Ubuntu Linux is a
Debian
derivative distribution of Linux aimed at being fairly easy for someone new
to the Linux environment - the ordinary user - and having a somewhat
different and thereby hopefully faster version release process. Their
motto is "Linux for Human Beings", and Canonical Ltd. in the UK supports
them professionally.
This image was inspired by the IRC chat clients found in the Ubuntu
default installation (or perhaps their live CD) whose quitline proclaims
"set your system free with Ubuntu!" or something like that. It led an IRC
friend to joke about herds of wildelaptops wandering free across the African
plains...
Did you know that the word "wildebeest" refers to a gnu? Or
that the GNU project's
sourceforge
equivalent is named Savannah?
I found the opportunity to wish everyone a visual "Happy GNU Year" too good
to pass up.
The African herd that this image describes consists of an image from
Dr. Steve Barrett's safari photos
(I hope he doesn't mind) and some pictures of various laptops.
Specifically, this shows an Asus 3300, a Toshiba Tecra 8200, and
clipart of a Powerbook and something more generic. That's right,
kids; Ubuntu has a PPC edition that runs quite nicely on Powerbooks.
I've found that the more generic a laptop, the better Linux's chances
seem to be... but don't hold your breath about any softmodems. The Blue
Wildebeest is a common breed, but the IBM imagery I found didn't seem
to suit the angles I needed.
May your gnu year be just a little more fun than last year...
Heather is Linux Gazette's Technical Editor and The Answer Gang's Editor
Gal.
Heather got started in computing before she quite got started learning
English. By 8 she was a happy programmer, by 15 the system administrator
for the home... Dad had finally broken down and gotten one of those personal
computers, only to find it needed regular care and feeding like any other
pet. Except it wasn't a Pet: it was one of those brands we find most
everywhere today...
Heather is a hardware agnostic, but has spent more hours as a tech in
Windows related tech support than most people have spent with their computers.
(Got the pin, got the Jacket, got about a zillion T-shirts.) When she
discovered Linux in 1993, it wasn't long before the home systems ran Linux
regardless of what was in use at work.
By 1995 she was training others in using Linux - and in charge of all the
"strange systems" at a (then) 90 million dollar company. Moving onwards, it's
safe to say, Linux has been an excellent companion and breadwinner... She
took over the HTML editing for "The Answer Guy" in issue 28, and has been
slowly improving the preprocessing scripts she uses ever since.
Sat, 31 Dec 2005 00:59:27 -0500 (EST)
MXRADAR (MXRADAR from aol.com)
Question by tag (tag from lists.linuxgazette.net)
Answered By Mike Orr,
Jimmy O'Regan,
Pedro Fraile P�,
Jay R. Ashworth
I recently set up a machine with Suse 9.2 and would like to go online with
it. I purchased a Creative Labs Model DE-5621
Serial Modem to use with it but am in need of some kind of AOL emulator to
be able to tie in to the AOL servers. In experimenting with the machine, I can
hear it dial out and attempt connection but that's about it. Any
suggestions/souce for this emulation software. Thanks.
[Sluggo]
I haven't heard of any AOL client software for Linux. If it doesn't
work with the standard 'ppp' package, you may have to try another
dialup ISP and access AOL through its website. If you're having
trouble with your ppp configuration, post what configuration you have
and what exactly you hear from the modem. You should hear a steady
tone from both sides, then it will go up and down in pitch, then turn
into a hissing sound. But the speaker may be configured to shut off
at an earlier point.
I think ppp also has a debug mode that will show all the communication
with the server. That may provide a clue where it's blocking.
[Jimmy]
I don't think AOL works with straight ppp. Heather mentioned a package that did what the querent is looking for a while back, but the closest I can find is this comment from Ben: "I have not yet run into an ISP to which I couldn't connect (AOL is neither an ISP nor anything that I want to connect to; I'd hate to wash my modem out with soap...)"
The best I can remember is that the site was mostly in French, and the name (shockingly) had something to do with penguins.
[Pedro]
Looking into the Ubuntu repositories for something related to AOL, I
have found "penggy". The
package page
shows
connects to AOL via modem or TCP/IP
The project aims to be a full AOL client including all known access
methods like DSL, cable, TCP/IP or modem (with the modem-emulation of
linux via /dev/ttyI* ISDN, too).
Currently, only TCP/IP and modem is supported.
Please bear in mind I have never tried it, nor know really anything
about AOL ...
[Jay]
AOL connectivity uses PPPoE. If you're stuck behind one with a Linux
box, get a compatible router and use that to provide (NATted) IP over
Ethernet.
If you want an AOL client for Linux...
well, a version of AOL 5 ported to Linux leaked out the door, and I
have a copy once, but I can't find it now, and I can't remember what it
was called.
[Jimmy] Does anyone out there have experience with penggy, or the version of AOL
5 Jay mentioned?
wav files from MR8 recorder
Tue, 15 Nov 2005 17:21:29 -0700
Bob van der Poel (bvdp from uniserve.com)
Question by The Answer Gang (tag from lists.linuxgazette.net)
Answered By Jimmy O'Regan
Hi all. A bit of a "forgot my thinking hat" problem here....
I recently purchased a Fostex MR8 digital recorder. I'd not try to go
into the recording business with this toy, but for playing around a home
with multitrack recording it's a fair bit of fun.
This unit records onto compactflash cards, which I can load onto my
linux box from a card reader. No problems here.
And, a program like audacity can read, modify and mix them. Again no
problem.
Unless the track is just a partial track with an offset. For example
(see the adl file below), I have recorded some tracks from the start of
the song. But, 2 tracks are just a little segment in the middle of the song.
I know that wav files can have offsets in them (I think), but it seems
from looking the the wav file headers that this isn't so here. And,
audacity certainly doesn't find the offset.
So, when I load all 5 tracks into audacity tracks 1 and 2 are aligned to
the start of the song. They should really start about 40 seconds in. I
can move the tracks in the program, but I'll never get them aligned.
[Jimmy]
About 42 seconds in? Look at the end of the entries:
00.00.42.05L0244 00.01.26.08L0254 _
^^^^^
My guess is the second time field is the length of the track.
Yes, I think that is correct. I have no idea what the stuff after the
"L" is.
[Jimmy]
Pan settings, maybe, or volume?
Thanks for offering to look up the wav stuff. I'm thinking that if I can
get this figured out it'd be easy enuf to write a little program to
"fix" the files as they are copied from the CF card. Right now I'm
copying all the files, including some junk files. But, it'd be easy to
read the text file for the filenames, etc.
[Jimmy]
Ecasound would probably be better than Audacity for this: it's a
command-line based multitrack editor: http://eca.cx/ecasound
But, wait, the MR8 seems to keep track of stuff in a file. I think that
the data in the <EVENT_LIST> section is what I need to look at. But, I'm
not sure just what the different fields mean. Anyone with some
experience here?
I do know that the files MR80009.WAV, MR80003.WAV and MR80004.WAV are
recording of the complete song and MR80011.WAV and MR800012.WAV are
partials.
Guess what I'm asking is help in modifying the 2 files to push them into
the correct position.
[Jimmy]
I'll get back to you on that. I can't think of it off the top of my
head, and it's too late to look now, but I'll look at it tomorrow.
[Jimmy]
Doh! Use the time shift tool (the one that looks like this: <->
and
drag the tracks into place. IIRC, if you set a mark on the timeline
before you import the tracks it'll put them at that time.
Yes, I tried that but was unable to align the 2 to the point of making
it sound okay. One track was just a bit late or early. Maybe my mouse is
to shakey. Unfortunately there doesn't appear to be anything to "align"
to. And, even if I got this working once, I'd have to have to do a 2nd
time
[Jimmy]
There is a zoom tool...
Linux as a Windows screensaver
Thu, 22 Dec 2005 21:16:14 +0000
Jimmy O'Regan (The LG Answer Gang)
Question by The Answer Gang (tag from lists.linuxgazette.net)
It uses qemu to boot Linux on a Windows machine. Spiffy.
[Jimmy] Something I've wanted to see ever since I first saw
coLinux
is a screensaver activated configuration of a cluster-enabled coLinux.
Does anyone care to try their hand at writing an article about this, or
some other unusual way of getting Linux running under Windows?
USB MIDI
Thu, 08 Dec 2005 16:56:08 -0700
Bob van der Poel (bvdp from uniserve.com)
Question by The Answer Gang (tag from lists.linuxgazette.net)
Answered By Thomas Adam
Hey, I was going to send a message about how pleased I was with my
newest toy that "just worked" ...
Got a MIDIsport UNO midi interface. This plugs into a USB port and
drives a MIDI keyboard. Got it and plugged it in and (to someone really
expecting to do a bunch of manual editing of config files) I found that
the alsa drivers found it, registered, etc.
Cool! Now I have a 2nd midi port.
Then I decided to clean up some cable runs and powered off the computer.
When I rebooted, the new MIDI port was gone. Huh??? Checked the
cables...and listed /proc/bus/usb/devices ... yes, all there. But, ALSA
doesn't know about it.
So, I plugged the MIDIsport in and out ... and it works again.
So, ALSA finds it on hotplug, but not boot. What's going on?
BTW, to this point I have not edited any config files
[Thomas]
Order of operations, most likely. It's likely that ALSA is loading
after hotplug has finished, which means it might not be aware of the
device. You can restructure your init sequence, or simply recall
/etc/init.d/hotplug to rerun at the end of init, assuming this really is
the reason.
That was my first guess. And I've done a bit of testing, etc. and have
discovered that the device is found and registered at boot. The
interesting part is that if I use alsamixer right after boot it shows
the MIDI-Uno-USB device (alsamixer is just grabbing info from
/proc/asound/cards). But, the device is NOT there to use. Trying to use
it generates an error; and 'aconnect' doesn't show it.
[Thomas]
What error?
bob$ aplaymidi -p72 midifile.mid
Cannot connect to port 72:0 - Invalid argument
Not the most helpful
But, the port isn't there, so it makes sense.
However, plugging the unit in/out again shows it up.
