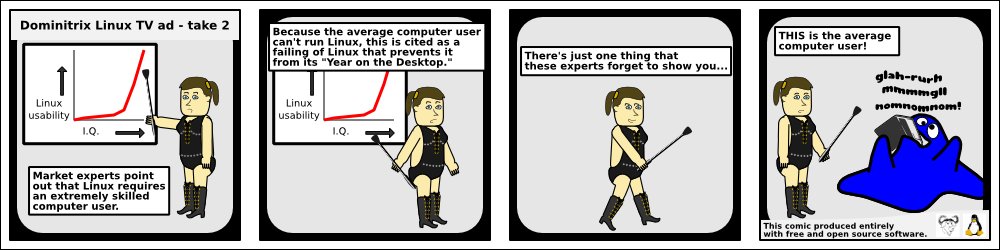
...making Linux just a little more fun!
Dr. Parthasarathy S [drpartha at gmail.com]
There is tooooo many garbage mails/spam mails in the TAG mailing list. Can no one take some action ? Please filter out all garbage. Otherwise people will stop reading or answering TAG mails.
Thank you,
partha
-- --------------------------------------------------------------------------------------------- Dr. S. Parthasarathy | mailto:[email protected] Algologic Research & Solutions | 78 Sancharpuri Colony | Bowenpally P.O | Phone: + 91 - 40 - 2775 1650 Secunderabad 500 011 - INDIA | WWW-URL: http://algolog.tripod.com/nupartha.htm ---------------------------------------------------------------------------------------------
[ Thread continues here (18 messages/26.82kB) ]
Suramya Tomar [security at suramya.com]
Hey,
I recently installed Ubuntu 9.04 on my system and then installed KDE 4.2.2 on the system using apt-get.
I don't like any system sounds (beeps when opening windows/ on popups etc etc) so I went to the KDE control panel and disabled all the system sounds over there. In KDE 3.5 this used to disable all sounds in Gnome applications as well but in 4.2.2 this doesn't seem to be the case.
So I ran the gnome Control panel and disabled all system sounds over there. Now the problem is that this setting doesn't seem to be saved. Thus when I restart the system all the system sounds on gnome apps (Nautilus/Firefox/gedit/X-Chat etc) are back.
So how do I set it so that the sounds are disabled and stay that way over reboots?
Also the same issue is there with the fonts in the Gnome applications. The fonts in gnome applications (Size mainly) doesn't match the ones in KDE applications. I have to change them using the Gnome control panel and the changes don't stay saved.
Any idea's/Suggestions? I did try searching for solutions but none of the solutions suggested by google worked.
Let me know if you need any additional details.
- Suramya
-- ------------------------------------------------- Name : Suramya Tomar Homepage URL: http://www.suramya.com -------------------------------------------------************************************************************
[ Thread continues here (6 messages/7.23kB) ]
Mike Orr [sluggoster at gmail.com]
Is there a version of chmod/chown that recursively changes files only if they're different from the specification? The stock version changes them unconditionally, which updates their 'ctime' and thus makes 'rsync' transfer the inode properties even if there's no real change. I could write a Python version, but I was hoping there might be a C version somewhere that would be more efficient with millions of filenames.
-- Mike Orr <[email protected]>
[ Thread continues here (8 messages/8.34kB) ]
Abhishek Sharma [spyzer.abhishek0 at gmail.com]
Hi,
I am working on a project of making a small OS which will boot up on my dual core machine and will serve as a simple calculator. If its possible I would like to add GUI to it too.
My question is for this job do I need to program all the stuff as assembly code or is there a way in which the precompiled linux kernel or those "boot.img | initrd.img" can help me without having to go through assembly development?
If its possible I would be glad if you tell me how I can achieve this.
Thank You.
[ Thread continues here (7 messages/8.71kB) ]
Predrag Ivanovic [predivan at nadlanu.com]
On Fri, 18 Sep 2009 23:06:39 -0500
<forwarded message from Master of Technology>
>i have some proble to define the > >1.Congestion windows Size 2.algorithms. in NS-2 with Linux(Fedora) > >Thanking you. > >Mr. Brahm Deo sah >India
http://lmgtfy.com/?q=Congestion+%20windows+Size+%20algorithms.+in+NS-2
Pedja
-- improperly oriented keyboard
[ Thread continues here (3 messages/2.96kB) ]
[ In reference to "A Quick-Fire chroot Environment" in LG#167 ]
Jimmy O'Regan [joregan at gmail.com]
'as the "fortune" program says, "The best book on programming for the layman is Alice in Wonderland; but that's because it's the best book on anything for the layman."'
I think I laughed harder than I usually would have at this, because I'd recently read a linguistics paper (http://www.kwartjez.amu.edu.pl/Krazynska,%20Sloboda.pdf) whose 'Further Reading' section contained, sandwiched between various works about proto-Indo-European, a pointer to a translation of this very book. It also happens that when asked by a friend if it were possible to get old books in Polish and English text, and English audio, to be the only book I could find legally in all three forms.
Curiouser and curiouser.
[ In reference to "Coding a Simple Packet Sniffer " in LG#128 ]
Aisha S. Azim [aisha.s.azim at gmail.com]
On Tue, Oct 6, 2009 at 7:54 PM, Aisha S. Azim <[email protected]>wrote:
Hi,
This tutorial is great, and so is sniffex.c. EXCEPT, it doesn't print the payloads of packets when using UDP. Why ever not? It'll print out packet number, source/destination, protocol, but never the hex/ascii payload and header of the packet itself. Help!
Thanks Aisha S. Azim
[ In reference to "The Unbearable Lightness of Desktops: IceWM and idesk" in LG#160 ]
mrfrank [czechfox at sbcglobal.net]
ATTN:Ben Okopnik
Just happened to run across the question in Linux Gazette Mar issue about idesk. Just so happens I finally got idesk up a couple hrs ago using your info at http://linuxgazette.net/160/okopnik.html then downloaded your idesk icon configurator. Small problem at this end.
Instead of showing icons, I get a series of 'Submit Query' in my browser. If I configure a link by clicking on one of the 'Submit Query's it makes my link just fine, even giving me the complete path to the .png file & the .png on the desktop link, even though the icon itself is no shown in browser.
This is a sample of the source code showing icon names;
<h3 style="background-color: blue; color: white; text-align: center">Click on an icon to create the IDesk link file</h3> <input type="image" name="24x24/places/network-server.png" src="24x24/places/network-server.png" vspace="2" hspace="3" /> <input type="image" name="24x24/places/folder-saved-search.png" src="24x24/places/folder-saved-search.png" vspace="2" hspace="3" /> <input type="image" name="24x24/places/user-home.png" src="24x24/places/user-home.png" vspace="2" hspace="3" /> <input type="image" name="24x24/places/gnome-fs-trash-empty.png" src="24x24/places/gnome-fs-trash-empty.png" vspace="2" hspace="3" />I'm running icewm on unbuntu 9.04. Browser is firefox 3.08. Also Opera, but Opera shows a rectangle with 'image' in it. If I copy the source and insert /home/xxxxxxx/.idesktop/builder/ into
<input type="image" name="24x24/places/user-home.png" src="24x24/places/user-home.png" vspace="2" hspace="3" />
so it looks like this:
<input type="image" name="24x24/places/user-home.png" src="/home/xxxxxxx/.idesktop/builder/24x24/places/user-home.png" vspace="2" hspace="3" />the icon shows o.k. I don't know cgi, but I played around with idesk.cgi but can't figure out how to get the full path to the .png files to show in the html.
Any ideas how I can get the full path to show in the html?
Thank you.
later xxxxxxx
[ Thread continues here (2 messages/3.64kB) ]
Oscar Laycock [oscar_laycock at yahoo.co.uk]
This all started when I wanted to run the latest version of Firefox. I decided to build my own from source. But my kernel, assembler, compiler and C library were too old - in fact, nine years old. So I built new ones under the /usr/local directory. I used the Linux From Scratch book as a guide.
Now when I build new programs, I set the GCC compiler's "rpath" option to point to the libraries in /usr/local rather than in the usual /lib and /usr/lib. The rpath is a list of libraries at the start of a program that can tell Linux where to look for shared libraries when Linux runs a program. A program called the "dynamic linker" does the job. On my system it is "/lib/ld-linux.so.2". You can see a program's rpath by running a command such as "readelf -a /bin/ls". Of course, normally there isn't one. Also you can watch the dynamic linker at work using the "ldd" command. I set GCC's rpath by including it in the CFLAGS environment variable when configuring programs before building them. (You typically type "configure", "make" and "make install" to build a program.) I found a small number of programs ignore CFLAGS, so I made the gcc program a shell script, which then calls the real gcc with the right rpath option.
So I can now run old commands such as "ls" and "find" alongside new programs such as the KDE suite. The now eleven-year-old commands run fine on top of the recent kernel. I also put /usr/local/bin at the start of my path. This may be a security risk but my PC is not connected to the internet or a network.
