career, he worked for Aviation
Week and Space Technology magazine and before that used to edit SkyCom, a
newsletter for astronomers and rocketeers. He hails from the Republic of
Brooklyn [and Polytechnic Institute] and now, after several trips to
Himalayan mountain tops, resides in the SF Bay Area with a large book
collection and several pet rocks.
Howard maintains the Technology-Events blog at
blogspot.com from which he contributes the Events listing for Linux
Gazette. Visit the blog to preview some of the next month's NewsBytes
Events.

A couple years ago, I had a chance to work with industrial MIPS-based VME boards. It was so unusual to see that the modern failure-proof world actually extends beyond x86-architecture. Those VME boards had a Linux distrubution running, so no special knowledge was required to log in, and perform a task. Being designed for industrial purposes, it would be irrational to buy it for home use - so when I heard about a Chinese hardware company named Lemote [1], which has MIPS-based products in its portfolio, my first thought was - "Those guys have what I need - MIPS netbooks. I want it here, by my side". That's how the story began.
If you're a reasonably literate user of GNU/Linux system, then your experience with any netbook should be quite smooth - just as it was for me. As a matter of fact, the Yeeloong netbook has Debian preinstalled, with repositories tuned to update the "lenny" release. My first step was to upgrade Debian to the latest packages available. It's generally nice to have the most recent applications, the important ones in my case being gcc and building tools.
Apple fans should know that to synchronize/copy files to an iPod or iPhone, an average user needs to have iTunes installed on a PC. It's ludicrous, but iTunes is only available for Mac OS/X and Windows - and the most ludicrous thing about iTunes is that it's compiled for x86 architecture only. No more PowerPC, only x86/x86_64. Should I even bother mentioning Linux and MIPS here?
I have an iPod Touch, second generation. A very handy device, with multi-touch and mobile Safari to surf the net via Wi-Fi. However, I faced a tough problem - how do I copy audio and video files onto it without Microsoft Windows and iTunes, i.e., directly from Linux? There is a solution, actually - you might be interested in doing a jail-break for your iPod, in order to install an SSH server and make a direct connection by means of SSHFS[2]
While writing about performing a jail-break is beyond the scope of this article, I can gladly tell you - it was scary, but at the end, I had a wonderful feeling - it works! And to cheer you up even more, there is no chance of turning your iPod into a brick. It's an absolutely amazing device in terms of recovery and hardware design.
Okay, back to basics. I managed to flash an updated, i.e. 'JB' firmware with an activated SSH server. Now, it was time to log into iPod's operating system. You can do it via Wi-Fi network, or alternatively, via USB-cable by means of the iTunnel [3] package. Let's see how it works in practice.
I grabbed the source code, and did a compilation. No external dependencies or additional libraries were required. Kudos to iTunnel and libiphone authors!
loongson@debian:~$ cd src/itunnel-0.0.9/ loongson@debian:~/src/itunnel-0.0.9$ make clean && make
I'm an unprivileged user at Yeeloong netbook, so I decided to use port 12022.
loongson@debian:~/src/itunnel-0.0.9$ ./itunnel 12022 get_iPhone() success - successfully got device server waiting for ssh connection on port 12022 server accepted connection, clientfd:5 client thread fd(5) running, server port 12022 , peer port 45964 tunnel now running. SSH to localhost port 12022 to get to iPhone. (use ssh -D to create SOCKS tunnel.) do Ctrl+C to quit the server (can take a few seconds).
Well, everything's ready to login to iPhoneOS. Let's get to it. Don't forget about default password though: every Apple device seems to have a built-in 'mobile' user with password set to 'alpine'.
loongson@debian:~/src/itunnel-0.0.9$ ssh -l mobile -p 12022 localhost mobile@localhost's password: localhost:~ mobile$ uname -a Darwin localhost 9.4.1 Darwin Kernel Version 9.4.1: Mon Dec 8 21:02:57 PST 2008; root:xnu-1228.7.37~4/RELEASE_ARM_S5L8720X iPod2,1 arm N72AP Darwin
Quite the usual Linux environment, almost all user-space utilities have been ported from the bigger PCs:
uptime...
localhost:~ mobile$ uptime 23:14pm up 17 days 22:28, 1 user, load average: 0.10, 0.11, 0.08
df...
localhost:~ mobile$ df -h Filesystem Size Used Avail Use% Mounted on /dev/disk0s1 750M 475M 268M 64% / devfs 17K 17K 0 100% /dev /dev/disk0s2 15G 15G 250M 99% /private/var
top, and many others...
Processes: 23 total, 1 running, 22 sleeping... 81 threads
Load Avg: 0.05, 0.09, 0.08 CPU usage: 3.70% user, 5.56% sys, 90.74% idle
SharedLibs: num = 0, resident = 0 code, 0 data, 0 linkedit.
MemRegions: num = 3000, resident = 40M + 0 private, 32M shared.
PhysMem: 26M wired, 16M active, 8448K inactive, 114M used, 1704K free.
VM: 583M + 0 251397(0) pageins, 2080(0) pageouts
PID COMMAND %CPU TIME #TH #PRTS #MREGS RPRVT RSHRD RSIZE VSIZE
1599 top 7.4% 0:00.62 1 17 50 580K 848K 1348K 12M
1592 bash 0.0% 0:00.12 1 13 42 340K 480K 1120K 13M
1591 sshd 0.0% 0:00.50 1 14 37 368K 260K 1324K 13M
1583 ptpd 0.0% 0:00.30 2 48 75 544K 1472K 1372K 14M
1540 MobileSafa 0.0% 1:31.78 5 170 428 15832K 17M 37M 97M
43 locationd 0.0% 0:56.46 9 100 141 1272K 1908K 1908K 29M
32 fairplayd 0.0% 0:00.28 1 31 64 512K 1372K 512K 15M
31 iapd 0.0% 0:40.24 9 116 156 1248K 2760K 1568K 30M
30 mediaserve 0.0% 31:38.90 9 153 245 1820K 1944K 2292K 39M
29 lockdownd 0.0% 0:03.25 3 62 99 876K 1792K 960K 26M
28 update 0.0% 0:15.56 1 13 41 216K 624K 228K 11M
26 sbsettings 0.0% 0:00.19 1 27 107 868K 2592K 856K 25M
25 Navizon 0.0% 0:11.34 1 38 162 1280K 2924K 1396K 26M
24 msd 0.0% 0:38.88 1 32 95 1192K 1656K 1240K 15M
23 mslocd 0.0% 0:26.59 1 32 97 632K 1880K 788K 23M
19 CommCenter 0.0% 0:04.97 4 83 90 848K 1764K 940K 25M
17 BTServer 0.0% 0:01.18 2 66 93 636K 1556K 668K 17M
16 SpringBoar 1.8% 59:16.65 13 325 689 9060K 17M 20M 86M
15 configd 0.0% 6:28.52 5 160 127 1020K 1580K 1488K 16M
14 syslogd 0.0% 1:17.33 4 37 35 320K 248K 444K 13M
13 notifyd 0.0% 0:35.43 2 247 27 232K 248K 260K 12M
12 mDNSRespon 0.0% 2:00.59 2 46 65 616K 1360K 912K 14M
1 launchd 0.0% 0:40.65 3 78 35 284K 248K 396K 12MOf course, switching to a higher level via the 'su' command allows you to see even more information. For instance, all the logging information about the Wi-Fi network iPod has managed to connect to is available through 'dmesg' output:
AppleBCM4325::setASSOCIATE() [configd]: lowerAuth = AUTHTYPE_OPEN, upperAuth = AUTHTYPE_NONE, key = CIPHER_NONE, flags = 0x2 AppleBCM4325 Joined BSS: BSSID = 00:14:d1:4b:e6:f7, adjRssi = 44, rssi = -46, rate = 54 (100%), channel = 1, encryption = 0x1, ap = 1, hidden = 0, directed = 0, failures = 0, age = 1, ssid = "my_net" AirPort: Link Up on en0
Having SSH server up and running on the iPod Touch gives us the ability to connect to it via SSHFS-connection. Let's mount iPod' storage now!