I'm wondering if a modprobe to something might force a registration. I
did try 'modprobe usb-midi' but no results there.
[Thomas]
No results where? modprobe, if it is successful won't return any
output. It's 'lsmod' that will help you here.
I was hoping that modprobe might reset something?
Okay, doing a lsmod before and after the little guy is working does show
up something which might point to the problem:
Really, just the difference in all this is that the 'audio' module has
been added.
Also, there is a file /proc/asound/cards which does not change between
no-work and work:
cat /proc/asound/cards
0 [AudioPCI ]: ENS1371 - Ensoniq AudioPCI
Ensoniq AudioPCI ENS1371 at 0xec00, irq 10
1 [Interface ]: USB-Audio - USB Uno MIDI Interface
M-Audio USB Uno MIDI Interface at
usb-0000:00:10.1-1, full speed
Finally, the file /proc/asound/card1/midi0 has changed from being an
empty file to:
bob$ cat midi0
USB Uno MIDI Interface
Output 0
Tx bytes : 197
Input 0
Rx bytes : 0
More thoughts?
BTW, on Mandriva 2006 there is NO /etc/init.d/hotplug I have no idea
when this stuff is being done. I think there might be some clues in
/etc/hal/device.d
Tue, 03 Jan 2006 14:58:11 +0530
J.Bakshi (hizibizi from spymac.com)
Question by tag (tag from lists.linuxgazette.net)
Answered By Rick Moen,
Thomas Adam
Hi list,
does any one of you have the information about the H/W requirement of recently
released KDE 3.5 ??
It makes no sense speaking of KDE 3.5 having particular hardware
requirements, since it is a suite of software running at a level
far above the level of hardware drivers. If you mean "What's a
reasonable minimum amount of RAM to have, so that a default
configuration of KDE on Linux will seem OK?", then the answer is
probably around 256MB, which is based on experience with earlier
releases, but with the knowledge that it doesn't seem to change a lot
between releases.
[Thomas]
Not to mention that this was answered in a thread on TAG a few issues ago --
asked by Mr. Bakshi himself. :|
If it helps, the KDE website does have a
requirements page
but this refers to compilation requirements.
response to article on scanning
Thu, 29 Dec 2005 05:10:55 +0100
Edgar Howell (Edgar_Howell from web.de)
Question by editor at Linux Gazette (editor from linuxgazette.net)
My article on scanning drew responses from a couple of readers, one,
Emil Gorter, who copied you and whose suggestion I find well-done
and certainly worth making available for those wanting to archive
scans.
And Juhan Leemet politely pointed out that XSANE does, indeed,
have the function that I really wanted for use as a copier. He
had a problem with it that he hadn't had time to resolve and I
then had the same for which I did find a work-around. It is
tantamount to using your brakes instead of taking your foot off
the gas, so I don't want to suggest it to anyone.
But the bottom line is that using XSANE to copy directly from scanner
to printer can work quite nicely.
ech
Scanning and file-size
Fri, 16 Dec 2005 19:15:45 +0100
Emil Gorter (emil from ripe.net)
Question by lg (lg from howell.de)
Hi Edgar,
I read your article http://linuxgazette.net/121/howell.html and it
reminded me of a problem I had faced. For my work I had to figure
out a way to scan and store contracts digitally.
The file-size issue was quite interesting with ++6000 pages to go
I found that creating PDFs is quite easy, and gives very good
results. Nice quality, great reduction in size. Example:
By the way, for practical reasons the scans were made with a Windows
machine.. Still have to try SANE myself someday.
I hope this helps!
Emil Gorter
"Summer of Code" projects list updates
Tue, 08 Nov 2005 06:39:48 +0000
Jimmy O'Regan (The LG Answer Gang)
Question by ()
First of all, I would like to offer my most sincere apologies for the
negative way I portrayed the WinLibre installer projects. What I took to
be a duplication of effort was in fact three separate parts of a larger
system. Thanks to Noemi Tojzan for providing this corrected project list:
Finished projects:
- installer (2 students)
- updater (1 student)
- control centre (1 student)
- MacLibre (1 student)
- 3 -original- games (3 students, 1 per game)
- Final Touch (or Image Manipulation Tool) (1 student)
Failed projects:
- CDRoast GUI (1 student)
There were also inaccuracies in my list of Wine's projects. Thanks to
Kai Blin for providing a corrected list:
Mozilla integration (that was correct)
Theming support (correct, too)
Force feedback support for dinput (this is more precise)
Single sign-on authentication using NTLM and other SSPI protocols
(NT-style authentication isn't quite this. Samba does that, not wine)
wire-compatible DCOM (no code, correct)
Active Server Pages (dropped, correct)
Thanks to Patrick Walton for a list of LiveJournal projects:
OpenID modules and plugins
Schools attended system
FotoBilder client
S2 DHTML IDE
Thanks to Meredith Patterson for pointing out that I had (originally)
listed Charun mistakenly instead of QBE
(http://pgfoundry.org/projects/qbe), to Ivan Beschastnikh for providing
the correct title to the Internet2 project I had listed as "User-space
transport": FB-FR-CCCP (http://fb-fr-cccp.sourceforge.net), to Jimmy
Cerra for pointing out two Semedia projects: SWAPI
(http://swapi.ourproject.org) and SPARQL for various RDF databases
(http://sourceforge.net/projects/sparql), and to Anil Ramnanan for
pointing out an Apache project: an Eclipse plugin for Apache Forrest.
Thanks to Ross Shannon for pointing out these Gallery projects:
Flash based theme
DHTML SLideshow theme
User Integrations Tasks
Duplicate Image Detection
I owe a rather sheepish apology to Oleg Paraschenko, one of the
Google-mentored students: I had found XSieve, but lost the details
when it came time to write my article. Oleg has more than made up for this:
Wed, 28 Dec 2005 17:43:27 +0100
Karl-Heinz Herrmann (khh from khherrmann.de)
Question by The Answer Gang (tag from lists.linuxgazette.net)
Hi I'm working on my Laptop again after a long while during which
it was just sitting in the corner. I found something in the old draft
folder -- And I've no idea if that ever got sent. So here you go....
Oh and a happy new year to everybody.
K.-H.
On Tue, 25 May 2004 09:38:38 -0400
Ben Okopnik <[email protected]> wrote:
> I'm writing to you because you're the "quiet bunch" :)
thanks
I was following the "linuxgazette.net down" thread with half
an eye.
> Right at the moment, we've got a TAG discussion going on where I've
> asked for input from everybody on the above topic. To restate it,
> I'm looking at ways to bring LG onto a parallel course with Linux
> itself: the OS is booming, but we're lagging. From my own perspective,
> I see a need to modernize a bit; to consider the types of people now
> entering the world of Linux (corporate and business users) and to
> address their needs. "Amateur Linux user" does not, these days, mean
> "amateur computer user".
lets start with history: I started out in TAG when many questions came
it on general install questions like partition setup, lilo tricks to
make it work, lost root passwords. As TAG is no newsgroups with expiring
articles after some time we had perfect in depth solutions to everything
in this category of FAQ. The level of discussion in TAG was slowly
moving up in complexity and/or detail of a particular problem. I got the
feeling even before the com->net switch that there is a little
stagnation in worthwhile topics and things I/we can answer. At the
beginning there were questions e.g. on network setup on a level I could
join in at least answering in part. It's quite a while that I've seen a
question I had any chance answering.
Others have suggested finding out wher new and current Linux users and
LG readers are and pick them up at their level and target their
interests. Pretty good idea, but I rarely use a GUI so I can not speak
of first hand experience. I just installed the brand new SuSE 9.1 which
came along with a collection of spiffy K* applications from Mind mapper
to notes keeping and e.g. GTKtalog to catalog CD contents. Important
to me right now as I've a growing CD collection in CD storage bags and I
spend more and more time searching for a particular one. Well -- I read
in a bunch of CD's, program crashed twice so I pressed the save button
frequently. GUI interface is nice, pop in CD press a button, CD content
is archived. Next CD. A few days later I tried to open the archive --
program segfaults. I've still the XML export of the data.... rather
unreadable without a conversion program/frontend. My next try will
certainly be a bunch of "ls -R" files which I can grep. But it seems
this kind of solution is nothing we can sale to "the new TAG reader" as
they want "aesthetic solutions" as sombeody put it.
I agree with that analysis BTW: from talking to people either having a
Linux on some second partition to considering installing one, they want
the perfect solution, GUI, everything away only a few mouse clicks. And
they want pretty looking neat applications for everything.
My problem with that is: I don't have the answers, as the "nice neat
applictions" might not be there or at least I don't know of them. There
might be a need of new TAG/article writers for a new type of readers.
So the task at hand might be to attract new members to LG writing for
these new readers.
Many topics I was concerned with lately (Wlan, AMD64) are highly
specific, involve kernel patches and or/special distributions which are
not suitable for new comers to Linux.
Which leads me to a little question anyway: Is LG to be for newbies?
An idea anyway: By talking to people (here in Germany that is) more and
more are annoyed about the spam flood. It might hit here slightly
delayed compared to US, or maybe not. Well I was searching a bit for Win
solutions as all of them run WinXX. No luck with freeware or even open
source (portable, cygwin) solutions. So my standard answer is getting
"well, since you won't consider Linux pay up for a commercial spam
filter".
An article on how to use a Pentium classic PC from the attic and turn it
into a Spamfilter-firewall in a recipe (starting out at the point where
you insert a knoppix or install CD) might be interesting to some people.
This page edited and maintained by the Editors of Linux Gazette HTML script maintained by Heather Stern of Starshine Technical Services, http://www.starshine.org/
$? holds the exit status of the last process: zero for success, non-zero
for failure; $PS1 is the primary prompt.
It's \$(smiley) because you want bash to evaluate it every time:
$(smiley) would just evaluate it at the time you set the variable, as
would putting the contents of the smiley function into PS1
\h is the shorthand for \$(hostname)
[Ben]
Darn it, Jimmy, you always beat me. What, you have a fast connection or
something?