There is a bit more too it. So here is the CFLAGS setting I used only few days ago:
export CFLAGS="-O2 -I. -I.. -I/usr/local/myglibc27/include -I/usr/local/include -L/usr/local/myglibc27/lib -L/usr/local/lib -L/usr/local/lib/gcc/i686-pc-linux-gnu/4.2.3 -Wl,-rpath=/usr/local/myglibc27/lib:/usr/local/lib:/usr/local/lib/gcc/i686-pc-linux-gnu/4.2.3,-dynamic-linker=/usr/local/myglibc27/lib/ld-linux.so.2 -specs=/home/oscar/tmp/glibc/myspecs08scr -march=pentium2"
I also similarly set these environment variables: LDFLAGS, CXXFLAGS, CPPFLAGS, LIBCFLAGS, LIBCXXFLAGS. You can see that the include file path (-I's) and libraries path (-L's) match the rpath. The "-I. -I.." is there because some programs need to look at the header files in the build directory first - a bit of a quick fix. Notice how I now have two separate dynamic linkers on my PC. I had to edit the compiler specs file a little. Here is a section to really confuse you:
*startfile:
%{!shared: %{pg|p|profile:/usr/local/myglibc27/lib/gcrt1.o%s;pie:/usr/local/myglibc27/lib/Scrt1.o%s;:/usr/local/myglibc27/lib/crt1.o%s}}��� /usr/local/myglibc27/lib/crti.o%s %{static:/usr/local/lib/gcc/i686-pc-linux-gnu/4.3.2/crtbeginT.o%s;shared|pie:/usr/local/lib/gcc/i686-pc-linux-gnu/4.3.2/crtbeginS.o%s;:/usr/local/lib/gcc/i686-pc-linux-gnu/4.3.2/crtbegin.o%s}
I think this is choosing which C runtime code to put at the start of the program.
And here is the shell script that stands in for gcc:
[ ... ]
[ Thread continues here (2 messages/4.00kB) ]
Mulyadi Santosa [mulyadi.santosa at gmail.com]
During my boring saturday, I was thinking to create simple animated cycling mark. Here's the script:
$ while(true); do for a in \\ \| \/ -; do echo -n $a; sleep 1 ; echo -n -e \\r ; done; done
Notice the usage of escaped "\r" (carriage return) and "-n" option to display continous marks at the same line and at the same column
-- regards,Freelance Linux trainer and consultant
blog: the-hydra.blogspot.com training: mulyaditraining.blogspot.com
[ Thread continues here (5 messages/5.54kB) ]
Amit Saha [amitsaha.in at gmail.com]
Hello:
I have been using CPython as a calculator, while I do all those number crunching in C. SO, 'import math' is a must.
This is what I did:
- Create a file: .pythonrc in my $HOME and place this line:
import math
- Now in your BASH, .bashrc or similar: export PYTHONSTARTUP= $HOME/.pythonrc
Everytime you start Python interactively, you should have the 'math' module already imported.
$ python Python 2.6.4rc1 (r264rc1:75270, Oct 10 2009, 02:40:56) [GCC 4.4.1] on linux2 Type "help", "copyright", "credits" or "license" for more information.>>> math.pi3.1415926535897931
Hope this helps.
-- Journal: http://amitksaha.wordpress.com, �-blog: http://twitter.com/amitsaha
Jimmy O'Regan [joregan at gmail.com]
http://detexify.kirelabs.org/classify.html
Nifty website: draw the TeX symbol you were thinking of, and it tells you which one it (probably) is. Source (MIT license) here: http://github.com/kirel/detexify
[ Thread continues here (3 messages/1.80kB) ]
Amit Saha [amitsaha.in at gmail.com]
Hello TAG:
Can this be a possible 2-cent tip?
Couple of things first up:
* GNU plot supports piping, So, echo "plot sin(x)" | gnuplot will plot the sin(x) function.
* However, the plot disappears even before you could see it. For that echo "plot sin(x)" | gnuplot -persist , is useful. It persists the GNU plot main window
The usefulness of the second point is that, if you have a "pipe descriptor" describing a pipe to the open GNU plot instance , you can plot more plots on the first plot, without opening a new GNU plot instance. We shall be using this idea in our code.
#include <stdio.h>
#define GNUPLOT "gnuplot -persist"
int main(int argc, char **argv)
{
FILE *gp;
gp = popen(GNUPLOT,"w"); /* 'gp' is the pipe descriptor */
if (gp==NULL)
{
printf("Error opening pipe to GNU plot. Check if you have it! \n");
exit(0);
}
fprintf(gp, "set samples 2000\n");
fprintf(gp, "plot abs(sin(x))\n");
fprintf(gp, "rep abs(cos(x))\n");
fclose(gp);
return 0;
}
The above code will produce a comparative plot of absolute value of sin(x) and cos(x) on the same plot. The popen function call is documented at http://www.opengroup.org/pubs/online/7908799/xsh/popen.html. This code/idea should work on GCC and Linux and any other language and OS that supports piping.
Utility: If you have a application which is continuously generating some data, which you will finally plot, then you can plot the data for every new set of data- that gives a nice visualization about how the data is changing with the iterations of your application. This is a perfect way to demonstrate convergence to the best solutions in Evolutionary Algorithms, such as Genetic Algorithms.
Best, Amit
-- Journal: http://amitksaha.wordpress.com, �-blog: http://twitter.com/amitsaha
[ Thread continues here (4 messages/7.26kB) ]
By Deividson Luiz Okopnik and Howard Dyckoff

|
Contents: |
Please submit your News Bytes items in plain text; other formats may be rejected without reading. [You have been warned!] A one- or two-paragraph summary plus a URL has a much higher chance of being published than an entire press release. Submit items to [email protected]. Deividson can also be reached via twitter.
 Red Hat Urges Supreme Court to Exclude Patents to Software
Red Hat Urges Supreme Court to Exclude Patents to SoftwareOn October 1st, Red Hat filed an amicus brief with the United States Supreme Court. In the brief, Red Hat explains the practical problems of software patents to software developers. The brief, filed in the Bilski case, asks the Supreme Court to adopt the lower court's "machine-or-transformation" test and to make clear that it excludes software from patentability.
The Bilski case involves the standard for patenting a process. The case concerns a business method patent, but involves many of the same issues as software patents.
"Red Hat continues its commitment to the free and open source software community by taking a strong position against bad software patents," said Rob Tiller, vice president and assistant general counsel, IP for Red Hat. "Our patent system is supposed to foster innovation, but for open source and software in general, it does the opposite. Software patents form a minefield that slows and discourages software innovation. The Bilski case presents a great opportunity for the Supreme Court to rectify this problem."
Patenting of software exploded in the 1990s based on judicial decisions changing the test for patentable subject matter. Software patents now number in the hundreds of thousands, and they cover abstract technology in vague and difficult-to-interpret terms. Because software products may involve thousands of patentable components, developers face the risk of having to defend weak-but-costly patent infringement lawsuits. A new class of business enterprise - patent trolls - has developed to file lawsuits to exploit this system.
The Federal Circuit set forth a clear test to determine if a process is patentable in stating that it must be either "tied to a particular machine or apparatus" or must "transform a particular article into a different state or thing." Red Hat argues that this standard is consistent with Supreme Court case law, and that it should be applied to exclude algorithms, including computer software, from patenting.
The scope of patentable subject matter is an issue of critical importance to the future development of all software, including open source. The upcoming Supreme Court's Bilski decision could clarify the law and lessen the risks that innovation will be hindered by software patents. Oral argument is scheduled for November 9, 2009.
Red Hat has supported patent reform to address problems posed to open source and other software developers. It previously filed an amicus brief in the Bilski case with the Federal Circuit Court of Appeals. To read the full amicus brief, visit http://www.redhat.com/f/pdf/rh-supreme-court-brief.pdf.
Linux Foundation
Announces Hardware Perks for Individual MembersThe Linux Foundation has announced new benefits for individual members, including employee purchase pricing from Dell, HP and Lenovo, and the opportunity to secure a Linux.com email address for life.
Linux Foundation individual members can get up to 40 percent off of Lenovo devices and standard employee purchase pricing from Dell and HP. Dell also offers a best price guarantee to Linux Foundation members. These benefits can translate into hundreds or thousands of dollars for those who purchase their devices as part of this program.
Existing members that would like to ensure their Linux.com email address is permanent and not dependent on Linux Foundation membership renewal can elect to secure it with a one-time $150 fee. New members who want the same benefit will pay a total of $249 for the first year' membership and the lifetime benefit. Linux.com email addresses allow members to publicly represent their support for Linux and to demonstrate their community participation.
"Our individual members are the heartbeat of the Linux Foundation and we will continue to find ways to extend special benefits to them," said Jim Zemlin, executive director at the Linux Foundation. "Perks like the employee purchase discounts from Dell, HP and Lenovo and lifetime Linux.com email addresses are unique things we can offer to sustain support for Linux."
The annual membership fee for individuals is $99. Students can also now become members with a student-class membership for $25 annually.