loongson@debian:~$ sudo sshfs -p 12022 -o allow_other mobile@localhost:/private/var /media/usb
mobile@localhost's password:
loongson@debian:~$ df
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/hda1 57685532 46146588 8608692 85% /
tmpfs 514464 0 514464 0% /lib/init/rw
udev 10240 3552 6688 35% /dev
tmpfs 514464 0 514464 0% /dev/shm
mobile@localhost:/private/var
15324954624 15062839296 262115328 99% /media/usb
Now, let's do some simple benchmarking - copy a single file from iPod Touch to a netbook's local filesystem:
loongson@debian:~$ rsync -v /media/usb/mobile/Media/mp3/Madonna/greatest_hits/106\ Crazy\ For\ You.mp3 . 106 Crazy For You.mp3 sent 5859015 bytes received 31 bytes 1065281.09 bytes/sec total size is 5858218 speedup is 1.00
About 1MiB/s - that's pretty fast.
And let's perform the backward operation, i.e. copy a single file from netbook to iPod:
loongson@debian:~$ rsync -v --progress ./wine-1.1.23.tar.bz2 /media/usb/mobile/Media/
wine-1.1.23.tar.bz2
11075584 71% 140.08kB/s 0:00:30Frustrating, isn't it? What reasonable explanation could there be? Well, I guess the bottleneck is that the performance of iPod's CPU - ARM processor clocked at 533 MHz could be too slow to handle encrypted SSH packets. What should I do? Simply login to iPod, and secure copy a necessary file from a host (i.e., Yeeloong) machine. Like this:
localhost:~ mobile$ scp [email protected]:/home/loongson/Kylie* . [email protected]'s password: Kylie Minogue - Je Ne Sais Pas Pourquoi.mp3 100% 5655KB 1.1MB/s 00:05
Voila - it works! The same bandwidth in both directions!
The approach of performing a jail-break first, and then attaching iPod's storage to PC via SSHFS is a long way to go for something so simple. But - and this is essential - Linux users have no other means of transferring files to the iPod, due to a) iTunes being available for Mac- and Windows-platforms only; b) iTunes being compiled against x86 CPU only (PowerPC/SPARC/MIPS/ARM Linux users should wave "bye-bye"!), and c) there being no means to log onto an iPod without the SSH server being pre-installed. On the other hand, once you have done so, you have a full control over your lovely iPod Touch.
[1]
http://www.lemote.com/en/products/
[2]
http://fuse.sourceforge.net/sshfs.html
[3]
http://www.cs.toronto.edu/~jingsu/itunnel/
| Share |
|
Talkback: Discuss this article with The Answer Gang
![[BIO]](../gx/authors/borisov.jpg)
Anton jumped into Linux world in 1997, when he first tried a tiny muLinux distribution, being run from a single floppy. Later on, Red Hat and Slackware became his favorite choice. Nowdays, Anton designs Linux-oriented applications and middleware, and prefers to work with hardware labeled as "Powered by Linux".
Almost 1200 people attended this year's Semantic Technology Conference (SemTech 2010) in San Franciso. That was a big jump from last year and probably due in equal parts to the move to San Francisco and also the growing use of SemTech all over the web. Remember, this is a recession year.
Where do we find RDF and SemTech? The US government and maybe European governments. Semantic annotations are being added to many public databases. Also, the latest HTML5 draft has RDFa support in it. And who uses Semantic Technology now on the Web? The BBC, Newsweek, the NY Times and even companies like Best Buy have everyday applications running on SemTech. In short, Semantic Technology is everywhere. (Visit the earlier Away Mission that describes the basics of the Semantic Web here.)
The event bills itself as the world's largest conference on semantic technologies. It is also focused on the commercial aspects of developing semantic technologies and incorporating these into social, business and government processes.
One new aspect of the conference, which showed the pervasiveness of Semantic Technology, was the large number of vertical industry tracks. There were tracks for Open Government, Enterprise Data Management, Health-care and Life Sciences, SOA Governance, Publishing, Advertising and Marketing, and Semantic Web Technologies.
The other interesting trend was the focus on automated metadata extraction and the automation of ontology and taxonomy building. This was reflected on the expo floor and in the number of presentations discussing this new level of automation.
While there were few vendors - many of last year's vendors had been snapped up as divisions of larger companies - the offerings were richer and more mature. This was echoed in the conference by the frequent discussions of monetization and business models. I'll address that in a few paragraphs.
SemTech 2010 ran Monday through Friday, with intro sessions Monday evening and tutorials all day Tuesday. The Friday tracks changed a bit from primarily vendor-sponsored user sessions of previous years. For one example, there was a hands-on tutorial on Drupal 7 and RDFa open to any conference attendee. The slides from that session are on SlideShare at http://www.slideshare.net/scorlosquet/how-to-build-linked-data-sites-with-drupal-7-and-rdfa
Drupal is a widely-used open source platform for publishing and managing content. Version 7 is almost released and it will use RDFa for storing site and content metadata. Drupal 7 will have RDFa enabled by default for metadata on all nodes and comments. The key point here is the increasing commonality of RDFa functionality in new websites and site building tools. That emerging ubiquity will build the Semantic Web of meaning that Tim Berners-Lee spoke about almost a decade ago.