[Jimmy]
My connection, in "the cheque is in the mail" speed is 115.2 Kbps, so no.
Mike Zheng (mail2mz from gmail.com)
Question by tag (tag from lists.linuxgazette.net)
Answered By Lew Pitcher
Hi All,
For a program, the BSS contains un-initialized variables, Data contains
initialized variables. Why do we want to separated these two categories of
variables?
[Lew]
It's an optimization thing. If each binary contained an image of 'data' that
included the uninitialized variables, then the binary would be larger in size
than if the image did not include uninitialized variables. If you don't map
these variables to your 'load image' (the contents of the binary), but
instead, map them to memory at execution time, your binaries can be smaller
without a loss of functionality.
The 'typical' (conceptual) memory map (once a program has been loaded into
memory) looks something like this...
(on most implementations, CODE is kept in a separate address space from
DATA/BSS/heap/stack)
Heap 'grows' up from the end of BSS towards the highest address
Stack 'grows' down from the highest address towards the end of the BSS
Heap allocation code keeps a boundary between the top end of the heap and the
bottom end of the stack.
The 'loadable' part of the binary is the CODE and DATA part. BSS is how the
loader accounts for the room needed to hold the uninitialized data.
Some program clear the BSS by itself, is it necessary?
[Lew]
A mere convenience, nothing more.
HTH
email issue
J.Bakshi (hizibizi from spymac.com)
Question by tag (tag from lists.linuxgazette.net)
Answered By Jimmy O'Regan,
Rick Moen
Hi list,
At first I wish you all a very ******HAPPY NEW YEAR******.
Here is a technical query. Frequently I get some advertisement-emails with
EMPTY "form" header & EMPTY "to" header. Even the "detail-header-view" of
sylpheed-claws can't show any header information. What is the technology
which makes this possible and how can we prevent such emails ?
[Jimmy]
The technology that makes this possible is called [drumroll]... SMTP!
To see how it works, use telnet:
$ telnet smtp.o2.ie 25
220 smtp1.o2.ie -- Server ESMTP (Sun ONE Messaging Server)
MAIL FROM: [email protected]
250 2.5.0 Address Ok.
RCPT TO: [email protected]
250 2.1.5 [email protected] OK.
DATA
354 Enter mail, end with a single ".".
From:
To:
Subject: Test
A test
.
250 2.5.0 Ok.
QUIT
221 2.3.0 Bye received. Goodbye.
Now, I check my mail. In Mozilla Mail, it shows up as this:
What'll be interesting now will be to see how many mail apps that use mboxes are broken by that }
[Rick]
J.Bakshi's other question was:
...how can we prevent such emails ?
The answer is [drumroll]... don't use SMTP e-mail.
Or alter your receiving SMTP server's filtering rulesets to reject or drop
incoming mails not meeting certain technical requirements, including
possession of key header lines. Generally, this requires running your
own SMTP host (mail tranfer agent) -- rather like A.J. Liebling's dictum
that freedom of the press is limited to those who own one.
Thanks to both Rick Moen and Jimmy O'Regan for their explanation. Jimmy's
answer is a bonus as he explained through a good practical example. I have
just come to know mixmaster. Though haven't gone through its documentation
yet, but aptitude show mixmaster shows that it can prevent the recipient
knowing your email address.
[Rick]
Er, you might have a use for mixmaster, but the preceding discussion
didn't seem to suggest that, and I fear that you might be
misunderstanding its intended purpose.
Mixmaster is a client-server software tool for people running MTAs (SMTP
machines), and their users, with the client piece allowing the users to
issue pseudonymous e-mails, which the mixmaster daemon (server) piece then
remails on their behalf.
It would be very strange to send your routine, normal outgoing mail
through Mixmaster, specifically because it would greatly obscure the
identity of the sender. Further, and more to your original point, it
would do nothing to prevent you from also receiving spammer-and-malware
generated junkmails at your real e-mail address, such as the garbage
mail you cited that had a couple of null interior headers.
As Ben knows, I've long been of the opinion that pretty much all "hide
from spammers" strategies (including, well, "preventing the recipient
knowing your address") are a dumb idea, really don't work worth a damn,
and interfere with legitimate Internet usage to a degree I find
unacceptable. At least for those of us who control our own MTAs, there
are effective countermeasures, that don't involve self-concealment in
any way.
Thanks Rick. You have provided a short as well as good article on Mixmaster &
its application ( I may be permitted to say for beginners ). Now I can
under stand that as a Workstation owner ( and not an MTA) I don't need
Mixmaster. Thanks again.
Running isoLINUX from a REALLY old machine
R.M.Deal (deal from kzoo.edu)
Question by tag (tag from lists.linuxgazette.net)
Answered By Ben Okopnik
I just read the enlightening article Booting Knoppix from a USB Pendrive
via Floppy by Ben Okopnik from the #116 issue of the LINUX gazette.
[Ben]
Well, thank you for the compliment - and I'm glad you enjoyed the
article.
I have a similar problem but with an older machine, a Toshiba Satelite Pro
410 CDT, for which I have an external floppy drive.
My problem is that the BIOS does not give me the option of booting from
a CD. I can boot from either the hard disk or from the floppy.
[Ben]
Have you looked for a BIOS update? I'm not saying that one is definitely
available, but if it is, then that would be the simplest solution. Take
a look at Toshiba's site and see if there's a download available.
Great suggestion. I shall do that.
Now while I found one article on booting Knoppix from floppies, I
wonder if it would be a big deal to modify the script developed by
Ben to produce a Knoppix boot, not for a USB pen drive (this portable
has NO USB port) but from a floppy. By the way, the Toshiba has
installed as an operating system Windows 95 and has only 16 M of RAM so
running even KNOPPIX may be a challenge.
[Ben]
The problem is that, shortly after I wrote the article, the information
in it became outdated: the next release of Knoppix had a minimum size
for the kernel/modules/etc. that was much too large to fit on a floppy.
However, for your application, there's an easy answer - or at least used
to be (I don't have a Knoppix CD handy to check): just fire up your
Wind0ws, look at the Knoppix CD, and there should be a batch file there
called "mkfloppy.bat". Run it; after it writes a boot floppy for you,
simply reboot, leaving both the floppy and the CD in the machine.
Well, almost. I could not get anything under my Windows boot on the
portable (a laptop only if you have strong
quadriceps) so I booted my LINUX system (suse 9.3) with KNOPPIX and
couldn't find a mkfloppy.bat there.
[Ben]
That wouldn't have helped anyway, since all the commands in the batch
file are DOS programs.
Right, but I could not find the batch file from W95 or suse.
However,
in a file knoppix-cheatcodes.txt, the procedure to handle floppy boot
only is described, using a LINUX command in KNOPPIX named
mkbootfloppy. However, when I boot with KNOPPIX, I can find no such
file, only a mkboot. That mkboot command looks
right but when I run it with an installed blank floppy, after writing on
the floppy drive, I get an error message, in German. Now
I am living now in Germany (Weimar) and am taking a course in German but
I do not have the resources to fully translate
technical German.
[Ben]
Whoops... Perhaps you could post that error? My technical German has
risen above zero (in part, due to Knoppix
, and there are several
German-speaking folks here who could help.
OK. Attached is a script of what happened when I tried to produce the
boot floppy. It was interesting
making the script in KNOPPIX and transferring it to
/mnt/hda2/home/ralph/ after mounting /mnt/hda2.
Please note that I am working with Knoppix V3.8.1 (2005/04/0
. I am
not updating
right now because I cannot get DSL in Weimar despite having it in Munich
and so am
having to use ISDN (hence my switch from Fedora to Suse) in which I can
get no flat rate!
Once DSL is available ("tomorrow"), I'll update my version.
Script wurde gestartet: Mo 21 Nov 2005 10:21:56 CET
root@4[~]# mkboot
Insert a floppy diskette into your boot drive, and press <Return>.
Creating a lilo bootdisk...
cp: Schreiben von ,,/tmp/boot15663/vmlinuz": Auf dem Ger�t ist kein Speicherplatz mehr verf�gbar
root@4[~]# exit
Script beendet: Mo 21 Nov 2005 10:23:11 CET
[Ben]
"No space left on device". At least the version with the umlauts, etc. -
"Auf dem Ger�t ist kein Speicherplatz mehr verf�gbar" - means that.
Seems that it's not all that uncommon: searching the Net produces a
number of hits. It seems that in some cases, this is produced by bad
floppies - but in other cases, it's a result of bad communication with
an external floppy drive.
I'd suggest making the floppy from your Wind0ws, just to see
if it works. Having two OSes can be handy for resolving "is it hardware
or software?" questions.
I plan on working on deciphering that error message
but meanwhile I took the floppy that resulted from that action and tried
to boot my portable with it. Unfortunately, it only booted into W95;
it seems the boot floppy is faulty. You referred to two floppy disks
and so did the cheatcodes.txt file but there was no prompt to put in a
second floppy. It may be time for me to contact the programmer
of KNOPPIX directly to see what the problem is. I'm guessing that the
cheatcodes.txt file was written for an earlier version of KNOPPIX and
doesn't describe the procedure correctly for the new version. Did I say
LINUX was fun??
[Ben]
Sure. Part of the fun is the ability to make things happen that aren't
the norm.
Second, related, question: does anyone recommend a version (old if
necessary) of LINUX that would work well as the operating system on the
Toshiba?
If these are in some FAQ, I'd appreciate a link.
[Ben]
I find that Puppy Linux (http://www.goosee.com/puppy) works well on
older machines, although I haven't done a broad range of experimentation
with it; it has a nice desktop and a sufficient range of installed
applications that I don't find it restrictive. Other folks here may have
other suggestions.
This is really an on-going issue from my post regarding urlview and the
logging of URLs. I've since decided to take a different approach, and thus
far this method works quite nicely. I'm now using 'multi-gnome-terminal'
(MGT), 'multitail', 'gmrun', plus a helper script. The overall aim of all of
this, was to be able to:
Capture URLs from various #channels that I am in (done via irssi already).
Open the up in a web browser.