Other discounts and benefits available to individual members include:
To join the Linux Foundation or to see a full list of benefits and discounts, visit their membership page: http://www.linuxfoundation.org/about/join/individual/ .
Moblin 2 on new NetbooksDemonstrating industry momentum for netbooks and the Moblin operating system, Renee James, general manager of Intel's Software and Services Group, announced at IDF that the Dell Inspiron Mini 10v with would be available with Ubuntu Moblin Remix Developer Edition pre-installed. James also announced that ASUS and Acer have already launched and Samsung is planning to launch Moblin 2-based netbook devices. Many operating system vendors, including Canonical, CS2C, Linpus, Mandriva, Novell, Phoenix and Turbolinux, announced at IDF that production-ready Moblin version 2-based operating systems are now available. Moblin is an open-source Linux operating system project for netbooks, handhelds, smartphones and in-car computers.
Additionally, operating system support for Microsoft Silverlight will be expanded to include Moblin early next year. Using Silverlight's cross-platform foundation, developers can write applications once and have them run on both Windows and Moblin devices.
In the same IDF keynote, James unveiled the Intel Atom Developer Program. This effort encourages independent software vendors and developers to create mobile applications. Intel is partnering with manufacturers, including Acer and ASUS, to create multiple application stores (like the iPhone store) where applications and application building blocks for Atom-based netbooks and handhelds will be sold.
Ubuntu 9.10 Desktop, Server and UNR Editions ReleasedCanonical released Ubuntu 9.10 Desktop Edition and Server Edition, the latest version of its popular Linux distribution, for free download on October 29th. The 9.10 version of its UNR (Ubuntu Netbook Remix) OS is also available. This is the OS version previously known as Karmic Koala.
Ubuntu 9.10 Desktop features a redesigned, faster boot and login experience, a revamped audio framework, Firefox 3.5, and improved 3G broadband connectivity, all of which contribute to a first-class user experience.
With its '100 Paper Cuts' initiative to allow users to nominate minor annoyances that impacted their enjoyment of the platform, over 50 fixes have been committed, removing minor irritants such as inconsistent naming or poorly organized application choices. Larger scale user experience improvements include a refreshed Ubuntu Software Centre, giving users better information about the software they have available.
Ubuntu 9.10 also includes the integration of 'Ubuntu One' as a standard component of the desktop. Ubuntu One is an umbrella name for a suite of online services released in beta in May 2009. Ubuntu One simplifies backup, synchronization, and sharing of files with features such as Tomboy Notes and contacts synchronization.
Developers interested in writing applications that run on Ubuntu now have a simplified toolset called 'Quickly' which automates many mundane programming tasks. Quickly also helps users 'package' the code and distribute it through the Ubuntu software repositories. Ubuntu developers will now find all code hosted in the Bazaar version control system, which is part of the fully open source Launchpad collaboration website.
Netbook and smartbook users will find improvements to the Ubuntu 9.10 Netbook Remix interface. Common with Ubuntu 9.10 for desktops UNR will integrate the Empathy instant messaging program for text, voice, video, and file transfers.
"Ubuntu 9.10 gives users more reasons than ever to seriously consider Linux at a time when many are thinking again about their operating system options. We are delivering a platform for users interested in an easy-to-use, great-looking, Web-friendly operating system" says Jane Silber, COO at Canonical.
At the press conference before the 9.10 release, Mark Shuttleworth, CEO and founder of Canonical, remarked that he was "delighted Windows 7 was out," and that, "now we can engage in a real head to head competition." Shuttleworth added that after OEMs were using Linux on netbooks and smaller devices they have "seen the advantage with having more than one OS vendor and don't want to return to having only one choice." Shuttleworth said he expected Linux to continue to dominate in mobile devices because Windows 7 varients would be too expensive. He aslo noted that hardware OEMs were doing a better job of supporting Linux, especially after Intel's efforts with Moblin.
Ubuntu 9.10 Server Edition introduces Ubuntu Enterprise Cloud (UEC) as a fully supported technology. This is an open source cloud computing environment, based on the same Application Programming Interfaces (APIs) as Amazon EC2, and allows businesses to build private clouds. Canonical CEO and Ubuntu founder Mark Shuttleworth began highlighting the embedded cloud tools during the spring of this year. Ubuntu 9.10 Server Edition will also be available on the Amazon EC2 environment as an Amazon Machine Image (AMI). For the purpose of portability, Ubuntu's UEC images are identical to Ubuntu's AMI, and work done in one environment can be uploaded to the other.
Ubuntu Enterprise Cloud (UEC) is the umbrella name for a number of cloud technologies, which includes the open source Eucalyptus project. UEC makes it easy and fast for system administrators to set up, deploy and manage a cloud environment. Users familiar with Elastic Compute environments will be able to build similar infrastructure behind their firewall, avoiding many regulatory and security concerns that prevent many enterprises from taking advantage of cloud environments. UEC also provides a tight integration with power management tools such as the new Canonical-sponsored PowerNap project which allows servers to be put to sleep when they are not actively used.
Ubuntu Enterprise Cloud is preparing a store capability that will provide users with easy access to ready-to-deploy applications in the UEC environment. A first preview of this store is available in Ubuntu 9.10, together with a sample application. It will demonstrate solutions to software vendors and additional applications will be added after the release.
The core server product and kernel have also received significant attention in this release. MySQL 5.1 has been added. The directory stack and Single Sign On tools have been upgraded for improved directory integration. Django now ships as a fully supported framework enhancing web server options.
There have been numerous kernel improvements to better support both Xen (guest) and KVM (host and guest) virtualization, and to improve caching performance. Support for the USB 3.0 protocol has been included to support super speed transfer rates when devices become available. System management support has been extended through support for the WBEM (Web-based enterprise management) protocols which open up support of the Ubuntu environment to the most popular system management tools currently deployed in enterprises and allows them to interact more easily with Canonical's management tool for Ubuntu, called Landscape.
Ubuntu Enterprise Cloud is included as part of Ubuntu 9.10 Server Edition. Landscape Server Management System is available at http://www.canonical.com/projects/landscape.
Earlier press reports erroneously listed Ubuntu 9.10 as having early support for the new USB 3.0 standards. This support is actually planned for the next release.
Ubuntu Desktop and Server Editions and UNR are entirely free of charge and can be downloaded from http://www.ubuntu.com . Ubuntu One offers 2 GB storage for free, and 50 GB for $10 per month.
The 100 Paper Cuts project can be found here:
https://edge.launchpad.net/hundredpapercuts/.
The list of UNR supported netbooks can be found here
https://wiki.ubuntu.com/HardwareSupport/Machines/Netbooks/.
For more information, please visit http://www.canonical.com.
OpenBSD 4.6 now outOpenBSD 4.6 was released in October, a little earlier than expected. A few of the enhancements are noted here:
Generic Network-Stack improvements:
New platform support:
sparc64:Puppy Linux 4.3.1A new release of Puppy Linux 4.3.1, a bug-fix update of the recently released version 4.3, appeared in October. Some of the fixes and changes include: New modem drivers and improved modem detection; fixes for CD remaster script; Asunder CD ripper replaces Ripoff; You2pup, fix for spaces in paths; DidiWiki personal Wiki upgraded to 0.8; JWM window manager upgraded to revision 457; NicoEdit, secondary text editor, upgraded to 2.4; etc.
Mandriva Linux 2010 RC2The second release candidate for Mandriva Linux 2010 is now available on public mirrors. Mandriva Linux 2010 should be available in early November.
Besides bug fixes, it also includes Moblin, KDE 4.3.2, GNOME 2.28, Poulsbo, a guest account, and Nepomuk.
openSUSE 11.2 RC1 availableThe first release candidate for openSUSE 11.2, which is due in mid-November, is now ready for testing. This release includes bug fixes and updates, including GNOME 2.28 final and Linux kernel 2.6.31.3. The new version includes: live version upgrade - no need to stop working while upgrading from openSUSE 11.1 to 11.2; support for several social networks like Facebook, Twitter and identi.ca; and running openSUSE from an USB stick.
Tiny Core Linux updatedTiny Core Linux is a very small (10 MB) minimal Linux desktop. It is based on Linux 2.6 kernel, BusyBox, Tiny X, FLTK graphical user interface and JWM window manager, running entirely in memory. The goal is the creation of a nomadic ultra-small desktop capable of booting from cdrom, pendrive, or frugally from a hard drive.
It is not a complete desktop, nor is all hardware completely supported. It represents only the core needed to boot into a very minimal X Window desktop, typically with wired Internet access. This minimal desktop can be extended by installing additional applications from online repositories. For more info, see: http://www.tinycorelinux.com/.
JetBrains' IntelliJ IDEA Goes Open SourceJetBrains, the creators of productivity tools for software developers, announced announced in October the public preview of the free Community Edition of its award-winning Java IDE, IntelliJ IDEA.
Starting with the upcoming version 9.0, IntelliJ IDEA will be offered in two editions: Community Edition, free and open-source, and Ultimate Edition, which until October was simply IntelliJ IDEA.