Just in the last few months, a new working group was formed for RDFa at the W3C with the goal of defining additional structure in HTML files for additional metadata. The group is working on linking RDFa into HTML5 and XHTML5 as well as the Open Document format used by OpenOffice. As an international example, the UK's e-government effort plans to use RDFa throughout its web pages. This allows the data to be read within a context and used with that context preserved.
The Open Graph used within the FaceBook web site is a simplified form of RDFa and the adoption of Open Graph by other social web sites allows RDF-based sharing of semantic information. For more info in Open Graph, check out this presentation on SlideShare, which is similar to one made at SemTech 2010:
I should mention here that several of the technical presentations from SemTech 2010 and 2009 are on SlideShare and can be searched for with the string "semtech" to find them.
A few weeks before this year's SemTech, Apple purchased SIRI, one of the bright stars from SemTech 2009. SIRI's intelligent semantic agent for desktops and mobile devices, which mixed location-based services, mashups, and voice recognition with an inference engine, was a hit with the SemTech crowd and I had been looking forward to a forward looking progress report.
From the Semantic Universe review of the SIRI sale: "SIRI was in the vanguard of leveraging the AI-based apps and applications that relate to the semantic web developed by SRI" and "one of the core and most innovative technologies coming out of SRI - which led the 'CALO: Cognitive Assistant That Learns and Organizes' DARPA project. Maybe what's most important about SRI and CALO's Active Ontologies innovation... was to create passive inferencing that... lets one reach conclusions and drive to actions based on those conclusions." More Semantic Universe reviews of the SIRI sale can be found here: http://www.semanticweb.com/on/apple_buys_siri_once_again_the_back_story_is_about_semantic_web_159896.asp
Catch the SIRI video embedded there - or go directly to http://www.youtube.com/watch?v=MpjpVAB06O4.
Of course, just after this year's SemTech event, Google bought Metaweb, the force behind the important FreeBase global semantic data store. On the company blog, Google wrote: "Working together, we want to improve searching and make the web richer and more meaningful for everyone."
They also wrote: "Google and Metaweb plan to maintain Freebase as a free and open database for the world. Better yet, we plan to contribute to and further develop Freebase and would be delighted if other web companies use and contribute to the data. We believe that by improving Freebase, it will be a tremendous resource to make the web richer for everyone. And to the extent the web becomes a better place, this is good for webmasters and good for users."
One immediate benefit of the acquisition, Metaweb has increased the frequency of Freebase down-loadable database dumps from quarterly to weekly.
You can visit the YouTube intro to MetaWeb: http://www.youtube.com/watch?v=TJfrNo3Z-DU&feature=youtu.be
And, for more detail, view the "Introducing Freebase Acre 1.0" video: http://www.youtube.com/watch?v=dF-yMfRCkJc
The FreeBase presentation was one of the best at the free Semantic Code Camp held one evening during SemTech 2010. Delivered by Jamie Taylor, the Minister of Information at Metaweb Technologies, it describe the project that has over 12 million topics which can be queried by SPARQL and other semantic protocols. It gets the information from Wikipedia, the government, SFMOMA, MusicBranz, and other sites providing semantic data. It acts as a Rosetta Stone between identifiers in different systems such as Netflix, Hulu, Fandango, etc. with 99% accuracy. All this runs on a Creative Commons license.
You can find that FreeBase presentation here: http://www.slideshare.net/jamietaylor/sem-tech-2010-code-camp
Other Code Camp presenters included Andraz Tori from Zemanta, which can read in most text from many domains and give back standard tags and categories, Wen Ruan of Textwise, which uses faceted search to find and use subsets of a data collection, and Tom Tague of OpenCalais, a project of Thomson Reuters, which can categorize and tag the people, places, companies, facts, and events in content.
The Code Camp was a beginner's track on how to use Semantic Technology and an open Unconference track. A nice aspect was that anyone registering through the Silicon Valley Semantic Technology Meetup could attend for free and also get an expo pass to SemTech and share in the preceding reception and free margaritas.
Google announced "Rich Snippets" just over a year ago in May 2009. Today, if webmasters add structured data markup to their web pages, Google can use that data to show better search result descriptions. This is not fully implemented yet, but extra snippets are being captured and are showing up in Google search results. One example of this is the RDFa used in the display of Google video selection results or receipes that display calories and prep time on ther first line.
Kavi Goel and Pravir Gupta of Google described the simple markup vocabulary used by Google for enhanced indexing. Currently, this can be in a micro format or RDFa. They explained that they will add to the vocabulary as more domains are added to the Rich Snippets ontology. They will also be expanding the vocabulary to include over 40 different languages, and will use the FaceBook Social Graph to link friends and locations.
They have just released a testing tool for webmasters and content developers. One reason for this: most web sites were not doing the snippet markup correctly. The tool will show which elements are visible and what properties are listed. If nothing shows at all, then the site is not using snippets correctly.
Among the more common mistakes are the use of hidden text and markup in-line, as Google search ignores this. Alternatively, the person doing the markup needs to be very clear in terminology. They cited ambiguities like differences in ratings versus reviews or votes versus counts. They expect these to be cleared up with practice. They also mentioned that global use of snippets was growing at 4x the US rate from 10/09 to 06/10.
The session on Building Web 3.0 Web Sites discussed best practices in implementing SEO, RDFa and semantic content for Web 3.0 sites.
The presenters - John Walker, Mark Birbeck, and Mark Windholtz - discussed how to transform current content into semantically-rich web pages. They emphasized the need to improve and maintain data quality, both for the main content and for the tags and metadata that will enhance access and combination. In addition they recommended the following:
If working within a company, try to break down application silos and free the data. They suggested making data accessible by having triple stores run 'on top' of existing databases. It's much less expensive to do this and needs less effort to start. Finally, it may be easier for IT departments to accept semantic extensions when the underlying data resides in traditional databases maintained by the usual staff.
Several presentations focused on the emerging techniques for dynamically extracting meaning and metadata and mapping text information into taxonomies and ontologies. These include combinations of statistical and rules-based metadata extraction and auto-tagging and auto-classification to link related content.
Some of this is being facilitated by running semantic projects that are building standard vocabularies and standard ontologies. Examples of this are TextWise and FreeBase, as well efforts now taking place in industry verticals.
One presentation with a huge title was The Use of Semantic Analytics to Achieve Data Transparency Using Government Standards for Information Sharing, by Bill Stewart of Jeskell. Stewart noted that almost half the work week of a knowledge worker is spend finding needed information -- 19 hours a week! Globally, we are collecting 15 petabytes every day and 80% of new data is unstructured. For the demo in his session, he showed the Languageware Workbench finding work roles from text information on the Katrina recovery effort and distilling out an entity list of working teams. The rule set had been built over a two day period parsing the text record.