You might wonder what's so hard with this -- the problem is that
X11-forwarding on my server takes forever -- it is only a poor P166 with 64MB
of RAM, after all. The irssi session resides on the server, so I needed a
way of pseudo-opening the URLs as though the request originated on my
workstation.
It's unfortunate that I have to use MGT, since it is a memory hog, but needs
must. I use it because that has the ability to automatically hotlink URLs --
so that actions can be assigned to it when they're clicked on. Based on this
premise, filling in the gaps was easy.
I mount my server's filesystem via 'shfs' -- which I'm now using as a
replacement for NFS. I really like it (and a lot less buggy than lufs, and
its ilk). This way, I can use multitail to keep an eye on that file. The url
logging script that I use from irssi, is "url_log.pl" [1]. All of the logged
entries are in the format:
Sat 10 Dec 2005 00:57:08 GMT nick #chan URL
... and I wanted multitail to colourise the output, as it does for other
files. That was easy -- just create a new colourscheme for it in
/etc/multitail.conf:
So to break this down a bit, remember a typical entry from this file will look
like:
Sat 10 Dec 2005 00:57:08 GMT nick #chan http://myfoo.com
Hence: "Sat 10 Dec 2005" will appear in green. "00:57:08 GMT" in magenta,
and the rest of the line will appear in whichever colour is matched by the
channel the URL was quoted in. So, it looks pretty.
scheme:urllog:/mnt/home/n6tadam/.irssi/urls/url
... should obviously be changed to match whichever file is going to hold the
urls from the url_log,pl script.
The next stage was to determine what happens when I clicked on a URL (I say
click -- the shortcut to opening a URL via MGT is 'CTRL + middleclick'). I
didn't want everything to be sent to my browswer. This is where the "gmrun"
utility comes in useful [2]. For those of you that have never used it, it's a
very handy, and customisable tool. One of the features it has, is pre-defining
prefixes for certain applications. So for instance, I could enter into gmrun:
man:bash
... and depending on what I had told gmrun to do with the 'man' prefix, it
would open up the bash man page. Neat, eh? So I wanted to have a separate
program to open up images, and URLs (it's quite often the case that people
post links to screenshots, that I don't want to open in a browser, but would
just rather 'see'). I needed to use a helper script to do this, as gmrun
accepts no command-line options. The trick I used (in order to make it
appear directly in the gmrun window, as though I had typed it), was to append
it to gmrun's history file --- if set correctly, gmrun will display the last
entered command. No biggie, here it is:
(Saved as ~/bin/runvia.sh -- and chmod 700 ~/bin/runvia.sh)
So, I'm able to flag to gmrun that if the URL I am clicking on is an image,
then tell it so, else, flag it to open up in elinks (this is my primary
browser -- although I wanted a specific handler for it.) But in order for
that script to process the URL that we clicked on from MGT, we need to tell
MGT to perform that action. This is easier than you'd think, and involves
editing the file: $HOME/.gnome/Gnome, such that:
default-show=runvia.sh "%s"
Going back to gmrun, we lastly need to tell it what acrtion to take for the
'elinks:' and 'image:' prefixes. That information is stored in /etc/gmrunrc,
although I copy this to ~/.gmrunrc, personally, and edit it, so that for the
image handler:
URL_image = sh -c 'feh %s'
('feh' has the ability to read images via http).
And for the elinks handler:
URL_elinks = sh -c '${TermExec} elinks -remote "%s" && FvwmCommand "All (*ELinks*) FlipFocus"'
"${TermExec}" is a variable defined further up in the file that looks like
this:
Terminal = rxvt
TermExec = ${Terminal} +sb -ls -e
... and that's it. It seems to be working really well.
Since I use FVWM, I wanted to (when I had decided to click on a URL) to focus
the webbrowser -- hence the reason why I'm using FvwmCommand. This is
optional of course. Although to continue on a similar theme, the style of
the "gmrun" dialogue window is set to the following:
Style Gmrun GrabFocus
.. so that when it pops up, I can hit enter, knowing that the Gmrun window
will always have the focus, to execute whatever is inside it.
You can see a screenshot[3] of the url-logger in action.
Hope someone finds this useful, or can derive other ideas from it.
I was just showing this to Heather. I've been trying to figure out
what's going on with our strange California weather (tropical rainstorms
for the past two weeks) and decided that moving satellite images were
more interesting than static ones. Among other discoveries, we've been
getting a tropical express mainlined to us over the Pacific for the past
several weeks, and the movies make this very apparent.
There are two parts to this tip: first, you want to start grabbing
satellite images as they're available, then you want to string them
together to view them. Updates are 30 minutes and 3 hours for regional
and hemispheric views, respectively.
For the fetch, I use cron to schedule downloads, storing them in a
large local area, 'data/weather', with a timestamp added to the
filename. Recipie, add to your personal crontab:
There's some cleanup you may need to do as the download images
occasionally get out of order. I've found deleting duplicates seems to
fix this pretty readily.
You can also experiment with image enhancements via ImageMagick, such as
increasing size and contrast, and reducing noise, in the downloaded
images.
This page edited and maintained by the Editors of Linux Gazette HTML script maintained by Heather Stern of Starshine Technical Services, http://www.starshine.org/
The Answer Gang
Linux Gazette 122: The Answer Gang (TWDT)
...making Linux just a little more fun!
The Answer Gang By Jim Dennis, Jason Creighton, Chris G, Karl-Heinz, and...
(meet the Gang) ...
the Editors of Linux Gazette...
and You!
We have guidelines for asking and answering questions. Linux questions only, please.
We make no guarantees about answers, but
you can be anonymous on request. See also: The Answer Gang's
Knowledge Base
and the LGSearch Engine
Yes. But the documentation in the Linux kernel says that the kernel has
support for DirectPad joysticks, using gamecon module.
[Peter]
Yes, "gamecon" is likely the right module to use.
So I think I don't
have to compile the package provided in the abovementioned pages..
[Peter]
True. Still, they're useful in that they combine
the userland tools and the kernel drivers all in
one place with some guides and FAQ and other such.
It gives a good starting point, and from there you
can work on the specific issues of the 2.6 kernel,
once you know how to get the device to work correctly
in a plain 2.4 kernel.
And I'm still confused, because the package in these pages use different
filename.
[Peter]
Yes, well filenames change over time, code hardly
changes all that much.
For example, Linux kernel uses joydev.c, but in these pages it is
joystick.c. And for DirectPad joysticks, Linux kernel uses gamecon.c, while
in these pages it is joy-console.c.
[Peter]
Those would have been the names during
the 2.4 series kernel.
I have been Googling and found that the Linux kernel actually
have support on it. And then I found several documentation in the Linux
kernel, but I always fail :(
[Peter]
What did you try, and how did it fail,
specifically?
cd /dev
rm js*
mkdir input
mknod input/js0 c 13 0
mknod input/js1 c 13 1
mknod input/js2 c 13 2
mknod input/js3 c 13 3
ln -s input/js0 js0
ln -s input/js1 js1
ln -s input/js2 js2
ln -s input/js3 js3
[Peter]
Well, those entries would be created by udev
if you were using a 2.6.12 or later kernel,
once the module was loaded correctly.
It seems, though, that the module "gamecon" isn't
loading for some reason. Perhaps because it isn't
finding the parallel port device? Or because the
parallel port is being used by another module
(have you checked that "lp" module isn't loaded)?
Are you sure the parallel port is enabled in the
BIOS? Do you happen to have a parallel port printer
and test that printing works OK, or some other way
to know if the parallel port is actually enabled?
You mentioned the joystick worked in Microsoft but
it wasn't clear if it was on the same machine.
But every reboot, my js* is always gone
How can I fix it?
[Peter]
Not sure about that, could be many reasons.
It's no harm to create the devices manually,
but unless the module is loaded successfully
they will just give ENODEV when you try to use them.
root@devel:/home/i2c# modprobe joydev
root@devel:/home/i2c# modprobe gamecon
FATAL: Error inserting gamecon
(/lib/modules/2.6.8-2-386/kernel/drivers/input/joystick/gamecon.ko): No such
device
[Peter]
Have a look in "dmesg" to see if there's any
other messages.
Also, can you see anything mentioning "parport"
in your boot messages, if so can you send it,
e.g.:
parport: PnPBIOS parport detected.
parport0: PC-style at 0x378 (0x778), irq 7, using FIFO
[PCSPP,TRISTATE,COMPAT,ECP]
That would tell you the IRQ line to look for in
/proc/interrupts corresponding to the parallel port.
I've tested on 2.4 and 2.6 series, but no difference...
[Peter]
Hmm, so it looks like more debugging will be needed.
Have a look in the sources, you can add in some
printk(KERN_INFO along the path from module_init(gc_init);
so add in some tracing of gc_init and see why
the gc_probe function isn't happy. You should see
your debug additions come out in "dmesg" when
you modprobe gamecon and you can keep adding
more debug tracing and doing rmmod gamecon and
modprobe gamecon to try again. Be careful though
with your code, as you're likely to crash your
kernel sometimes doing this sort of thing.
Can you explain step-by-step how to configure the kernel to work with this
joystick? I use Debian 3.1 and kernel 2.6.18.
[Peter]
I wouldn't have the same hardware as you,
so I couldn't provide a step-by-step guide.
My guess woiuld be that the joystick stuff
might be easier to get to work using a 2.4
series kernel rather than 2.6 series.
I haven't been following the development in
the 2.6 series much on joysticks.
My sound card (Intel i810 onboard) doesn't work on 2.4, so I have to use the
2.6 series :(
[Peter]
Well, it is still worthwhile to learn how (or even
if) the device will work with the 2.4 kernel driver,
even if you can't listen to music while you're
doing the investigation :)
But sounds like it doesn't work in 2.4 as you say,
so easiest to debug what's going on using 2.6 for
now.