The introduction of the Community Edition removes cost as a major barrier to a wider use of IntelliJ IDEA for pure Java development. This edition is not only free, its also fully open-sourced.
"We've always been open to the community - with our public Early Access Program, issue trackers, forums, and so on. This made for a tight and direct feedback loop with our users, even at a time when this wasn't a widely accepted practice in the industry. Since then, we've supported hundreds of open-source projects with free product licenses, contributed code to various open-source projects like Groovy and Scala, and developed several open-sourced IntelliJ IDEA plugins ourselves," said Sergey Dmitriev, JetBrains CEO. "So, you can see how offering the IntelliJ IDEA experience for free, through an open-source license, goes hand in hand with our focus on the community. Open source has become the mainstream, and we continue to embrace it as an exciting challenge."
The new Community Edition is built on the IntelliJ Platform and includes its sources. JetBrains has made it as easy as possible to access and use the source code of the Community Edition and the IntelliJ Platform, by applying the democratic Apache 2.0 license to both of them.
The IntelliJ Platform serves as a basis for a wide range of other innovative JetBrains tools, designed for development in specific languages and/or domains. These tools include RubyMine, MPS, a web development IDE (already in public preview), and others currently in development.
IntelliJ split the two editions based on a functional principle:
The new features of Ultimate Edition version 9 include:
To review the extended list of new features of IntelliJ IDEA Ultimate 9, and to download the Preview build, please visit http://www.jetbrains.com/idea/nextversion/index.html.
To learn more and download the Community Edition Public Preview, please visit http://www.jetbrains.com/idea/nextversion/free_java_ide.html.
Read about the differences between the Community Edition and the Ultimate Edition at http://www.jetbrains.com/idea/nextversion/editions_comparison_matrix.html.
Learn more about the open source project for IntelliJ IDEA Community Edition and download its sources at http://www.jetbrains.org.
Dell Latitude Z-ltraPortable with Business FeaturesThe Dell Latitude Z is the claimed to be world's first ultra-thin 16-inch laptop that is less than an inch thick and starts at 4.5 pounds with a standard four-cell battery. The system includes:
The Latitude Z is available starting at $1,999. More details are available at http://www.dell.com/latitude.
Smallest Wireless N USB Adapter Now Available from TRENDnetTRENDnet has released what is possibly the world's smallest 150Mbps Mini Wireless N USB Adapter, its model TEW-648UB product. The ultra compact form factor is slightly larger than a U.S. quarter, measuring a remarkable 1.3 inches (3.3 cm) from end to end.
The 150Mbps Mini Wireless N USB Adapter connects a laptop or desktop computer to a wireless 'n' network at up to 6x the speed and 3x the coverage of a wireless 'g' connection. One-touch Wi-Fi Protected Setup or WPS technology eliminates the hassle of entering complicated codes in order to connect to a wireless network.
Advanced wireless encryption protects your valuable data. Wi-Fi Multimedia (WMM) Quality of Service prioritizes important video, audio and gaming traffic to create a premium wireless experience.
"We have looked high and low and are confident in our claim that the TEW-648UB is the smallest adapter on the market today. In fact it is half the size of the average wireless N USB adapter.", stated Zak Wood, Director of Global Marketing for TRENDnet. "Despite its diminutive size, it performs well. We welcome all independent tests against any other 150Mbps (or 1x1) adapter on the market today. The adapter features an equally small price tag. With a predicted street price in the low $20 range, this adapter sets a new price-to-performance standard."
The 150Mbps Mini Wireless N USB Adapter, model TEW-648UB, has an MSRP of US $24.99.
Talkback: Discuss this article with The Answer Gang
![[BIO]](../gx/authors/dokopnik.jpg)
Deividson was born in União da Vitória, PR, Brazil, on 14/04/1984. He became interested in computing when he was still a kid, and started to code when he was 12 years old. He is a graduate in Information Systems and is finishing his specialization in Networks and Web Development. He codes in several languages, including C/C++/C#, PHP, Visual Basic, Object Pascal and others.
Deividson works in Porto União's Town Hall as a Computer Technician, and specializes in Web and Desktop system development, and Database/Network Maintenance.
Howard Dyckoff is a long term IT professional with primary experience at
Fortune 100 and 200 firms. Before his IT career, he worked for Aviation
Week and Space Technology magazine and before that used to edit SkyCom, a
newsletter for astronomers and rocketeers. He hails from the Republic of
Brooklyn [and Polytechnic Institute] and now, after several trips to
Himalayan mountain tops, resides in the SF Bay Area with a large book
collection and several pet rocks.
Howard maintains the Technology-Events blog at
blogspot.com from which he contributes the Events listing for Linux
Gazette. Visit the blog to preview some of the next month's NewsBytes
Events.

By Silas Brown
There are several reasons why you might have more than one website. For example, you might have an account on a fast server with limited quota, and another on a server that is slower but has more space, and you keep certain rarely-used files on the slower server. Or you might have an easy-to-remember dyndns alias pointing to your home server, but some pages on another server that has a better connection but a longer address. If this is the case, then it might be useful to set one of the servers to forward any requests for pages it can't find to the other server. Then you can use this first server in all the addresses you type, and if the page requested is on it, it will be returned, otherwise the browser will be automatically redirected to check the second server for the same page. (Don't set that second server to redirect back to the first or you'll have an infinite loop.)
Using Apache, this can be accomplished as follows. Firstly, put the following line into your public_html/.htaccess file, replacing /~your-user-ID as appropriate (if you have your own hostname then you can omit it):
ErrorDocument 404 /~your-user-ID/cgi-bin/redirect.cgi
This tells Apache to run the script whenever it would normally issue a 404. If you want the redirection to take effect for index.html also (that is if index.html is missing), then you should also add:
Options -Indexes ErrorDocument 403 /~your-user-ID/cgi-bin/redirect.cgi
This prevents directory listing, and tells Apache to send the browser to the redirection script instead of showing the "Forbidden" message. This arrangement might be useful if your main site is on the other server but this server contains a few extra files that you want Apache to check for first.
Then create public_html/cgi-bin/redirect.cgi as follows, replacing other-site-address-goes-here and ~your-user-ID as appropriate:
#!/bin/bash echo Status: 301 Moved echo Location: "$(echo "$REQUEST_URI"|sed -e s,/,http://other-site-address-goes-here/, -e s,~your-user-ID/,,)" echo
Then chmod +x public_html/cgi-bin/redirect.cgi and test.
The above script should work regardless of whether or not ~your-user-ID is included in the request, that is, if Apache is serving your public_html on your own hostname then this script should work regardless of whether the incoming request is for your hostname or for your user ID on the main hostname.
Some antiquated browsers might not follow the 301 redirect. If this is a concern then you can add some text in the response as well. But the script as it stands is small and easily set up, and should work without trouble in most cases.
Talkback: Discuss this article with The Answer Gang
![[BIO]](../gx/authors/brownss.jpg)
Silas Brown is a legally blind computer scientist based in Cambridge UK. He has been using heavily-customised versions of Debian Linux since 1999.
It's nearly time to retire 2009, yet many conferences for the Linux and open source community are just about to happen. A plethora will happen in the first week of November, so this preview may give you ideas for 2010.
Here's a short list of what's on offer:
As you may know, the End User Summit organized by the Linux Foundation is by invitation only. The event is closed to the press, as was the first summit, in 2008. The Summit is primarily an opportunity for big corporate end-users to meet with leaders from within the Linux community, including the highest-level maintainers and developers. The event was originally created at the request of the Linux Foundation's Technical Advisory Board.
The Summit will take place November 9-10, 2009, at the Hyatt Jersey City on the Hudson. Its location, just off the Exchange Place PATH Station, will give corporate Linux users quick access from East Coast hubs.
There will be sessions on open source legal fronts, Linux and the challenges of a down economy, tracing and performance management, scaling Linux to 4096 processors, and other technical sessions.
LISA '09, the annual sysadmin conference organized by USENIX, starts the month off in Baltimore. Locals in the Baltimore-DC area can get the new LISA Evening Pass. This allows access after work for conference receptions, the Vendor Exhibition on Wednesday only, the popular Birds of a Feather sessions (BoFs), and more.
There will be sessions on cfEngine, VMware vSphere 4.0, and zero-emission data centers. Cutting-edge practices and new or developing work are presented in the paper presentations and the poster sessions. Check out the list of accepted posters at http://www.usenix.org/events/lisa09/posters.html. Also, all registered LISA '09 attendees are eligible to received a Google Wave Sandbox invitation.
Here's an overview of LISA '09: http://www.usenix.org/events/lisa09/ataglance.html
Here's a link to past LISA conference proceedings: http://www.usenix.org/events/bytopic/lisa.html
ApacheCon '09 will be held in Oakland, CA; this year is also the 10th anniversary of the Apache Foundation. The venue is the Marriott City Center Hotel (and that's a very safe location). Last year, it was held in New Orleans.
The first 2 days include half-day tutorials. There are also several free events paralleling the conference tutorial days, including the Hackathon and the BarCamps.