In Assistive and Automatic Tools for Tagging and Categorizing Anything, Seth Maislin did a survey of automation techniques. Although the goal is to save costs by getting human intervention out of loop, Maislin pointed that domain expert intervention may be needed to review auto-indices and auto-built ontologies. Maislin suggested doing this toward the beginning of a project to build trustworthy associations. Building the index, with or without the aid of a taxonomy, is the place for human involvement. In MedLine, humans assist categorization by accepting or declining initial results, then reviewing and correcting by experts, added by active social tagging by users. He also recommended using open source taxonomies to start and extend your own.
Another example of the pervasiveness of SemTech is the Nepomuk project which provides a standardized, conceptual framework for Semantic Desktops. Part of the new tech in KDE SC 4, Nepomuk shares data from several desktop applications using RDF metadata. There are C/C++ and Java implementations.
Core development results will be publicly available during the project via a webbased collaboration platform. The most prominent implementation is available at http://nepomuk.kde.org.
Contributors to the project were in various expo booths, including the folks from DERI.
Here's part of the Goal statement from the Nepomuk project website:
"NEPOMUK intends to realize and deploy a comprehensive solution - methods,
data structures, and a set of tools - for extending the personal computer
into a collaborative environment, which improves the state of art in online
collaboration and personal data management...."
http://nepomuk.semanticdesktop.org/xwiki/bin/view/Main1/Project+Objectives
Although initially designed to fulfill requirements for the NEPOMUK project, these ontologies are useful for the semantic web community in general. These basically extends the search process with a local desktop RDF store and links data from various applications that use these KDE ontologies. The ontologies are open source and are used by Tracker in GNOME.
The NEPOMUK ontologies are available from the following Web page:
http://www.semanticdesktop.org/ontologies/
In the last 2 years, the event organizer, Wilshire Conferences, has organized SemTech and the related Enterprise Data World event with a 'lunch on your own' policy except for the tutorial day. That, and the conference tote bag, makes it a bit less expensive. All attendees got an early conference CD but conference web site hosts password access to updated presentations. By the way, that single lunch on the tutorial day was great! The Hilton kitchen staff produced tasty and eye-pleasing food. And the move from San Jose to the SF Hilton resulted in a better facility overall - an excellent AV team kept all the rooms functional and all but one room had a net of extension cords to power attendee laptops.
I have to say I found SemTech sessions more satisfying and less academic this year and more about real tools and products. I'm happy that they plan to return the SF Hilton in 2011 hope to attend.
| Share |
|
Talkback: Discuss this article with The Answer Gang
Howard Dyckoff is a long term IT professional with primary experience at
Fortune 100 and 200 firms. Before his IT career, he worked for Aviation
Week and Space Technology magazine and before that used to edit SkyCom, a
newsletter for astronomers and rocketeers. He hails from the Republic of
Brooklyn [and Polytechnic Institute] and now, after several trips to
Himalayan mountain tops, resides in the SF Bay Area with a large book
collection and several pet rocks.
Howard maintains the Technology-Events blog at
blogspot.com from which he contributes the Events listing for Linux
Gazette. Visit the blog to preview some of the next month's NewsBytes
Events.
In a previous article, Tunnel Tales 1 I described how to use SSH tunnels and a third machine to provide network access from one machine to a second machine which was otherwise not directly accessible. Today's scenario is quite different.
We want convenient access to a machine which can only be reached by navigating a chain of intermediate machines.
Whereas the earlier task could be accomplished with a single command, the current task is far more formidable and requires more powerful magic.
This article will assume that you are very familiar with SSH. I will not repeat points I made in the earlier article.
Keywords: SSH tunnels, expect
Networks come in all shapes and sizes. I'm sure that the original network was designed. I guess that, over time, a machine was added here, another was removed there - much like a well loved suit might be modified as its owner ages and changes shape.
By the time I arrived, the network was looking quite convoluted. It was easy enough to get to the newer machines. But some of the legacy machines required some serious tap-dancing before they could be reached.

target the machine I need to work on jump1 an intermediate machine jump2 another intermediate machine laptop my laptop
If I only needed to get to the target machine once or twice, I would just ssh from my laptop to jump1; then again from there to jump2; and finally from there to the target machine.
But I knew that I would be visiting target many times over the next week or two. And further, and more interestingly, I would need to transfer files between my laptop and the target machine.
Again, for transferring files, most people would suggest in exasperation to just transfer them from one machine to the next until they reached the required destination.
I invoke the following command on my laptop:
ssh -L 9922:localhost:9822 jump1
The command says to establish an SSH connection to jump1. "While you're at it, I want you to listen on a port numbered 9922 on localhost (ie the laptop). If someone makes a connection to that port, connect the call through to port 9822 on jump1."
Why 9922? The port number is arbitrary, but I use the form XX22 to remind me that this relates to SSH.
Why 9822? It seems that this port number is as arbitrary as 9922, but that's not entirely true. We'll examine this a little later.
So far we have not achieved much.
ssh -L 9822:localhost:9722 jump2
You should be able to work out what this command does. Of course this time, localhost means jump1.
The port number on the left (in this case 9822) must be the same as the one on the right for the preceding command.
Before I explain more, I'll just add one more command.
By now, the last step should be obvious. (It isn't. There's one final wrinkle.) To make the subsequent analysis easier to follow, I'll list all three commands and then discuss.
ssh -L 9922:localhost:9822 jump1 ssh -L 9822:localhost:9722 jump2 ssh -L 9722:localhost:22 target

The three commands get me to the target machine, where I can do whatever work I need to do. That's one effect. The side-effect is more interesting.
Quite often, when I visit a machine, I like to run several sessions, not just a single session. To start a second session, I could use a similar set of ssh commands (with or without the -L option). Or, on my laptop, I could just go:
ssh -p 9922 localhost
The reference to port 9922 on localhost connects me to port 9822 on jump1, which automatically on-connects me to port 9722 on jump2, which automatically on-connects me to port 22 on jump2.
The individual tunnels combine to provide me with a "super-tunnel".
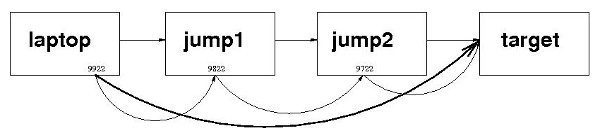
It should now be clear that the ssh command that gets you to the target (the last machine), must have 22 as the port number on the right of localhost in the -L option. All the previous ssh commands are creating "stepping-stones". The last ssh command must take you to the real port on which the SSH daemon listens (usually 22).
As in the earlier article, the arrows in the diagram are significant: the tunnels are unidirectional for invocation. In other words, I can use the tunnel to get to the target from my laptop; but I can't use this tunnel to get to my laptop from the target. (I'd have to do something different if that's what I wanted. I'll leave that as an exercise for the reader.)