[Peter]
Could you try instead:
modprobe gamecon map=0,1
Looking in ./drivers/input/joystick/gamecon.c
it seems it needs the parallel port number and
the pad number. I'm guessing that would be
counting from 1, but maybe it should be map=0,0
module_param_array_named(map, gc, int, &gc_nargs, 0);
MODULE_PARM_DESC(map, "Describers first set of devices
(<parport#>,<pad1>,<pad2>,..<pad5>)");
Solved!
First I had to remove lp module. I also stopped CUPS services because my
printer is connected via parallel port.
[Peter]
Thanks, I didn't think of stopping CUPS :)
In 2.4 kernel, I try:
#modprobe gamecon gc=0,7
where 0 means parallel port 0, and 7 means that it is a Playstation joystick.
[Peter]
the "map=0,7" would be what to use for 2.6,
judging from the sources they mention that
the "gc=" parameter is deprecated.
When I tried to play xgalaga using my joystick, the ships did some strange
movement.
[Peter]
Instead of tying a game directly, could you
try to build the "jstest" and "jcal" programs
if you don't have them already. From the README in the download
mentioned before:
...............
2.5 Verifying that it works
For testing the joystick driver functionality, there is the jstest
program. You run it by typing:
jstest /dev/js0
And it should show a line with the joystick values, which update as you
move the stick, and press its buttons. The axes should all be zero when the
joystick is in the center position. They should not jitter by themselves to
other close values, and they also should be steady in any other position of
the stick. They should have the full range from -32767 to 32767. If all this
is met, then it's all fine, and you can play the games. :)
If it's not, then there might be a problem. Try to calibrate the joystick,
and if it still doesn't work, read the drivers section of this file, the
troubleshooting section, and the FAQ.
2.6. Calibration
For most joysticks you won't need any manual calibration, since the
joystick should be autocalibrated by the driver automagically. However, with
some analog joysticks, that either do not use linear resistors, or if you
want better precision, you can use the jscal program
jscal -c /dev/js0
...............
Maybe it still need some configuration or it's a bug in the kernel
(the documentation in 2.4 kernel says that support for Playstation joystick
is still under development).
[Peter]
Well, to debug we'd need a better description
of the symptoms than "ships did some strange
movement in xgalaga", I mean any kernel
developer would probably find that quite
insuffuicient :)
But I'm quite happy to see that my Linux box is now more fun with joystick
support :)
I haven't had time to try this on 2.6 kernel. Anyway thanks very much for the
help :)
[Peter]
Could be that in 2.6 the driver would read
more frequently from the parport than in
2.4, resulting in a more responsive joystick,
so it could be worth a try. Especially to
get sound to work at the same time, as you
mentioned.
LN -- have I gone brain dead?
From Bob van der Poel
Answered By: Breen Mullins,
Thomas Adam,
Ben Okopnik
I'm trying to do something pretty simple, I thought, and am near the
"tear out my hair" stage ... All I want to do is to create a symbolic
link to an existing directory:
bob$ ln -s tmp foo
bob$ ls -l foo
lrwxrwxrwx 1 bob bob 3 Dec 1 15:21 foo -> tmp/
No, foo is not a link to tmp. Well, it sort of is
bob$ file foo
foo: symbolic link to `tmp'
But,
bob$ ls foo
foo@
[Breen]
It looks like you're somehow passing -F -d to the ls command.
What does 'alias ls' tell you?
Oh, that was easy! Here I've been struggling trying to get the *&*(^ ln
command to work and it was working all along! Yup, ls was aliased:
alias ls
alias ls='ls -F --color=auto'
Guess how quickly I'm going to fix that! Dumb, dumb, dumb. Don't know
who .. the packager who snuck in the -F or me :)
[Breen]
Moral: always check for aliases.
[Ben]
For some of us - those who have their "mv", "cp", and
"rm" aliased to automatically use "-i", for example - it's the automatic
response (sticking, say, 'rm' into a 'for' loop doesn't work too well if
you're going to get asked "Are you sure?" for a couple hundred files.)
However, there's other stuff of this ilk in shells that can really drive
you nuts. In the past, I've been tripped up by looking for programs that
didn't exist (they turned out to be functions that the sysadmin put in
/etc/profile), have been driven almost insane by CDPATH ('cd foo' would
go to '/usr/local/foo/bar/zotz/qux/argle/bargle/will/this/never/end/foo'
instead of ./foo), and have become Quite Annoyed by per-directory source
files - although '.exrc' isn't really a shell-related gadget. But still.
:)
The Daemons of Unix are wily, subtle, and enjoy sucking out your
brains through your ears if you let them. They're also a very strange
shade of mauve with green dots, so avoid the psychedelic drugs and all
will be well. Intoxicants and computing do NOT mix well... remember,
never drink and derive.
[Breen]
Fedora Core 3 (in a fit of complete brain-death) shipped with
vi unconditionally aliased to /usr/bin/vim.
[Ben]
Gaah! I've run into similar idiot's handiwork on a Solaris system -
although, to be fair, it was the local sysadmin who perpetrated this
one. He had set root's $SHELL to "/usr/bin/bash" - 'cause, y'know, "sh"
is just so annoying (and .profile is just some stupid thing that
nobody ever uses anyway, right?) The, one fine morning, the "/usr" slice
failed to mount...
[Breen]
I've just taken another look at this -- at some point Fedora fixed the
bug. /etc/profile.d/vim.sh now looks like this:
if [ -n "$BASH_VERSION" -o -n "$KSH_VERSION" -o -n "$ZSH_VERSION" ];
then
[ -x /usr/bin/id ] || return
[ `/usr/bin/id -u` -le 100 ] && return
# for bash and zsh, only if no alias is already set
alias vi >/dev/null 2>&1 || alias vi=vim
fi
which is much more reasonable behavior. As originally shipped the
two tests after then were missing.
[Breen]
Which doesn't matter much until you're trying to repair a
system which doesn't have /usr/ mounted (because you borked
/etc/fstab when tweaking your partitioning scheme).
Remembering to type /bin/vi is easier when you're not sweating
bullets.
doesn't give me a listing of the contents of tmp. Ummm, what am I doing
wrong here?????
[Thomas]
Nothing. Although you should qualify which directory you created the
link in. Indeed, what does:
ls -l ./foo
produce as output? Indeed, did you do that the right way around?
% ln -s /tmp foo && ls ./foo
System V or BSD?
From Adam S Engel
Answered By: Thomas Adam,
Rick Moen,
Mike Orr
I was hunting down a "fugitive" process and accidently hit the BSD
command ps aux (thinking it was an accident because I'm using Mandriva,
which I thought was based on System V)
[Thomas]
In terms of Init level structures then it is, yes.
and received something like this:
~ 495 --> ps aux | head -5
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.0 1560 476 ? S Nov30 0:00 init [5]
root 2 0.0 0.0 0 0 ? SN Nov30 0:00
[ksoftirqd/0]
root 3 0.0 0.0 0 0 ? S< Nov30 0:00 [events/0]
root 4 0.0 0.0 0 0 ? S< Nov30 0:00 [khelper]
But then, just for the hell of it, I hit the System V command, ps -ef
and got this:
I thought most Linuxes, particularly the "big ones" like Fedore, Debian,
SuSE, Mandriva, were based on System V.
[Thomas]
They are, but the ps command is an oddity in that sense. Still useful,
though.
Even so, my MacOSX, based
loosely on BSD, will not accept the ps -ef command. Can a system
(Mandriva in this case) be comprised of both?
[Rick]
All modern Unixes (except *BSD, which are holdouts) are the result of
(or inspired by) a shotgun marriage of those two cultures (plus SunOS),
called System V R4, released by AT&T in 1988. Quoting from the Unix FAQ:
From SVR3: sysadmin, terminal I/F, printer (from BSD?),
RFS, STREAMS, uucp
From BSD: FFS, TCP/IP, sockets, select(), csh
From SunOS: NFS, OpenLook GUI, X11/NeWS, virtual memory
subsystem with memory-mapped files, shared libraries
(!= SVR3 ones?)
ksh
ANSI C
Internationalization (8-bit clean)
ABI (Application Binary Interface -- routines instead of
traps)
POSIX, X/Open, SVID3
Even prior to that, retrofitting "BSD enhancements" onto System V-based
systems was a nearly ubiquitous customisation: Sys V R4 simply
acknowledged that reality, bowing to the technical community's mandate.
The general architectural description of Sys V R4 got abstracted out as
the POSIX.1 specification, which served as the blueprint from much of
what Torvalds and co. (and FSF, and others) then performed in building up
what today we call GNU/Linux systems: Linux distributions generally are
an independent implementation of (most of) the POSIX spec, which in turn
was based largely on Sys V R4. And so, here we are.
The rc.init files seem,
from what I recall from Redhat, to be System V.
[Sluggo]
See "man ps". The 'ps' Linux uses has two sets of command-line
options to please everybody. There are also verbose long options, and
two sets of output formats.
Linux generally follows the System V "style" but deviates whenever it
feels like it.
[Rick]
And System V wasn't exactly System V, any more, after SysV R3. ;->
SysV R4 was, after all, one of computing biggest exercises in
syncretism.[1]
[Jimmy] The footnote is missing, but I assume it was to contain a definition
of syncretism:
Attempted union of principles or parties irreconcilably at
variance with each other.
[Rick]
Amen to that. Back when there was a Caldera Systems, Inc. (remember them?),
they kept trying to get Torvalds to accept a huge patch to add the
System V "STREAMS" interproces I/O system. Torvalds turned them down
flat, repeatedly, saying (and I paraphrase): "Why would we need that
bloatware in our kernel, when Berkeley sockets already do that same job
at least as well?"
[Sluggo]
The init
system is not part of "Linux" (the kernel) but is chosen by each
distribution. Most distros use System V style, and even those that
don't like Slackware have compatibility directories so that
vendor-compiled commercial programs can be installed without too much
hassle. However, the init strategy is one of the most varying things
between distributions.
I just got a new Dell
Dimension basic "cheap" no-frills computer, but still, it's 80 gigs of
hard-drive space are far more than i need, so I'm installing SuSE,
Mandriva, and a third. It was going to be Debian, but now I'm thinking
of FreeBSD. Can anyone tell me the major difference between FreeBSD and
Linux?