Apache Hackathon is held over the two days prior to the main three-day conference, November 2-3, and everyone can join in this free codefest event. Coinciding with the traditional Hackathon, BarCampApache is open to the public, and the schedule will be determined by the participants. Topics at BarCampApache need not be Apache-specific.
Here's a conference overview: http://www.us.apachecon.com/c/acus2009/schedule/grid/
There will be several BoFs or MeetUps at ApacheCon '09, and the current list is here: http://www.us.apachecon.com/c/acus2009/schedule/meetups/
Video recordings from the keynotes at last year's ApacheCon are here: http://streaming.linux-magazin.de/en/archive_apachecon08us.htm
The theme for Enterprise 2.0 San Francisco is "unlocking the business value of Enterprise 2.0", with an emphasis on how real customers are using enterprise 2.0 social media to enable a more efficient, agile, and highly productive workforce.
Conference topics include, among others:
Since this is a new conference, you might want to take a quick look at the keynotes from June's Enterprise 2.0 conference in Boston: http://www.e2conf.com/e2tv/
Enterprise 2.0 San Francisco is held jointly with VoiceCon, at the Moscone Center this year. Registration for one event allows access to the other.
QCon SF. This is the third annual San Francisco incarnation of the enterprise software development conference, and its focus is on developer team leads, architects and agile project management. This is primarily an open source conference, and has separate Ruby and Java tracks.
Organized jointly by the JAOO conference and the InfoQ.com Enterprise Software Development Community (original creators of TheServerSide.com and Symposium conferences), QCon is "...organized by the community, for the community."
One unique aspect of QCon is its Euro-centric origins. Many - but not most - of the speakers are leading developers and architects from Europe, and QCon is a great opportunity to meet peers from across the Atlantic without a passport and plane ticket. The global prospective is refreshing, and there is no overbearing presence of giant software vendors. All content, no spin.
QCon speakers include Martin Fowler, Amazon.com CTO Werner Vogels, Spring creator Rod Johnson, Hibernate creator Gavin King, Scrum co-founder Jeff Sutherland, LINQ inventor Erik Meijer, JRuby core developer Ola Bini, and others.
Here's a list of the conference tracks by day: http://qconsf.com/sf2009/tracks/
And here's a link to the archives from prior QCons, so you can see for yourself: http://qcon.infoq.com/archives/
Happy Thanksgiving, and a Happy New Year to all!
Talkback: Discuss this article with The Answer Gang
Howard Dyckoff is a long term IT professional with primary experience at
Fortune 100 and 200 firms. Before his IT career, he worked for Aviation
Week and Space Technology magazine and before that used to edit SkyCom, a
newsletter for astronomers and rocketeers. He hails from the Republic of
Brooklyn [and Polytechnic Institute] and now, after several trips to
Himalayan mountain tops, resides in the SF Bay Area with a large book
collection and several pet rocks.
Howard maintains the Technology-Events blog at
blogspot.com from which he contributes the Events listing for Linux
Gazette. Visit the blog to preview some of the next month's NewsBytes
Events.
By Mark Nielsen
MySQL Cluster has come a long way in the 4 years since I experimented with it. Compared to when I first got the cluster working on my home computer, I didn't have to change much get the latest version up and running.
So, what is MySQL Cluster? It is a database solution which tries to solve high availability issues by using multiple synchronous masters (for the lack of a better phrase) in a shared-nothing environment. In order to solve a lot of the latency issues associated with multiple masters, it keeps all the indexed data in memory to enable fast processing of the data.
So then what is the purpose of this article? To let you setup a MySQL Cluster for fun, on a single box, so you can test out its features1. The main things I wanted to test out are:
There is also one important item to keep in mind about MySQL Cluster. I have no idea why they make "MySQL Cluster" as a separate product from the main MySQL server. In the past, the "MySQL Cluster" was just the NDB engine running in MySQL. It seems to be the same way even now and I suspect that it might just be due to politics and marketing that they have something called a "MySQL Cluster" when it is really just MySQL with the NDB engine. The mysqld server running in "MySQL Cluster" can still store data in InnoDB and MyISAM formats.
For more info about MySQL Cluster, refer to:
MySQL copies data from one computer to another computer through MySQL Replication. The old way of replicating data was to copy over and execute all the SQL commands from one MySQL server to the other MySQL servers. This type of replication was called "Statement Level Replication.". This copying and executing of queries was NOT real-time and had some issues. Basically, it was like this:
For most practical purposes, most small queries finish very fast and replication is also very fast.
So what is Row level Replication? Basically, the SQL query which executes the changes on the master is forgotten and we only record the actual row differences and copy them over. For example, let us say that a query updates a table and sets the country code to 'US' for all entries that are NULL. In a table with 1 million rows, let's say only 10 rows were NULL and thus 10 rows get updated. The difference between Statement and Row Level Replication is the following:
Row Level Replication doesn't care what the SQL query was. It only looks at the data that has changed and copies those changes to the slaves.
Why does this frustrate me? For a few reasons:
I am glad we have Row Level Replication as an option and it can be nice to use depending on your needs. I just wish Statement Level Replication could be used if handled correctly under all all configurations. To give you a better perspective of why Statement Level Replication is nice to debug, we had a weird case one time where 1 byte in a replication stream would change for no reason over a WAN. If it changed in the data, nobody would notice (that's really bad). But if it changed in one of the SQL words, replication would break. We were easily able to compare the master's binlogs to the slave's binlogs and find out what the problem was. I remain sceptical how easy it will be to verify why things break with row level replication. Maybe I am just paranoid, but you have to be when managing databases.
/sbin/ifconfig lo:1 127.0.0.101 netmask 255.0.0.0 /sbin/ifconfig lo:2 127.0.0.102 netmask 255.0.0.0 /sbin/ifconfig lo:3 127.0.0.103 netmask 255.0.0.0 /sbin/ifconfig lo:4 127.0.0.104 netmask 255.0.0.0
As a side note, it is interesting to see how Ubuntu is taking off on the desktop market and how it is starting to creep into the server market. For me, I just like to use the same operating system for the desktops and servers because then I know that the operating system is flexible and can work under multiple environments. After all, isn't a desktop just a server running Xwindows with OpenOffice and FireFox? To me, the words "desktop" and "server" are just marketing terms.
Here's the setup for our article:
| Replication Type | Row Level Replication |
Special Rep Config |
Hacks necessary |
Problems | Notes | Weird Purpose | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Cluster | Other Engines |
MySQLD Master Replication |
Slave | Cluster Slave |
|||||||||||
| 1. | • | Basic configuration. | |||||||||||||
| 2. | • | • | 1 | Non-ndb data is split across mysqld nodes | 1 | ||||||||||
| 3. | • | • | • | Y | Y | Y | 2 | Can use other storage engines. | 1 | ||||||
| 5. | • | • | • | • | Y | Y | Y | 2 | Convert tables to non-NDB tables on Slave. | 1,2 | |||||
| 6. | • | • | Y | Standard Cluster Replication. | |||||||||||
| 7. | • | • | • | • | Y | Y | Y | 2 | Cluster Replication with non-NDB tables. | 1 | |||||
| 8. | • | • | • | • | • | Y | Y | Y | 2 | Convert replication to non-NDB tables on Slave. | 1,2 | ||||
Problems:
Weird Purposes:
These files I use to stop and start MySQL. I put it in /usr/local/mysql_cluster.
There are 3 ways to install MySQL: Do-It-Yourself, get it from a 3rd party, or from MySQL. It is unlikely that the official website for MySQL will have consistent downloads for Ubuntu versions. We'll see if things change in the future. You have two real options: Download and compile it yourself or download from a third party. I'll explain both here:
tar -zxvf cfiles.tgzIt should be safe to download and untar them in the working source directory of MySQL right after you have downloaded and untarred the source code for MySQL.
Note: The download steps below only work for a specific version of MySQL. Please refer to http://dev.mysql.com/downloads/cluster/ for newer versions.
Use my install script to install MySQL. You can read the various comments in the script. Please read the comments before you execute each section in the script. In general, it will attempt to setup three things:
NOTE: We only use Row Level Replication. It is possible to do this with Statement Level Replication, but it gets more complicated.
Look at my slave setup script.
./bin/mysql -u root -S instances/mysqlnode1/tmp/mysql.sock -e "create database if not exists ndb"You should see one line of data in both tables on the slave.