That's not really very restrictive. After all, I'm doing all this work while I'm sitting at my laptop, using its keyboard, mouse and screen.
The last point may help clarify the difference between -L (local) and -R (remote). The tunnel can be described as having a "mouth" at one end - the end where it is entered. (I may have chosen an unfortunate metaphor. Let's not concern ourselves with the other end!) On the diagrams, the arrowheads represent the other end of each tunnel.
Thus the previous article used -R because the mouth of the tunnel was on a remote machine (remote relative to the machine on which the ssh command was issued); whereas this article uses -L because, in each case, the mouth of the tunnel is on the local machine (the machine on which the ssh command is issued).
Arguably of even more value than being able to ssh to the remote machine in a single command is the ability to scp (or rsync) to and from the remote machine in a single command.
Use commands of the following form:
scp -p -o 'port 9922' /path/to/single.file localhost:/tmp scp -p -o 'port 9922' localhost:/path/to/single.file /tmp RSYNC_RSH="ssh -o 'NoHostAuthenticationForLocalhost yes' \ -o 'UserKnownHostsFile /dev/null' -p 9922" export RSYNC_RSH rsync -urlptog /path/to/top_dir localhost:/tmp
Bear in mind that the copies occur between the laptop and the target machine in a single command not a single step. We haven't found a magical way to bypass the intermediate machines. Under the covers, the data goes from each machine to the adjacent machine in the tunnel. We have only saved typing. But that's still hugely valuable.
Did anyone wonder why I kept using different port numbers?
Why did I not do this:
ssh -L 9922:localhost:9922 jump1If you were going to ask this question, well spotted.
The way I have drawn the diagrams, and the way the problem originally presented, it would have been perfectly reasonable to have all the 9X22 be the same. (The 22 would still have to be 22.)
Because, of course, each ssh command is being issued on a different machine, and ports only have to be unique on a single machine (strictly, interface of a machine). [And that last little parenthetic addition just taught me something. More later.]
It turns out that when I was attempting to solve the problem, I was no longer at work. I was at home where I did not happen to have 3 spare machines available to simulate the conditions of the scenario.
Undaunted, I began to work through the problem by repeatedly connecting back to my own machine. But this took away the premise of an earlier paragraph: I was no longer issuing each ssh command on a different machine. And so I had to use different port numbers.
It does not hurt to use different port numbers; arguably, it makes the solution more general. On the other hand there is a risk of running out of port numbers if the chain gets ridiculously long.
It is important that the port number to the left of each localhost (except the first) be the same as the port number to the right of the previous localhost. So that's an argument to keep it simple and only use one port number all the way through (except for the final 22).
That's all you need to improve your life substantially when you encounter a similar scenario.
What's that? You think that there is still too much typing? You want more?
Oh, all right.
Here's a fairly long expect script:
#!/usr/local/bin/expect -f
# ssh_tunnel.exp - ssh to a remote machine via intermediate machines
set timeout -1
set HOSTS [list jump1 jump2 target]
set PORTS [list 9922 9822 9722 9622 9522 9422 9322 9122 9022]
# The port of the last machine must be 22
set jj [llength $HOSTS]
lset PORTS $jj 22
set i 0
foreach HOST $HOSTS {
puts "HOST= $HOST PORT= [lindex $PORTS $i]"
set i [expr {$i + 1}]
}
send_user "\n"
#----------------------------------------------------------------------#
# Procedure to get to a machine
#----------------------------------------------------------------------#
proc gotomachine {lport rport host} {
send_user "Getting on to machine $host ... "
send -- "ssh -L $lport:localhost:$rport $host\r"
log_user 0
expect -exact "Starting .bash_profile"
expect -exact "Finished .bash_profile"
expect -exact "-bash"
send -- "env | grep SSH_CONNECTION\r"
log_user 1
send_user "done.\n"
}
#----------------------------------------------------------------------#
match_max 100000
set dollar "$"
spawn bash
log_user 0
expect -exact "-bash"
send -- "unset HISTFILE\r"
expect -exact "-bash"
send -- "unset ignoreeof\r"
expect -exact "-bash"
send -- "PS1='\nYou need one more exit to get back "
send -- "to where you started\nUse ^D. $ '\n"
expect -exact "started"
log_user 1
set i 0
foreach HOST $HOSTS {
set lport [lindex $PORTS $i]
set i [expr {$i + 1}]
gotomachine $lport [lindex $PORTS $i] $HOST
}
puts "
Houston, this is Tranquility Base. The eagle has landed.
You should now be able to get to this machine ($HOST) directly
using:
ssh -p [lindex $PORTS 0] localhost
To disconnect the tunnel, use the following repeatedly:
"
puts { [ "$SSH_CONNECTION" = '' ] || exit }
puts "
Good luck!
"
interact
exit
When I developed the solution on my machine I was under the misapprehension that I had no choice but to use different port numbers. As I wrote this article, I said that ports only have to be unique on a single machine - and then corrected myself and said they only have to be unique on a single interface.
This opens the possibility of a simplification of the script ssh_tunnel.exp - at the expense of setting up some virtual interfaces on my single machine. If I were doing this from scratch now, that's what I would do.
It gets very confusing constantly connecting back to a single machine. That accounts for the large number of lines dealing with disconnecting the tunnel. I was scared I would exit too often and blow my xterm away.
This is a nice safe use of expect. As usual, I've set up certificates on all relevant machines, so no paswords are necessary.
You should now have the tools to navigate conveniently across any chain of machines.
Read with the previous article, this article should have given you enough information to handle the earlier scenario without "cheating".
You should be able to extrapolate from these articles to almost any configuration of machines.
| Share |
|
Talkback: Discuss this article with The Answer Gang
![[BIO]](../gx/authors/grebler.jpg)
Henry has spent his days working with computers, mostly for computer manufacturers or software developers. His early computer experience includes relics such as punch cards, paper tape and mag tape. It is his darkest secret that he has been paid to do the sorts of things he would have paid money to be allowed to do. Just don't tell any of his employers.
He has used Linux as his personal home desktop since the family got its first PC in 1996. Back then, when the family shared the one PC, it was a dual-boot Windows/Slackware setup. Now that each member has his/her own computer, Henry somehow survives in a purely Linux world.
He lives in a suburb of Melbourne, Australia.
Something most new Linux users often struggle to understand is the concept of desktop environments. What a desktop environment actually is, I feel, gets further clouded when users start exploring different "spins" of a distro (short for distribution). For example, it is very common for a new user to think that Kubuntu or Xubuntu is something entirely different from the well known Ubuntu. Many do not know that they can easily install any *buntu on any other *buntu with a single command![1]
Just as choosing the distro can be difficult, so can choosing the "right" desktop environment. The following is an overview of some of the best known desktop environments so you can be more informed in your decision.