[Rick]
Speaking in very broad terms, FreeBSD was designed and is maintained by
people who never liked AT&T Unix or any of its derivatives and
independent reimplementations at all, and who thus were unsatisfied by
the System V R4 compromise. Of course, that's hardly all there is to
it: If you'd been sued, more or less baselessly, by a Fortune 500
corporation for copyright infringement, you'd probably develop an
attitude problem, too.
The difference in init scripts, you know about. A minority of Linux
distributions have offered BSD init scripts, too, all along, e.g.,
Slackware, for those who like them.
Additionally, there are such a large number of other small but
significant architectural differences that I cannot hope to remember
them all.
The BSDs tend to favour a "BSD slice"-type partition map, as opposed to
the IBM/Microsoft-style partition map more typical of Linux systems
(at least on IA32/x86-64). Their directory layout is a bit different,
not very close to the Filesystem Hierarchy Standard promoted by the
Linux community. They tend to use variants on UFS as their main
filesystem. (FreeBSD favours a variant called FFS = Fast Filesystem,
incorporating Marshall Kirk McKusick's softupdates instead of
journaling. Softupdates are a clever and effective way to get most
of journaling's advantages in protecting metadata following crashes or
power loss -- but sadly does nothing about the problem of long fsck
times after such events.)
They tend not to have anything resembling /proc. They favour csh over
Bourne variants such as bash. They favour nvi over vim. They default
to use of the wheel group (which Linuxes usually lack mostly because
Stallman at FSF doesn't like the concept). In general, their prejudices
tend to come across to Linux users as a bit old-fogey-ish.
They offer both binary packages plus a very successful build-from-source
architecture called the "ports" system. The closest thing to the latter
on Linux would be Gentoo's portage and the GAR build system (and similar
things in other build-from-source Linux distros).
They have their own libc (not based on GNU's, as Linux always has been)
and their own implementation of make. Otherwise, a lot of the userspace
toolsets are literally exactly the same (except compiled to a different
ELF binary format).
Spend some time reading "The FreeBSD Handbook", online: It's a landmark
in clarity for technical documentation, and worth reading on that basis
alone.
I've heard that FreeBSD is known for its security and other
network capabilities.
[Rick]
FreeBSD is not especially known for security. (You might be thinking
of OpenBSD.) I would say that it best known for scalable network
performance under heavy load, and for stability. It's also known for
having relatively narrow scope of hardware compatibility (i.e., driver
selection), compared to Linux, and for relatively slow and conservative
development: You may or may not find FreeBSD 6.0-STABLE's driver
support for your new Dell Dimension's chipsets to be adequate.
Specific comparisons of FreeBSD with typical Linux systems have been
done repeatedly, but tend to have the problem of being out of date
(which doesn't stop people from alluding to them, out of ignorance).
E.g., often-heard claims about better FreeBSD VM performance rely on
Linux 2.4.x results, back when Linux had a real problem, there. For
that matter, Linux's entire TCP/IP stack has been thrown out and
rewritten four or five times during the kernel's history, so you can
imagine the large opportunity for outdated comparisons, there.
It used to be the case that FreeBSD's SCSI subsystem gave significantly
better performance than that of the Linux kernels, but I suspect that
difference, too, has been eliminated. What probably does remain is the
matter of NFS/autofs/amd: If you're a heavy NFS user, you'll find that
FreeBSD's NFSv3 implementation still has fewer bugs than Linux's, though
the gap is pretty small by now.
[Sluggo]
Some people say BSD's network stack can handle a higher load.
At that time, Walnut Creek CD-ROM set the world record for most bytes of
network traffic processed in 24 hours by a single host: One
single-processor PII box (a then-famous FreeBSD ftp server) handled 1.39
terabytes. (This burst of traffic was, ironically, occasioned by the
release on that machine of Slackware 4.0.)
Fast-forward: About a year ago, I helped build what became the
second-fastest computational cluster in the world, "Thunder", a set of
1024 quad-Itanium2 Linux boxes. The interconnects for node-to-node
data passing used Quadrics cards, and I don't have figures handy but it
was a stupendous level of network traffic.
[Sluggo]
But
both systems are widely used in high-performance mission-critical
situations, so the difference is a bit academic. Isn't Linux being
used for rocket control somewhere?
Linux comes in a wide variety of flavors from user-compiled hacker
systems (Gentoo) to turnkey Windows clones (Linspire), with RPM/DEB
distros in between. BSD sticks to the user-compiled route.
[Rick]
Misconception. It's actually probably more common, in practice, to
install software from the binary packages than to build it from ports.
I can tell you that BSD admins will often resource to packages when
there are local build problems, if nothing else.
[Sluggo]
BSD also
tends to have less support for new hardware, and last time I checked
it had an incompatible disk-partitioning scheme, making dual booting a
problem.
[Rick]
FYI: FreeBSD (at least) is perfectly happy booting from an
IBM/Microsoft-style partition table. For that matter, you can boot
Linux (but not MS-Windows) from a BSD "slice"-style disklabel.
[Sluggo]
But if a user-compiled distro appeals to you and you like
the BSD traditions, FreeBSD would be worth looking into. That seems
to be the most popular one for new users, although NetBSD and OpenBSD
are also free and would be worth comparing.
Answered By: Jimmy O'Regan,
Neil Youngman,
Peter Knaggs
All of a sudden, lots and lots of stuff - including 'vi' - is crashing when I try to bring it up. The error message I get is "error while loading shared libraries: libpangocairo-1.0.so.0: cannot open shared object file: No such file or directory".
Worst of all, grepping the Debian ls-lR doesn't show any such thing - and searching the Net has lots of people having the same problem and not being able to find a package that contains it.
This is not sounding good.
Folks, if any of you could take a look in your /usr/lib (that's where 'strace' tells me these progs are looking for it) and send me a copy of your libpangocairo-1.0.so.0 - assuming that somebody somewhere has it - I'd be very grateful. Meanwhile, I'm quite annoyed and puzzled - how the heck can so much stuff depend on a lib that's not available???
Sigh. I hope I don't end up having to reinstall my entire system. That would be a really, really big problem while I'm on the road.
Update: I've found an RPM that contains libpangocairo - presumably, it's
something near what I need. Converting it wasn't useful, since it was
going to put the files into a different directory - so I just copied out
the files and put'em into /usr/lib.
Result: well, I've got Vim, Mozilla, and Firefox back. On the other
hand, "mdh" (my MailDoHickey from Freshmeat that I've been using for a
year or more) segfaults; so does "gqview".
My best guess as to the cause of this: earlier, I did an "apt-get
update" and "apt-get dist-upgrade", and I recall seeing "libc" (and a
few other libs) go flying by in the list of installed packages. If
that's what it is, then I'm a bit shocked: I've never had Debian break
my install before, simply via an update.
More tomorrow, since it's almost 2a.m. here.
[Jimmy]
New version of gvim? Pango is Gnome's framework for internationalised
text (bidi, strange fonts, etc.), Cairo is a vector drawing library
(like DPS or Apple's Display PDF (Quartz?)). All text in Gtk is now
rendered through Pango, so everything that depends on Gtk in any way is
going to depend on it.
It doesn't seem to be in Debian yet.
Ah. I see.
A few days ago, the maintainer of Jpilot got back to me about a bug that
I'd filed, and asked me to recompile Jpilot from source with the latest
libpisock library. However, Debian's "official" method of creating a
package from source is this nightmarish chase of dependencies, all
alike... and Gtk+, Cairo, Pango, and a few other things (all from pretty
much the same place - the gtk.org FTP server.)
However, everything worked OK back then - including the new version of
JPilot. Something in the recent update must be conflicting with the
"cutting edge" libs.
It still isn't looking good. I've tested a few other GTK-based apps -
gtkpool, gtksee, gtop - and they work, although gtop throws out a
cryptic warning:
glibtop: glibtop_get_swap (): Client requested field mask 0001f, but
only have 00007.
I have no idea what all those libs may have overwritten. Fixing it is
going to take some thought. :|
[Jimmy]
Um... specifically, the Cairo backend for Pango doesn't seem to be in
Debian yet, though Pango is.
So, now that I'm actually awake, and possess a functioning brain -
in contrast to last night - I have a plan of attack that should let me
get past all this bull with the grace of a matador (and without using
OLE even once.)
1) Pick a bunch of GTK-based apps and run each one. Add those that fail
to a list. Then:
for app in $list
do
ldd `which $app` |perl -wlne's/^.* => (\S+) .*/$1/;/gtk|pango|cairo/&&print'>>list.txt
sort -uo list.txt list.txt
done
while read n; do readlink $n; done < list.txt
This should give me a list of all the relevant libs - running this for
'mdh' and 'gtk-gnutella' already shows some promise - that may need to
be reinstalled. It may require that I manually remove the offending lib
(sometimes, installing the right version doesn't do anything unless the
old lib is removed), but that shouldn't be too difficult; the list won't
be all that long.
Running the above for 'mdh' and 'gtk-gnutella' shows:
I'm betting that one of those - libgtk-x11-2.0.so.0, anybody? - is the
bugger that's busting my chops. More tests later; gotta run to work NOW.
Update: got it fixed. Most likely.
At least, GTK apps now run without
complaining.
I looked at the list that I got as a result, and ran "dlocate" over the
"root name" bits (everything up to the first '.'); other than the
obvious, most of the rest pointed to libglib2.0-0. I reinstalled it and
removed the newer versions - i.e., the current lib names mostly look
like "libpangoft2-1.0.so.0.801.1", while the newer (broken) ones look
like "libpangoft2-1.0.so.0.1001.0" - and life is good again. Whew.
I'm going to be doing more testing - i.e., by removing "libpangocairo",
which should not be getting pulled in by anything - but it seems all
right now.