./bin/mysql -u root -S instances/mysqlslave1/tmp/mysql.sock -e "show databases" ./bin/mysql -u root -S instances/mysqlslave1/tmp/mysql.sock -e "create database if not exists ndb"
./bin/mysql -u root -S instances/mysqlslave1/tmp/mysql.sock -e "create table if not exists ndb.ndb1 (i int) engine=InnoDB;" ./bin/mysql -u root -S instances/mysqlnode1/tmp/mysql.sock -e "create table if not exists ndb.ndb1 (i int) engine=ndb;" ./bin/mysql -u root -S instances/mysqlnode1/tmp/mysql.sock -e "create table if not exists rep.rep1 (i int) engine=InnoDB;"
./bin/mysql -u root -S instances/mysqlnode1/tmp/mysql.sock -e "insert into ndb.ndb1 values (1);" ./bin/mysql -u root -S instances/mysqlnode2/tmp/mysql.sock -e "insert into rep.rep1 values (1);"
# These tables should contain one row each. ./bin/mysql -N -u root -S instances/mysqlnode1/tmp/mysql.sock -e "select * from ndb.ndb1" ./bin/mysql -N -u root -S instances/mysqlnode1/tmp/mysql.sock -e "select * from rep.rep1" ./bin/mysql -N -u root -S instances/mysqlnode2/tmp/mysql.sock -e "select * from ndb.ndb1" ./bin/mysql -N -u root -S instances/mysqlnode2/tmp/mysql.sock -e "select * from rep.rep1" ./bin/mysql -N -u root -S instances/mysqlslave1/tmp/mysql.sock -e "select * from ndb.ndb1" ./bin/mysql -N -u root -S instances/mysqlslave1/tmp/mysql.sock -e "select * from rep.rep1" ./bin/mysql -N -u root -S instances/mysqlcslave1/tmp/mysql.sock -e "select * from ndb.ndb1" ./bin/mysql -N -u root -S instances/mysqlcslave1/tmp/mysql.sock -e "select * from rep.rep1"
# Test replication for the non-replicating database. ./bin/mysql -u root -S instances/mysqlnode1/tmp/mysql.sock -e "create table if not exists norep.norep1 (i int) engine=InnoDB;" ./bin/mysql -u root -S instances/mysqlnode2/tmp/mysql.sock -e "create table if not exists norep.norep1 (i int) engine=InnoDB;" ./bin/mysql -u root -S instances/mysqlslave1/tmp/mysql.sock -e "create table if not exists norep.norep1 (i int) engine=InnoDB;" ./bin/mysql -u root -S instances/mysqlcslave1/tmp/mysql.sock -e "create table if not exists norep.norep1 (i int) engine=InnoDB;"
./bin/mysql -u root -S instances/mysqlnode1/tmp/mysql.sock -e "insert into norep.norep1 values (1);" ./bin/mysql -u root -S instances/mysqlnode2/tmp/mysql.sock -e "insert into norep.norep1 values (2);" ./bin/mysql -u root -S instances/mysqlslave1/tmp/mysql.sock -e "insert into norep.norep1 values (3);" ./bin/mysql -u root -S instances/mysqlcslave1/tmp/mysql.sock -e "insert into norep.norep1 values (4);"
# These tables should contain one unique value. ./bin/mysql -N -u root -S instances/mysqlnode1/tmp/mysql.sock -e "select * from norep.norep1" ./bin/mysql -N -u root -S instances/mysqlnode2/tmp/mysql.sock -e "select * from norep.norep1" ./bin/mysql -N -u root -S instances/mysqlslave1/tmp/mysql.sock -e "select * from norep.norep1" ./bin/mysql -N -u root -S instances/mysqlcslave1/tmp/mysql.sock -e "select * from norep.norep1"
When a MySQLd server using NDB restarts, it sends out an error message. It is not usually a good idea to restart replication without knowing what is going on and checking the logs. However, there may be times when you don't care. For that case, I have created a stored procedure using an event to kick off replication when a known error occurs. This stored procedure only works for the first 5 days. If you wish, you can modify it for a longer period of time.
Let's kill replication, install the stored procedure, and then see if it fixes replication.
if [ -e "instances/mysqlnode1/tmp/mysqld.pid" ]; then k=`cat instances/mysqlnode1/tmp/mysqld.pid` echo "Killing $k" kill $k fi if [ -e "instances/mysqlnode2/tmp/mysqld.pid" ]; then k=`cat instances/mysqlnode2/tmp/mysqld.pid` echo "Killing $k" kill $k fi sleep 2 if [ -e "instances/mysqlnode1/tmp/mysqld.pid" ]; then echo "Mysql node 1 still running." else echo "starting node 1 mysql" sudo -u mysql nohup ./libexec/mysqld --defaults-file=etc/my.cnf_node1 & fi if [ -e "instances/mysqlnode2/tmp/mysqld.pid" ]; then echo "Mysql node 2 still running." else echo "starting node 2 mysql" sudo -u mysql nohup ./libexec/mysqld --defaults-file=etc/my.cnf_node2 & fi
./bin/mysql -u root -S instances/mysqlnode1/tmp/mysql.sock -e "show slave status\G" | grep -i running ./bin/mysql -u root -S instances/mysqlnode2/tmp/mysql.sock -e "show slave status\G" | grep -i running ./bin/mysql -u root -S instances/mysqlslave1/tmp/mysql.sock -e "show slave status\G" | grep -i running ./bin/mysql -u root -S instances/mysqlcslave1/tmp/mysql.sock -e "show slave status\G" | grep -i running
./bin/mysql -u root -S instances/mysqlnode1/tmp/mysql.sock -e "source stored_procedure_rep.sp" mysql ./bin/mysql -u root -S instances/mysqlnode2/tmp/mysql.sock -e "source stored_procedure_rep.sp" mysql ./bin/mysql -u root -S instances/mysqlslave1/tmp/mysql.sock -e "source stored_procedure_rep.sp" mysql ./bin/mysql -u root -S instances/mysqlcslave1/tmp/mysql.sock -e "source stored_procedure_rep.sp" mysql
./bin/mysql -u root -S instances/mysqlnode1/tmp/mysql.sock -e "show slave status\G" ./bin/mysql -u root -S instances/mysqlnode2/tmp/mysql.sock -e "show slave status\G" ./bin/mysql -u root -S instances/mysqlslave1/tmp/mysql.sock -e "show slave status\G" ./bin/mysql -u root -S instances/mysqlcslave1/tmp/mysql.sock -e "show slave status\G"
# or just ./bin/mysql -u root -S instances/mysqlnode1/tmp/mysql.sock -e "show slave status\G" | grep -i running ./bin/mysql -u root -S instances/mysqlnode2/tmp/mysql.sock -e "show slave status\G" | grep -i running ./bin/mysql -u root -S instances/mysqlslave1/tmp/mysql.sock -e "show slave status\G" | grep -i running ./bin/mysql -u root -S instances/mysqlcslave1/tmp/mysql.sock -e "show slave status\G" | grep -i running
Here are some future topics:
I loaded data onto both the SSD and the SATA drives I have. I have separate MySQL Cluster installations on each hard drive. My computer is from late 2004, so it probably only a SATA I bus. So this is a really bad test for testing real performance, but I just wanted to get a rough idea of what I am dealing with. Both the SATA drive and the SSD drive were brand new. I was using an SSD Vertex 60 gig drive. I loaded a 200 MB file onto the system, but, there were 4 MySQL instances running. The two data nodes for the cluster, a slave, and a cluster slave. In addition, the binlogs would have a copy of all the data for the MySQLd instances. Thus, there are 8 copies of the data (4 in the databases, 4 in logs). I expect on a system with just one MySQL instance it would run a lot faster.
For cdrom copying times of 700 megs, look at this table. The SSD drives appears to be about 66% faster. However, when you compare this to the next table, SSD shows to be even better (as expected).
| Cd copy count | SATA seconds | SSD seconds |
|---|---|---|
| 1 | 28 | 20 |
| 2 | 29 | 19 |
| 3 | 34 | 20 |
| 4 | 32 | 19 |
| 5 | 30 | 19 |
| 6 | 32 | 20 |
| 7 | 32 | 18 |
| 8 | 32 | 20 |
We can see that the MySQL Cluster is running 2 to 5 times faster on the SSD drive. This is not surprising if the latency on the SSD drive is better. The inserts below were at 1000 rows at a time. The python script has the detailed schema information. I compared 3 different points in the log files for the inserts. I compared the recent time for 1000 rows being inserted and the total time up to that point. The loading stopped at 1 million rows.
| Rows | SATA Drive | SSD Drive | Total time Ratio | 1000 time ratio |
|---|---|---|---|---|
| 122,000 rows | Query OK, 1000 rows affected (0.13 sec) Records: 1000 Duplicates: 0 Warnings: 0 +-------------------------+--------+ | seconds_diff | 122000 | +-------------------------+--------+ | 31 | 122000 | +-------------------------+--------+ 1 row in set (0.00 sec) | Query OK, 1000 rows affected (0.08 sec) Records: 1000 Duplicates: 0 Warnings: 0 +-------------------------+--------+ | seconds_diff | 122000 | +-------------------------+--------+ | 13 | 122000 | +-------------------------+--------+ 1 row in set (0.00 sec) | 2.3 | 1.6 |
| 715,000 rows | +-------------------------+--------+ | seconds_total | 715000 | +-------------------------+--------+ | 1819 | 715000 | +-------------------------+--------+ 1 row in set (0.00 sec) Query OK, 1000 rows affected (4.96 sec) Records: 1000 Duplicates: 0 Warnings: 0 |
+-------------------------+--------+ | seconds_total | 715000 | +-------------------------+--------+ | 353 | 715000 | +-------------------------+--------+ 1 row in set (0.00 sec) Query OK, 1000 rows affected (1.18 sec) Records: 1000 Duplicates: 0 Warnings: 0 | 5.1 | 4.2 |
| 1 million rows | Query OK, 1000 rows affected (4.46 sec) Records: 1000 Duplicates: 0 Warnings: 0 +-------------------------+---------+ | seconds_diff | 1000000 | +-------------------------+---------+ | 3188 | 1000000 | +-------------------------+---------+ 1 row in set (0.00 sec) | Query OK, 1000 rows affected (1.40 sec) Records: 1000 Duplicates: 0 Warnings: 0 +-------------------------+---------+ | seconds_diff | 1000000 | +-------------------------+---------+ | 743 | 1000000 | +-------------------------+---------+ 1 row in set (0.00 sec) | 4.2 | 3.1 |
Execute the following in the MySQL cluster for the SSD drive and then later for the normal drive and then compare the times. Also, download my insert python script. I wrote it up very quick. It isn't that elegant.