Gnome: The most popular desktop environment currently in use is Gnome - it is the desktop environment that powers the three most popular Linux desktop distros (Ubuntu, Fedora, and Linux Mint). Gnome is a fully developed desktop environment that provides a fully integrated application set. It is easy to use and provides GUI tools for making edits to all the different features that are available within it. It is a very "user friendly" desktop environment that is fantastic for new users.
 Gnome's memory footprint is modest for all the features it provides. A default
Gnome install uses around 180megs (Mb) of RAM. If you like eye candy on your
computer, odds are you will want to run Compiz (desktop effects) on
your Gnome desktop. A default Gnome install with Compiz running uses
slightly more memory, right about 205megs.
Gnome's memory footprint is modest for all the features it provides. A default
Gnome install uses around 180megs (Mb) of RAM. If you like eye candy on your
computer, odds are you will want to run Compiz (desktop effects) on
your Gnome desktop. A default Gnome install with Compiz running uses
slightly more memory, right about 205megs.
KDE: In terms of popularity, KDE is the second most popular desktop environment. Like Gnome, it is fully mature and provides its own full application set as well as GUI tools for configuration. KDE also has a wide selection of "plasma widgets", which are handy applets you can place all around your desktop for all sorts of tasks. They range from something as practical as a calculator to ones as useless as a display from "The Matrix".
 Overall,
KDE is much more customizable than Gnome, but this comes at a cost - a
default KDE install uses around 510megs of RAM. However, if you are looking for eye
candy, it does not cost as much to run KWin (KDE's built in desktop effects)
as it does to run Compiz: with KWin enabled, a default KDE install uses
around 520megs of RAM.
Overall,
KDE is much more customizable than Gnome, but this comes at a cost - a
default KDE install uses around 510megs of RAM. However, if you are looking for eye
candy, it does not cost as much to run KWin (KDE's built in desktop effects)
as it does to run Compiz: with KWin enabled, a default KDE install uses
around 520megs of RAM.
XFCE: XFCE is designed to be simplistic and quick. It does not provide much in the way of eye candy (although you can run Compiz on it), but it is a decently fast/responsive desktop environment. While XFCE does have some of its own applications, such as its file manager Thunar and the XFCE system monitor, it does still borrow some applications from the Gnome environment (such as the nm-applet network manager). Don't think XFCE is an immature project though: what it borrows from Gnome is more to save itself from reinventing the wheel than from a lack of ability. XFCE does not have quite as many tools for making GUI edits as Gnome or KDE, but it does have a fairly good configuration panel.
 Designed to be quick and lightweight, XFCE leaves a low memory footprint on
the system you have it running on. In its default state, XFCE uses around 140megs of
RAM.
Designed to be quick and lightweight, XFCE leaves a low memory footprint on
the system you have it running on. In its default state, XFCE uses around 140megs of
RAM.
LXDE: LXDE is a newer project in the world of Linux desktop environments. Similar to XFCE, LXDE's goal is to provide a fast, lightweight desktop environment with little resource usage. LXDE has a few of its own applications, but those applications it still lacks it borrows from Gnome and XFCE. The age of the LXDE project really shows when you start to look into making customizations to things. Many adjusts have to still be made by manually editing configuration files - not a bad thing if you know your system well (or are willing to learn it), but this can be a giant setback for a beginner who wants things to "just work".
 LXDE may be a much younger project than XFCE, but it does a fantastic job
of resource conservation. A fresh install of LXDE uses 100megs of RAM, the
lowest of all the desktop environments I am reviewing today.
LXDE may be a much younger project than XFCE, but it does a fantastic job
of resource conservation. A fresh install of LXDE uses 100megs of RAM, the
lowest of all the desktop environments I am reviewing today.
E17: I cannot do an overview of Linux desktop environments without mentioning E17. E17 is designed to be a lightweight, but elegant desktop environment. It is very successful at both of these tasks. E17 uses all of its own libraries, that have been built from the ground up for speed and flexibility. E17 is a tinkerers delight, you can customize and change anything and everything.
 A base install of E17 leaves a memory footprint of around 110megs of RAM. Now,
while a base install is functional, half the fun of E17 is in playing with
widgets, changing transitions, and generally toggling everything you can
just to see how shiny you can make your desktop. After I had my E17 fully
configured, its memory footprint was increased to a whopping 120megs of
RAM.
A base install of E17 leaves a memory footprint of around 110megs of RAM. Now,
while a base install is functional, half the fun of E17 is in playing with
widgets, changing transitions, and generally toggling everything you can
just to see how shiny you can make your desktop. After I had my E17 fully
configured, its memory footprint was increased to a whopping 120megs of
RAM.
A few of you may be wondering if E17 is so lightweight, flexible, and flashy, why don't more distros opt to use it for their desktop environment? There are two reasons for this. First and foremost is the fact that E17 is very much "beta" software. Compiling the latest version from source at any given point can have piles of crashes/segfaults that can make using it a giant headache. Second, if you do take the time to piece together a stable E17 build (check out Elive for the best E17 distro around), the desktop environment takes some getting used to. For many, it will feel foreign whether they are used to using another Linux desktop environment or a Windows machine.
Final Thoughts: All of the various desktop environments have their advantages and their disadvantages. Which one is right for you largely depends on your task at hand. Personally I run LXDE on my netbook, KDE on my gaming laptop, and Gnome on my home media center. If you are not sure which is best for you, try them out! It is all free software after all - get a feel for which desktop environment you are most comfortable on and use that one.
Is there another desktop environment that you enjoy using that I failed to mention here? If so, let me know, I am always looking to tinker with new things.
The commands that allow you to install one version on another are:
sudo apt-get install ubuntu-desktop sudo apt-get install kubuntu-desktop sudo apt-get install xubuntu-desktop sudo apt-get install lubuntu-desktop etc.
You could also simply install the DE with the appropriate meta-package, e.g.:
sudo apt-get install kde sudo apt-get install lxde
| Share |
|
Talkback: Discuss this article with The Answer Gang
![[BIO]](../gx/authors/hoogland.jpg)
I am currently a full time student working my way through a math education program on the south side of Chicago. I work in both theatre & computer fields currently. I am a huge believer in Linux and believe we will see Microsoft's dominant market share on the personal computer crumble at some point in the next twenty years. I write a good deal about technology and you can always find my most current thoughts/reviews/ramblings at http://jeffhoogland.blogspot.com/
This procedure is for installing Windows Server 2003 over the network. However, I believe I've invented a new way of doing a network installation and wanted to share it with anyone who might find it useful. My quest to install Windows with a PXE/TFTP/DHCP system started after I tinkered around with the Unattended package and I found it lacking. Specifically, it's a giant hacky mess of Perl scripts, and it only handles 32 bit Windows installs. It essentially boots a DOS environment, creates a FAT32 partition, copies the Windows setup files, and then reboots and converts the partition to NTFS before finishing the install. It's a neat way of bootstrapping Windows from a Linux environment, but when I found out that MEMDISK can boot an ISO, I had the crazy idea of mapping an ISO image of the Windows setup CD as a RAMdisk and running the installation from there.