[Neil]
There was a neat tip on TAG a while back about the LD_DEBUG environment
variable. I think it could be useful in identifying the exact problem.
neil ~ 15:08:12 501 > LD_DEBUG=help ls
Valid options for the LD_DEBUG environment variable are:
libs display library search paths
reloc display relocation processing
files display progress for input file
symbols display symbol table processing
bindings display information about symbol binding
versions display version dependencies
all all previous options combined
statistics display relocation statistics
unused determined unused DSOs
help display this help message and exit
To direct the debugging output into a file instead of standard output
a filename can be specified using the LD_DEBUG_OUTPUT environment variable.
neil ~ 15:50:43 502 >
Oh, good one! I wish I'd remembered it. I used 'strace' to see what was
going on; unfortunately, it didn't show enough detail to be of use. The
above may well do that; I'll use it to do a little troubleshooting, just
to make sure that this is resolved. Thanks, Neil!
[Peter]
Ulrich Drepper has a quite readable guide to
writing shared libraries, he's been maintaining
it for quite a while now and in Jan 2005
put out this:
http://people.redhat.com/drepper/dsohowto.pdf
It's probably more intended for folks
actually writing shared libs in the first
place, but it's a good one for debugging
For a brief period of time this office had been Windows-free, in
theory at least. The combo printer requiring '95 had stopped using
black ink and '95 had stopped booting, making both obsolete. And
'98 on the old notebook doesn't shutdown properly, which turns
booting into an adventure. Just hadn't quite got around to dumping
all this junk.
Then fate sent a project my way that required some variety of
Windows. The one tool I absolutely need I got familiar with many
years ago under OS/2. Unfortunately it no longer exists in any such
incarnation. So it was time to clench my teeth, say good-bye to
dreams of a notebook completely unexposed to Windows and
order a Dell with whatever is current from Redmond now-a-days.
The Plan
We ordered the Dell with twice the hard-drive and 4
times the memory advertised, so we just reduce the partition a bit
and put SuSE 10.0 on there and be up and running in nothing
flat.
This is something I've done for years. One of my favorite
commercial tools had been Partition Magic. Pretty easy to reduce a
partition in size and use the free space for some other
purpose.
But as Robert Burns put it: The best laid schemes o' Mice an'
Men, Gang aft agley.
The Problem
If in the past I have ever said anything nice about products
from Redmond, I really do regret it. If anything, I have certainly
been far too polite in just using words like "junk". There are
other 4-letter and longer words far more suitable.
Consider: you buy a machine with one pre-installed operating
system on an 80GB drive and cfdisk reports:
Filesystem 1K-blocks Used Available Use% Mounted on
[...]
/UNIONFS/dev/sda1 88136 6654 81482 8% /mnt/sda1
/UNIONFS/dev/sda2 73184104 7132524 66051580 10% /mnt/sda2
/UNIONFS/dev/sda3 4858184 3167052 1691132 66% /mnt/sda3
Why is there more than one primary partition? The hardware
architecture only supports 4, they're valuable! None is
particularly full. And that gap in the middle?! Can we spell
"fragmentation"? Define it?
Maybe people living in the wild and wooly world of Windows are
used to things like this and don't consider it fraudulent when
deprived of about 14GB out of 80. But to have that much real estate
taken away without even asking!? Consider the percentage if I
hadn't chosen a drive twice the size of normal.
Is there any need to point out the bizarre file system types?
And I don't do NTFS!
Tabula Rasa
But it gets better, or worse. Back in '95 days, you got a CD
with the operating system, probably also pre-installed on the
machine.
With '98 the system was pre-installed and you got a so-called
"Recovery CD" along with it. At some point in time you were forced
to use the infernal thing and that was when you learned that it
wouldn't just restore the operating system but would return the
entire partition to the status it had originally had when the
machine left the manufacturer.
Like good-bye data if you don't have adequate back-ups and/or
another bootable partition (this was long before Knoppix). But if
you modified the partition size in order to install something else
as well, the "Recovery CD" fails — after it has formatted the
partition it can't use! And the last Partition Magic I bought
couldn't help because instead of running under DOS it required
Windows. A perverse Catch-22. Been there, done that, wore out the
T-shirt.
But at least you had a CD with the system software on it.
Dell/Microsoft didn't even provide one! Just how expensive are
CD-ROMs today? In bulk?
That's what those other partitions are all about. In other words
it is impossible to do something simple like format the drive,
allocate partitions, and install software. So now what?!
Tools and Toolboxes
In spite of having used other fine tools in the past to work
through problems, Knoppix has become my toolbox of choice because
it gives me an environment I am familiar with, GNU/Linux, and lots
and lots of tools.
Of course the first thing I did — after minimal setup, as
little as possible — was to change the boot sequence on the
notebook to enable using Knoppix. I had to know how to do this (F2,
DEL early in the boot process are good candidates): other than one
large piece of paper (roughly 2-times legal-size) describing the
external features of the hardware, Dell included no significant
printed documentation. It's all on the hard-drive.
Above, you have already seen some of the information available
from use of the tools on the Knoppix CD/DVD. By the way, here I am
using a DVD with Knoppix 4.0.
So far all we have been able to do is to confirm that we have a
major problem. Bizarre HD configuration. Unfamiliar file
system.
So let's see what tools Klaus Knopper included in his
toolbox:
knoppix@3[knoppix]$ apropos NTFS
libntfs-gnomevfs (8) - Module for GNOME VFS that allows access to NTFS filesystems.
mkntfs (8) - create a NTFS 1.2 (Windows NT/2000/XP) file system
ntfscat (8) - concatenate files and print them on the standard output
ntfsclone (8) - Efficiently clone, image or restore an NTFS filesystem
ntfscluster (8) - identify files in a specified region of an NTFS volume.
ntfsfix (8) - tool for fixing NTFS partitions altered by the Linux kernel NTFS driver.
ntfsinfo (8) - dump a file's attributes
ntfslabel (8) - display/change the label on an ntfs file system
ntfsls (8) - list directory contents on an NTFS filesystem
ntfsprogs (8) - several tools for doing neat things with NTFS partitions
ntfsresize (8) - resize an NTFS filesystem without data loss
ntfsundelete (8) - recover a deleted file from an NTFS volume.
smbcquotas (1) - Set or get QUOTAs of NTFS 5 shares
knoppix@3[knoppix]$
Plan B
From looking at a couple of the man pages it would seem that
this collection of tools has been around for 10 years or so, well
beyond release 0.0 by now.
So let's use ntfsclone to push an image of the bootable
partition over the LAN onto another machine. Once we have that as
back-up we can use ntfsresize to shrink the partition down to
something reasonable. After that it should be easy enough to create
an extended partition with a couple of logical partitions for
Linux.
I'm not at all familiar with these tools but it is always fun to
learn something new. And the time is right.
Backing Up
Again, nothing ever quite works the way one expects. Making the
image was no exception. Here is one of the unsuccessful
attempts:
knoppix@3[knoppix]$ su
root@3[knoppix]# ntfsclone --save-image --output - /dev/sda2 | gzip -c | \
ssh -l web lohgopc2 'cat > /DATA/NO_BACKUP/DELL/sda2.img.gz'
ntfsclone v1.9.4
The authenticity of host 'lohgopc2 (192.168.0.102)' can't be established.
RSA key fingerprint is 65:32:cc:81:8f:eb:73:24:7b:b3:18:a8:66:fa:7c:ae.
Are you sure you want to continue connecting (yes/no)? NTFS volume version: 3.1
Cluster size : 4096 bytes
Current volume size: 74940522496 bytes (74941 MB)
Current device size: 74940526080 bytes (74941 MB)
Scanning volume ...
100.00 percent completed
Accounting clusters ...
Space in use : 7304 MB (9,7%)
Saving NTFS to image ...
root@3[knoppix]#
After "Saving NTFS to image ..." nothing further happened and I had to cancel with
CTRL-C.
Here is what finally worked:
knoppix@1[knoppix]$ su
sudo: unable to lookup Knoppix via gethostbyname()
root@1[knoppix]# ntfsclone --save-image --output - /dev/sda2 | gzip -c | \
ssh -l web lohgopc2 'cat > /DATA/NO_BACKUP/DELL/sda2.img.gz'
ntfsclone v1.9.4
Password: NTFS volume version: 3.1
Cluster size : 4096 bytes
Current volume size: 74940522496 bytes (74941 MB)
Current device size: 74940526080 bytes (74941 MB)
Scanning volume ...
100.00 percent completed
Accounting clusters ...
Space in use : 7304 MB (9,7%)
Saving NTFS to image ...
Warning: No xauth data; using fake authentication data for X11 forwarding.
100.00 percent completed
Syncing ...
root@1[knoppix]#
Other than the obvious difference between success and failure,
from a quick glance at the output it isn't clear why one worked and
one didn't. But look at the lines ending in "NTFS volume version:
3.1".
On the unsuccessful attempt I had failed to note that ssh wanted
confirmation that it was OK to establish a connection with the
other machine. It was patiently waiting for me to enter "yes" while
I was scratching my head trying to figure out why nothing was
happening!
Success the next morning — a good night's sleep can do a world
of good — didn't include that question because I had already told
ssh that it was OK and it had "permanently" (until next boot with
Knoppix) recorded this fact. Refreshed and thinking clearly, I
remembered that the password was needed and saw the request from
ssh.
Resizing
Now that our safety-net was in place the first thing to do was
to check out the partition:
knoppix@4[knoppix]$ sudo ntfsresize --info /dev/sda2
sudo: unable to lookup Knoppix via gethostbyname()
ntfsresize v1.9.4
NTFS volume version: 3.1
Cluster size : 4096 bytes
Current volume size: 74940523008 bytes (74941 MB)
Current device size: 74940526080 bytes (74941 MB)
Checking filesystem consistency ...
100.00 percent completed
Accounting clusters ...
Space in use : 7304 MB (9,7%)
Collecting shrinkage constrains ...
Estimating smallest shrunken size supported ...
File feature Last used at By inode
$MFT : 16790 MB 0
Multi-Record : 8393 MB 9
You might resize at 7303708672 bytes or 7304 MB (freeing 67637 MB).