Insert_200_megs_random.py > insert1.sql bin/mysql -u root -S instances/mysqlnode1/tmp/mysql.sockInside the mysql client program
tee insert1.log source insert1.logHere's the output of my dmesg, if this helps.
[ 1.338264] sata_promise 0000:00:08.0: version 2.12 [ 1.338294] sata_promise 0000:00:08.0: PCI INT A -> GSI 18 (level, low) -> IRQ 18 [ 1.352185] scsi0 : sata_promise [ 1.352328] scsi1 : sata_promise [ 1.352388] scsi2 : sata_promise [ 1.352430] ata1: SATA max UDMA/133 mmio m4096@0xf7a00000 ata 0xf7a00200 irq 18 [ 1.352434] ata2: SATA max UDMA/133 mmio m4096@0xf7a00000 ata 0xf7a00280 irq 18 [ 1.352436] ata3: PATA max UDMA/133 mmio m4096@0xf7a00000 ata 0xf7a00300 irq 18 [ 1.672036] ata1: SATA link up 1.5 Gbps (SStatus 113 SControl 300) [ 1.707733] ata1.00: ATA-8: ST31500341AS, CC1H, max UDMA/133 [ 1.707736] ata1.00: 2930277168 sectors, multi 0: LBA48 NCQ (depth 0/32) [ 1.763738] ata1.00: configured for UDMA/133 [ 2.080030] ata2: SATA link up 1.5 Gbps (SStatus 113 SControl 300) [ 2.088384] ata2.00: ATA-7: OCZ-VERTEX 1275, 00.P97, max UDMA/133 [ 2.088387] ata2.00: 125045424 sectors, multi 16: LBA48 NCQ (depth 0/32) [ 2.096398] ata2.00: configured for UDMA/133 [ 2.252082] isa bounce pool size: 16 pages [ 2.252207] scsi 0:0:0:0: Direct-Access ATA ST31500341AS CC1H PQ: 0 ANSI: 5 [ 2.252323] sd 0:0:0:0: [sda] 2930277168 512-byte hardware sectors: (1.50 TB/1.36 TiB) [ 2.252342] sd 0:0:0:0: [sda] Write Protect is off [ 2.252345] sd 0:0:0:0: [sda] Mode Sense: 00 3a 00 00 [ 2.252370] sd 0:0:0:0: [sda] Write cache: enabled, read cache: enabled, doesn't support DPO or FUA [ 2.252449] sd 0:0:0:0: [sda] 2930277168 512-byte hardware sectors: (1.50 TB/1.36 TiB) [ 2.252462] sd 0:0:0:0: [sda] Write Protect is off [ 2.252464] sd 0:0:0:0: [sda] Mode Sense: 00 3a 00 00 [ 2.252487] sd 0:0:0:0: [sda] Write cache: enabled, read cache: enabled, doesn't support DPO or FUA [ 2.252492] sda: sda1 sda2 sda4 [ 2.282713] sd 0:0:0:0: [sda] Attached SCSI disk [ 2.282781] sd 0:0:0:0: Attached scsi generic sg0 type 0 [ 2.282842] scsi 1:0:0:0: Direct-Access ATA OCZ-VERTEX 1275 00.P PQ: 0 ANSI: 5 [ 2.282924] sd 1:0:0:0: [sdb] 125045424 512-byte hardware sectors: (64.0 GB/59.6 GiB) [ 2.282938] sd 1:0:0:0: [sdb] Write Protect is off [ 2.282941] sd 1:0:0:0: [sdb] Mode Sense: 00 3a 00 00 [ 2.282963] sd 1:0:0:0: [sdb] Write cache: enabled, read cache: enabled, doesn't support DPO or FUA [ 2.283011] sd 1:0:0:0: [sdb] 125045424 512-byte hardware sectors: (64.0 GB/59.6 GiB) [ 2.283024] sd 1:0:0:0: [sdb] Write Protect is off [ 2.283026] sd 1:0:0:0: [sdb] Mode Sense: 00 3a 00 00 [ 2.283049] sd 1:0:0:0: [sdb] Write cache: enabled, read cache: enabled, doesn't support DPO or FUASome proc info
gt;more /proc/scsi/sg/device_strs ATA ST31500341AS CC1H ATA OCZ-VERTEX 1275 00.P DVDRW IDE1008 0055For more info on SSD:
As a side note, SLC SSD drives last 10 times longer for writes comapared to the MLC SSD drives, from what I understand. Thus, the Intel x25-e is far more important than the Intel x25-m for database servers. You want the drives to last as long as possible and have the best random write performance. On one of my contracting jobs, because I showed them how the Vortex behaved on my home computer, I will get to test an Intel x25-e at their place. That's the second time when I invested in my computer at home it helped me in my career. The first time was getting an AMD 64 bit system before most companies had it and using it at home with Linux and MySQL. The ex complained it was a waste of money, but it was a hell of an impressive thing to say at the time during interviews that I had 64 bit Linux and MySQL running at home, and it proved to be true. If you get a good raise because you show initiative when investing money into your home equipment to prove something, it pays for itself.
Talkback: Discuss this article with The Answer Gang
 Mark leads the Ubuntu California Team. You can reach him at
[email protected] .
Mark leads the Ubuntu California Team. You can reach him at
[email protected] .
By Anderson Silva and Steve 'Ashcrow' Milner
Remember how tabbed browsing revolutionized the web experience? GNU Screen can do the same for your experience in the command line. Screen allows you to manage several interactive shell instances within the same "window". By using different keyboard shortcuts, you can shuffle through the shell instances, access any of them directly, create new ones, kill old ones, and attach and detach existing ones.
Instead of opening up several terminal instances on your desktop or using those ugly GNOME/KDE-based tabs, Screen can do it better and simpler.
Not only that, with Screen you can share sessions with others and detach/attach terminal sessions. It is a great tool for people who have to share working environments between work and home.
By adding a status bar to your screen environment, you are able to name your shell instances on the fly or via a configuration file called .screenrc that can be created in the user's home directory.
Installing screen on a Fedora system is quite easy with yum, assuming you have root access.
Login as root:
su - # enter root password
Use yum to install it:
yum install screen
On Debian based distributions like Ubuntu:
As root:
apt-get install screen
Enter your password. After a few minutes (depending on your network connection), Screen will be installed. But before you start playing around with it, let's look at how to do some basic configuration.
Screen keeps its configuration file in the same vein that many applications do: in a dot file in your user's home directory. This file is aptly named .screenrc. In my experience, most people use ~/.screenrc to do two things:
The lines below are numbered for reference. Your config file should not have numbered lines.
1 hardstatus alwayslastline
2 hardstatus string '%{= kG}[ %{G}%H %{g}][%= %{=kw}%?%-Lw%?%{r}(%{W}%n*%f%t%?(%u)%?%{r})%{w}%?%+Lw%?%?%= %{g}][%{B}%Y-%m-%d %{W}%c %{g}]'
3
4 # Default screens
5 screen -t shell1 0
6 screen -t shell2 1
7 screen -t server 2 ssh me@myserver
On lines 1 and 2, you are setting the hardstatus. Line 1 makes the hardstatus always show up as the last line. Line 2 is what will be shown in the hardstatus line. In this case you will see something like this at the bottom:
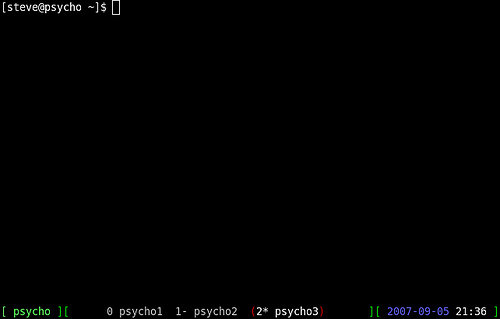
As you change screens, you will see the parentheses move around the active screen.