To make the MEMDISK-booted ISO -> RAMdisk -> Windows Setup chain work, we'll need to integrate a driver into the Windows setup image that will enable Windows to use the RAMdisk as an installation source. It's called winvblock, and it enables Windows to use a RAMdisk as a virtual block device.
To insert it into the CD, we'll need to manually modify /i386/txtsetup.sif, the configuration file for the text mode installation portion of Windows setup. The file is divided into separate sections with lists of definitions in the following format:
[Header] definition 1 definition 2
So, to integrate the driver add the following lines in the appropriate sections:
[SourceDisksFiles] wvblk32.sys = 1,,,,,,4_,4,1,,,1,4 [SCSI.Load] wvblk32 = wvblk32.sys,4 [SCSI] wvblk32 = "WinVBlock RAMdisk driver"
Next, you need to compress the driver; unzip the driver pack and run the following command at a Windows command prompt:
makecab WVBlk32.sys WVBLK32.SY_
Take the compressed driver and place it into the /i386 directory on the setup disk. Note that these instructions are for a 32 bit install image, however the 64 bit process is exactly the same, except for replacing "32" with "64" and placing the driver/modifying txtsetup.sif in the /amd64 directory.
These modifications will allow Windows setup to install from the RAMdisk. Now, there is one more caveat to deal with; this is the reboot after the text mode setup when Windows boots off the local disk that has been pre-populated with some installation files and a bootloader. Rebooting the machine will drop the RAMdisk from memory, and we need it re-mapped to finish the process. Dealing with this quirk is done by manipulating a bootloader hack that resides on the Windows setup CD. The binary /i386/BOOTFIX.BIN is the guy responsible for that annoying message that says "press any key to boot from CD" with a time-out. If the file is present on the disk, the message will appear. If it is removed, there is no prompt and the CD boots immediately with no way to stop that.
There are 2 ways to handle this final quirk I've found. I'm lazy, and don't like waiting around to press a key when the machine has to boot from the CD in the first phase of setup. So I created an ISO without BOOTFIX.BIN and called it "Stage 1". I then created a second ISO with BOOTFIX.BIN and called it "Stage 2". On Stage 2 of the setup, you simply load the ISO from the PXE server and let the prompt time-out, so the machine defaults to booting from the local hard disk with the RAMdisk loaded into memory again.
At this point, the optional unattended answer file will take over and you can grab a coffee or make fun of the guy with the giant CD book as your net install finishes.
Finally, here are some sample entries for your PXE server (usually set up under /tftpboot/pxelinux.cfg/default):
label Windows 2003 Std x86 Text (stage 1) menu label ^Windows 2003 Std x86 Text (stage 1) kernel memdisk append raw iso initrd images/w2k3std_stage1.iso label Windows 2003 Std x86 Graphical (stage 2) menu label ^Windows 2003 Std x86 Graphical (stage 2) kernel memdisk append raw iso initrd images/w2k3std_stage2.iso
I hope that explains the process in enough detail to replicate the setup. I've successfully installed all the i386 and amd64 flavors of Windows 2003 with this setup and I think it's a neat hack. Especially so since it's done with all open-source tools from a Linux server. Take that, RIS/WDS!
| Share |
|
Talkback: Discuss this article with The Answer Gang

Will a system engineer working in the webhosting industry. He enjoys automating things in strange ways, or when that fails he installs Gentoo on it.
First, I want you to know that I am not an Apple hater. I've owned several Apple products over the years (since the Mac OS X era started), and I think they are great products (to be honest). Therefore, this is not an Apple hate-fest! My goal is not to make someone like or dislike one product or brand over another. My goal is simply to try to put in words why I've decided to try something else other the iPhone.
Second, I am an open source advocate, I work for an open source company, I write open source articles to open source publications. I believe in open source, not as some sort of religious belief or moral imperative but rather as an alternative, and I am a sucker for 'alternatives'.
An alternative way to do business, an alternative way to write code, an alternative way to learn, an alternative way to teach. I believe in open source.
With that said, this month I am going to share with you a little bit about my story of moving away from Apple's iPhone and starting to use a Linux based phone like the Palm Pre Plus.

The actual story:
I bought an iPhone 3G back in December 2008, mostly because my job wanted me to be on call for emergencies and they were going to take care of most of the bill. I don't talk on the phone that much and at the time I owned a Mac laptop, so I was very familiar with the eye candy Apple has excelled in presenting to their users. What I wasn't very used to was the idea of having Internet access anywhere I went.
I quickly became even more addicted than normal to the Internet. Waiting in lines or at the doctor's office was not an issue anymore because I could check my email, use Twitter or Facebook, and even get work done all through my phone. I am not going to debate with anyone if this constant access to the Internet is a good thing or not. I happen to believe that like most things in life it has its advantages and disadvantages.
Twelve months went by, and my iPhone became the one item in my life that I had within my reach virtually 24/7.
In December 2009, I decided to upgrade, this time using my own funds. I got the iPhone 3Gs, and was very pleased with the upgrades in memory, bump in storage and camera quality that Apple provided with the product.
So, what changed for me to want to change phones?
Well, it hasn't been one specific problem, but a collection of events. I started hearing Steve Jobs trash Adobe, and letting everyone know how 'open' Apple is. Really? Open?
I could probably write pages upon pages about the issues I have with Apple's 'open' practices: not allowing users to directly manipulate their music files on the iPhone/iPod, or banning other languages/IDEs from writing apps to the iPhone/iPod (I think I heard that was overturned, maybe not), selling music with DRM and then charging extra to free the music, putting out 'HTML5' sample pages that only work with their own browser, a phone that only works on 1 US provider, and God forbid if you try to 'hack' your way into getting the phone working the way you'd like, they will release updates just to break your 'hack'. That just doesn't sound that open to me.