Line 4 is a comment, as it starts with #. Lines 5-7 are all screen statements in the following format:
screen -t NameOfScreen ScreenNumber ShellCommand
The following are some of the most commonly used shortcuts that let you navigate through your screen environment. Note that unless modified by your .screenrc, by default every screen shortcut is preceded by Ctrl+a. Note also that these shortcuts are case-sensitive.
You can learn more about shortcuts in Screen's man pages. In your terminal, run:
man screen
Another great application of Screen is to allow other people to login to your station and to watch the work you are doing. It is a great way to teach someone how to do things in the shell.
Note: Screen has to be SUID if you want to share a terminal between two users. SUID allows an executable to be run with the privileges of the owner of that file, instead of with the user's own privileges. There are some security concerns when doing this, so use this tip at your own discretion.
First, as root:
chmod u+s /usr/bin/screen chmod 755 /var/run/screen
Log out of root, and run Screen as the user who is going to share the session:
screen
Under your new screen session:
Press Ctrl+a, then type ':multiuser on' and press Enter.
Press Ctrl+a, then type ':acladd $username'
Where $username is the username of the person who will connect to your screen session.
Now that a screen session is being shared by following the previous steps, let's attach ourselves to the session and watch it by connecting to the machine via ssh and entering the following command:
screen -x $username/
Where $username is the username of the person who is sharing the screen session, and yes, you do need slash (/) at the end of the command.
And now both the users (from the host and guest) will be sharing a screen session and can run commands on the terminal.
Let's say you have a screen session open at work with X number of windows on it. Within those screens you may be running an IRC client, an SSH connection to the web server, and your favorite text-based email client. It's 5 p.m. and you have to go home, but you still have work left to do.
Without Screen you would probably go home, VPN into your company's network, and fire up all the shells you need to keep working from home. With Screen, life gets a little easier.
You can simply SSH into your workstation at work and list your available screen sessions with the command:
screen -ls
And connect to the sessions you were running at work with the command:
screen -x screen_session_name
This way screen will let you pick things up exactly from where you left off.
Once you get used to the shortcuts in GNU Screen, not only will your desktop become more organized (due to the lower number of open windows), but your efficiency as a developer or system administrator will increase not only at work but at your home office as well.
Talkback: Discuss this article with The Answer Gang
![[BIO]](../gx/authors/silva.jpg)
Anderson Silva works as an IT Release Engineer at Red Hat, Inc. He holds a BS in Computer Science from Liberty University, a MS in Information Systems from the University of Maine. He is a Red Hat Certified Engineer working towards becoming a Red Hat Certified Architect and has authored several Linux based articles for publications like: Linux Gazette, Revista do Linux, and Red Hat Magazine. Anderson has been married to his High School sweetheart, Joanna (who helps him edit his articles before submission), for 11 years, and has 3 kids. When he is not working or writing, he enjoys photography, spending time with his family, road cycling, watching Formula 1 and Indycar races, and taking his boys karting,
Steve 'Ashcrow' Milner works as a Security Analyst at Red Hat, Inc. He is a Red Hat Certified Engineer and is certified on ITIL Foundations. Steve has two dogs, Anubis and Emma-Lee who guard his house. In his spare time Steve enjoys robot watching, writing open code, caffeine, climbing downed trees and reading comic books.
These images are scaled down to minimize horizontal scrolling.
Flash problems?All HelpDex cartoons are at Shane's web site, www.shanecollinge.com.
Talkback: Discuss this article with The Answer Gang
Part computer programmer, part cartoonist, part Mars Bar. At night, he runs
around in his brightly-coloured underwear fighting criminals. During the
day... well, he just runs around in his brightly-coloured underwear. He
eats when he's hungry and sleeps when he's sleepy.
The Ecol comic strip is written for escomposlinux.org (ECOL), the web site that supports es.comp.os.linux, the Spanish USENET newsgroup for Linux. The strips are drawn in Spanish and then translated to English by the author.
These images are scaled down to minimize horizontal scrolling.
All Ecol cartoons are at tira.escomposlinux.org (Spanish), comic.escomposlinux.org (English) and http://tira.puntbarra.com/ (Catalan). The Catalan version is translated by the people who run the site; only a few episodes are currently available.These cartoons are copyright Javier Malonda. They may be copied, linked or distributed by any means. However, you may not distribute modifications. If you link to a cartoon, please notify Javier, who would appreciate hearing from you.
Talkback: Discuss this article with The Answer Gang
More XKCD cartoons can be found here.
Talkback: Discuss this article with The Answer Gang
I'm just this guy, you know? I'm a CNU graduate with a degree in physics. Before starting xkcd, I worked on robots at NASA's Langley Research Center in Virginia. As of June 2007 I live in Massachusetts. In my spare time I climb things, open strange doors, and go to goth clubs dressed as a frat guy so I can stand around and look terribly uncomfortable. At frat parties I do the same thing, but the other way around.
These images are scaled down to minimize horizontal scrolling.
All "Doomed to Obscurity" cartoons are at Pete Trbovich's site, http://penguinpetes.com/Doomed_to_Obscurity/.
Talkback: Discuss this article with The Answer Gang
Born September 22, 1969, in Gardena, California, "Penguin" Pete Trbovich today resides in Iowa with his wife and children. Having worked various jobs in engineering-related fields, he has since "retired" from corporate life to start his second career. Currently he works as a freelance writer, graphics artist, and coder over the Internet. He describes this work as, "I sit at home and type, and checks mysteriously arrive in the mail."
He discovered Linux in 1998 - his first distro was Red Hat 5.0 - and has had very little time for other operating systems since. Starting out with his freelance business, he toyed with other blogs and websites until finally getting his own domain penguinpetes.com started in March of 2006, with a blog whose first post stated his motto: "If it isn't fun for me to write, it won't be fun to read."
The webcomic Doomed to Obscurity was launched New Year's Day, 2009, as a "New Year's surprise". He has since rigorously stuck to a posting schedule of "every odd-numbered calendar day", which allows him to keep a steady pace without tiring. The tagline for the webcomic states that it "gives the geek culture just what it deserves." But is it skewering everybody but the geek culture, or lampooning geek culture itself, or doing both by turns?
René Pfeiffer [lynx at luchs.at]
On Sep 25, 2009 at 1317 -0700, Rick Moen appeared and said:
> I offer the following anecdote in belated celebration of National > Punctuation Day (http://www.nationalpunctuationday.com/) -- which was > September 24th, 2009, but we can hope that it'll prove to be... um... > periodic.
You might be interested in this little book:
A panda bear walks into a bar and orders a sandwich. The waiter brings him the sandwich. The panda bear eats it, pulls out a pistol, kills the waiter, and gets up and starts to walk out.
The bartender yells for him to stop. The panda bear asks, "What do you want?" The bartender replies, "First you come in here, order food, kill my waiter, then try to go without paying for your food."
The panda bear turns around and says, "Hey! I=E2=80=99m a Panda. Look it up= !" The bartender goes into the back room and looks up panda bear in the encyclopedia, which read: "Panda: a bear-like marsupial originating in Asian regions. Known largely for it=E2=80=99s stark black and white colorin= g. Eats, shoots and leaves."
http://en.wikipedia.org/wiki/Eats,_Shoots_&_Leaves
 ,
René.
,
René.
[ Thread continues here (2 messages/2.18kB) ]
Jimmy O'Regan [joregan at gmail.com]
2009/9/15 Rick Moen <[email protected]>:
> Quoting Jimmy O'Regan ([email protected]): > >> I'll be in San Francisco for a couple of days next month (Google >> Mentor Summit). Will anyone else be around? > > Only all the time. > > Chez Moen is down about 60 km south of the city of San Francisco, > at the base of the San Francisco Peninsula, close to Stanford > University. I don't very often get to San Francisco, but certainly > can/will in order to rendezvous and spend time. >
With less than a week left, I just now took the time to look at a map
and see where I'll /really/ be; turns out it's Sunnyvale, which is
much closer to Stanford
-- <Leftmost> jimregan, that's because deep inside you, you are evil. <Leftmost> Also not-so-deep inside you.
[ Thread continues here (6 messages/5.67kB) ]
Jimmy O'Regan [joregan at gmail.com]
From this Slashdot story: http://hardware.slashdot.org/story/09/10[...]re-Detects-Laptop-User-Presence?from=rss
Software here: http://stevetarzia.com/sonar/
I'm not really interested in the power management side of things so much as the scope it provides for a Halloween prank... Trick or treat!
-- <Leftmost> jimregan, that's because deep inside you, you are evil. <Leftmost> Also not-so-deep inside you.
Jimmy O'Regan [joregan at gmail.com]
Hi. I'm in Sunnyvale now. I think I should be around after 6, if anyone can suggest a good meeting place.
[ Thread continues here (4 messages/7.46kB) ]

![[cartoon]](misc/ecol/tiraecol_en-14.png)
![[cartoon]](misc/xkcd/command_line_fu.png "When designing an interface, imagine that your program is all that stands between the user and hot, sweaty, tangled-bedsheets-fingertips-digging-into-the-back sex.")