[ Late-breaking news from this article's author: as of last week, it is legal to jailbreak your iPhone. Despite this, however, I agree with his original premise and believe that it still stands without any modification: Apple's practices cannot be accurately described as "open". -- Ben Okopnik ]
Then came the news that Apple's market value passed Microsoft's - which, honestly, doesn't make much sense to me. Microsoft is everywhere, not just everywhere here in the U.S., they are literally everywhere around the world with Windows (desktops and servers), Office, MS SQL, XBox, Visual Studio, Sharepoint - they even provide the ECUs for Formula 1! In comparison, where is Apple? Mostly concentrated in the US, in a few desktops and notebooks, quite a lot of phones and MP3 players, but does that make Apple worth more than Microsoft? I am not an economist, and I am sure there is an explanation to all of this, but when I look around with my 'binary' perspective of either 'on' or 'off', I don't get it. It's hard to believe that a company that was mostly bankrupt in 1998 has surpassed Microsoft.
Then in June of 2010, tech media outlets around the world were speculating about what Apple would release at the WWDC besides the iPhone 4, which a lot of us found out about from the drunk guy that left one in a bar 3 months or so ago. Well, the WWDC came, and Steve Jobs showed to the world why Apple has bypassed Microsoft: presentation.
Steve Jobs presented 2 full hours on the iPhone 4 (and iOS4) without introducing anything else new. The iPhone 4 is cool, don't get me wrong, and to be honest, there are other phones out there that are just as good or better than the iPhone 4 hardware-wise, but when you add the usability of iOS and the iPhone it becomes quite the compelling combination to the masses.
On June 15th, the day pre-orders opened for the iPhone 4, I was up at 6 AM, and pretty much tried all day to pre-order 2 iPhones, one for me and one for my wife, without much success.
What bothered me the most was that Apple made 'reserving' an iPhone a mostly pain free process, but I wanted to pre-order one so it would be delivered at my doorstep. I did not want to go stand in line to pick it up at the store. For over 12 hours, Apple left 2 buttons on their web site: Pre-Order and Reserve. The 'Reserve' seemed to work, but the 'Pre-Order' didn't.
That's when I made my decision... How arrogant can a brand/company be to knowingly put out a 'broken' button (and yes, I understand it was due to heavy volume) on their page without any warning, notice, or press release to their customers? Has Apple become just a big technological drug dealer selling 'goods' to millions of junkies?
Well, I don't want to be part of that dance any longer.
The other alternative was to just pay a termination fee and jump to Verizon or Sprint to get an Android phone like the HTC Evo or Motorola Droid X, but that would again fall outside of my budget because my wife would stay under AT&T with her new iPhone, and I wouldn't be able to use a family plan for our phones. That's when I discovered that AT&T was now carrying the Palm Pre Plus, which runs the Linux based webOS. I decided to buy the phone even though there was an existing risk of buying a device from a company that has been recently acquired by HP. What would happen to support? What would happen to future WebOS releases?
Since that time, HP announced that it intends to use WebOS in future versions of its devices like smartphones and tablet PCs.
As of the writing of this article, I've owned my Palm Pre Plus for about 17 days, and overall I am a bit disappointed with the hardware, but very satisfied with WebOS. The multitasking capabilities are fantastic, although it clearly affects the battery life on the device, which compared to the iPhone is very poor. I like the fact that I can mount my device on my Fedora Linux laptop, drop MP3s files into the Music directory, and it just plays. The package management tool Preware is another great advantage of this phone, which lets you install unofficial apps, including WebOS patches, and even overclock your phone; not advised by Palm, yet it works pretty well so far.
In closing, I think WebOS has a lot of potential and I can't wait to see what HP is going to do with it. The phone itself has been a bit of a disappointment, but not enough for me to regret getting one, but I sincerely hope the new versions put out by HP/Palm will resolve some of the issues I've found so far.
| Share |
|
Talkback: Discuss this article with The Answer Gang
![[BIO]](../gx/authors/silva.jpg)
Anderson Silva works as an IT Release Engineer at Red Hat, Inc. He holds a BS in Computer Science from Liberty University, a MS in Information Systems from the University of Maine. He is a Red Hat Certified Architect and has authored several Linux based articles for publications like: Linux Gazette, Revista do Linux, and Red Hat Magazine. Anderson has been married to his High School sweetheart, Joanna (who helps him edit his articles before submission), for 11 years, and has 3 kids. When he is not working or writing, he enjoys photography, spending time with his family, road cycling, watching Formula 1 and Indycar races, and taking his boys karting,
These images are scaled down to minimize horizontal scrolling.
Flash problems?All HelpDex cartoons are at Shane's web site, www.shanecollinge.com.
Talkback: Discuss this article with The Answer Gang
 Part computer programmer, part cartoonist, part Mars Bar. At night, he runs
around in his brightly-coloured underwear fighting criminals. During the
day... well, he just runs around in his brightly-coloured underwear. He
eats when he's hungry and sleeps when he's sleepy.
Part computer programmer, part cartoonist, part Mars Bar. At night, he runs
around in his brightly-coloured underwear fighting criminals. During the
day... well, he just runs around in his brightly-coloured underwear. He
eats when he's hungry and sleeps when he's sleepy.
More XKCD cartoons can be found here.
Talkback: Discuss this article with The Answer Gang
I'm just this guy, you know? I'm a CNU graduate with a degree in physics. Before starting xkcd, I worked on robots at NASA's Langley Research Center in Virginia. As of June 2007 I live in Massachusetts. In my spare time I climb things, open strange doors, and go to goth clubs dressed as a frat guy so I can stand around and look terribly uncomfortable. At frat parties I do the same thing, but the other way around.
These images are scaled down to minimize horizontal scrolling.
All "Doomed to Obscurity" cartoons are at Pete Trbovich's site, http://penguinpetes.com/Doomed_to_Obscurity/.
Talkback: Discuss this article with The Answer Gang
Born September 22, 1969, in Gardena, California, "Penguin" Pete Trbovich today resides in Iowa with his wife and children. Having worked various jobs in engineering-related fields, he has since "retired" from corporate life to start his second career. Currently he works as a freelance writer, graphics artist, and coder over the Internet. He describes this work as, "I sit at home and type, and checks mysteriously arrive in the mail."
He discovered Linux in 1998 - his first distro was Red Hat 5.0 - and has had very little time for other operating systems since. Starting out with his freelance business, he toyed with other blogs and websites until finally getting his own domain penguinpetes.com started in March of 2006, with a blog whose first post stated his motto: "If it isn't fun for me to write, it won't be fun to read."
The webcomic Doomed to Obscurity was launched New Year's Day, 2009, as a "New Year's surprise". He has since rigorously stuck to a posting schedule of "every odd-numbered calendar day", which allows him to keep a steady pace without tiring. The tagline for the webcomic states that it "gives the geek culture just what it deserves." But is it skewering everybody but the geek culture, or lampooning geek culture itself, or doing both by turns?

![[cartoon]](misc/xkcd/frogger.png "I understand you and your team worked hard on this, but when we said to make it more realistic, we meant the graphics.")