Please make a test run using both the -n and -s options before real resizing!
knoppix@4[knoppix]$
Rather than reducing the partition as far as possible, let's
follow that advice and see what it looks like if we leave some room
for data and the tool that has yet to be installed:
root@0[knoppix]# ntfsresize --no-action --size 10G /dev/sda2
ntfsresize v1.9.4
NTFS volume version: 3.1
Cluster size : 4096 bytes
Current volume size: 74940523008 bytes (74941 MB)
Current device size: 74940526080 bytes (74941 MB)
New volume size : 9999995392 bytes (10000 MB)
Checking filesystem consistency ...
100.00 percent completed
Accounting clusters ...
Space in use : 7304 MB (9,7%)
Collecting shrinkage constrains ...
Needed relocations : 395906 (1622 MB)
Schedule chkdsk for NTFS consistency check at Windows boot time ...
Resetting $LogFile ... (this might take a while)
Relocating needed data ...
100.00 percent completed
Updating $BadClust file ...
Updating $Bitmap file ...
Updating Boot record ...
The read-only test run ended successfully.
OK, go for it.
root@0[knoppix]# ntfsresize --size 10G /dev/sda2
ntfsresize v1.9.4
NTFS volume version: 3.1
Cluster size : 4096 bytes
Current volume size: 74940523008 bytes (74941 MB)
Current device size: 74940526080 bytes (74941 MB)
New volume size : 9999995392 bytes (10000 MB)
Checking filesystem consistency ...
100.00 percent completed
Accounting clusters ...
Space in use : 7304 MB (9,7%)
Collecting shrinkage constrains ...
Needed relocations : 395906 (1622 MB)
WARNING: Every sanity check passed and only the DANGEROUS operations left.
Please make sure all your important data had been backed up in case of an
unexpected failure!
Are you sure you want to proceed (y/[n])? y
Schedule chkdsk for NTFS consistency check at Windows boot time ...
Resetting $LogFile ... (this might take a while)
Relocating needed data ...
100.00 percent completed
Updating $BadClust file ...
Updating $Bitmap file ...
Updating Boot record ...
Syncing device ...
Successfully resized NTFS on device '/dev/sda2'.
You can go on to shrink the device e.g. with 'fdisk'.
IMPORTANT: When recreating the partition, make sure you
1) create it with the same starting disk cylinder
2) create it with the same partition type (usually 7, HPFS/NTFS)
3) do not make it smaller than the new NTFS filesystem size
4) set the bootable flag for the partition if it existed before
Otherwise you may lose your data or can't boot your computer from the disk!
root@0[knoppix]#
Now that we have reduced the size of the area used within the
physical partition (comparable to de-frag under Windows, maybe) it
is safe to use cfdisk /dev/sda
Festplatte: /dev/sda
Größe: 80026361856 Bytes, 80,0 GB
Köpfe: 255 Sektoren pro Spur: 63 Zylinder: 9729
Name Flags Part. Typ Dateisystemtyp [Bezeichner] Größe (MB)
---------------------------------------------------------------------------------------
sda1 Primäre Dell Utility 90,48
sda2 Boot Primäre NTFS [] 10001,95
sda5 Logische Linux ext2 10010,17
sda6 Logische Linux 10001,95
Logische Freier Bereich 14928,89
sda7 Logische FAT16 10001,95
sda8 Logische Linux swap / Solaris 20003,89
sda3 Primäre CP/M / CTOS / ... 4984,52
[ Bootbar] [Löschen ] [ Hilfe ] [ Maxim. ] [Ausgabe ] [ Ende ]
[ Typ ] [Einheit.] [Schreib.]
This was the step where extreme care was called for. A mistake
with ntfsresize produces an error message or warning. To me the
partition table is comparable to the base register in some
assembler languages: something that cannot be verified, a promise,
not a guarantee. Mess it up and you may never be able to recover.
Pay very close attention to the changes you make and back out if
there is anything at all that you don't fully understand!
Finishing Touches
Once again, in the white hat, Linux wins! The backup was
unneeded, although I never would have continued without one.
When booted into Windows, it did whatever it is that it does
while it is doing what it does when one doesn't know what it is
doing. So that worked. I guess.
Creating the extended partition and a couple of logical
partitions inside it is quite straight-forward and doesn't deserve
further discussion here. Although I grew up with fdisk, I will
repeat the recommendation in the documentation to use cfdisk
instead. Interactive and keeping one apprised of current status, it
was very easy to get used to.
Postscript
In retrospect it wasn't necessary to jump back and forth between
normal user and root as in the cut-and-paste from screens, above.
But there is a time and place for each. On more than one occasion I
have failed to notice that I had returned to a virtual terminal
with root privileges. Bad! The preferred idiom with Knoppix is
"sudo". You won't need a root password but it keeps you aware of
where you are and what you are doing.
After having gone through this exercise it occurred to me that a
better long-term solution might be to back up the Windows partition
as described after major changes, i.e. installation of the tool I
need. The other two as well of course, just in case something goes
wrong. And then when the time comes that the Windows partition
becomes unusable and restoring is necessary, just do it from the
network. That should make those other two partitions obsolete and
recover a bunch of disk space. Way down the road.
The modem is presumably one of those nefarious "winmodems". I
didn't check it out, ISDN currently, not analog. The network card
works without problem. And the Kensington Mouse at the USB port was
recognized by Knoppix off the starting blocks. It is really neat,
the cable winds up into it, to the length needed, from 0 to
whatever. I may even take it along when on the road.
The Dell hardware is actually very nice. If you could just get
it without having to pay for an operating system you normally don't
need...
Edgar is a consultant in the Cologne/Bonn area in Germany.
His day job involves helping a customer with payroll, maintaining
ancient IBM Assembler programs, some occasional COBOL, and
otherwise using QMF, PL/1 and DB/2 under MVS.
(Note: mail that does not contain "linuxgazette" in the subject will be
rejected.)
After the last article was published, I have received more than
a dozen requests for a second filesystem benchmark using the 2.6
kernel. Since that time, I have converted entirely to XFS for every
Linux machine I use, so I may be a bit bias regarding the XFS
filesystem. I tried to keep the hardware roughly the same. Instead
of a Western Digital 250GB and Promise ATA/100 controller, I am now
am using a Seagate 400GB and Maxtor ATA/133 Promise controller. The
physical machine remains the same, there is an additional 664MB of
swap and I am now running Debian Etch. In the previous article, I
was running Slackware 9.1 with custom compiled filesystem
utilities. I've added a small section in the beginning that shows
the filesystem creation and mount time, I've also added a graph
showing these new benchmarks. After the first round of benchmarks,
I received a sleuth of e-mails asking for the raw numbers. The
numbers are now included in tables at the end of this e-mail for
both the last and current set of benchmarks.
What's new?
1) Unify the graphs so all but one are the same type.
2) Run tests with a recent distribution and the 2.6.14.4
kernel.
3) Included the ReiserFS Version 4 benchmarks.
4) Included the raw data in matrix form at the bottom of this
page.
5) Included three additional graphs:
a) Creation time to make the actual
filesystem.
b) Time it takes to mount the filesystem.
c) The amount of space available after formatting
with the default options.
001] Create 10,000 files with touch in a directory.
002] Run 'find' on that directory.
003] Remove the directory.
004] Create 10,000 directories with mkdir in a directory.
005] Run 'find' on that directory.
006] Remove the directory containing the 10,000 directories.
007] Copy kernel tarball from other disk to test disk.
008] Copy kernel tarball from test disk to other disk.
009] Untar kernel tarball on the same disk.
010] Tar kernel tarball on the same disk.
011] Remove kernel source tree.
012] Copy kernel tarball 10 times.
013] Create 1GB file from /dev/zero.
014] Copy the 1GB file on the same disk.
015] Split a 10MB file into 1000/1024/2048/4096/8192 byte pieces.
016] Copy kernel source tree on the same disk.
017] Cat a 1GB file to /dev/null.
NOTE1: Between each test run, a 'sync' and 10 second sleep
were performed.
NOTE2: Each file system was tested on a cleanly made file
System.
NOTE3: All file systems were created using default options.
NOTE4: All tests were performed with the cron daemon killed
and with 1 user logged in.
NOTE5: All tests were run 3 times and the average was taken,
if any tests were questionable, they were re-run and
checked with the previous average for consistency.
Creating the Filesystems
EXT2
p500:~# mkfs.EXT2 /dev/hde1
mke2fs 1.38 (30-Jun-2005)
Filesystem label=
OS type: Linux
Block size=4096 (log=2)
Fragment size=4096 (log=2)
48840704 inodes, 97677200 blocks
4883860 blocks (5.00%) reserved for the super user
First data block=0
2981 block groups
32768 blocks per group, 32768 fragments per group
16384 inodes per group
Superblock backups stored on blocks:
32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632, 2654208,
4096000, 7962624, 11239424, 20480000, 23887872, 71663616, 78675968
Writing inode tables: done
Writing superblocks and filesystem accounting information: done
This filesystem will be automatically checked every 34 mounts or
180 days, whichever comes first. Use tune2fs -c or -i to override.
p500:~#
EXT3
p500:~# mkfs.EXT3 /dev/hde1
mke2fs 1.38 (30-Jun-2005)
Filesystem label=
OS type: Linux
Block size=4096 (log=2)
Fragment size=4096 (log=2)
48840704 inodes, 97677200 blocks
4883860 blocks (5.00%) reserved for the super user
First data block=0
2981 block groups
32768 blocks per group, 32768 fragments per group
16384 inodes per group
Superblock backups stored on blocks:
32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632, 2654208,
4096000, 7962624, 11239424, 20480000, 23887872, 71663616, 78675968
Writing inode tables: done
Creating journal (32768 blocks): done
Writing superblocks and filesystem accounting information: done
This filesystem will be automatically checked every 34 mounts or
180 days, whichever comes first. Use tune2fs -c or -i to override.
p500:~#
JFS
p500:~# mkfs.jfs -q /dev/hde1
mkfs.jfs version 1.1.8, 03-May-2005
\
Format completed successfully.
390708801 kilobytes total disk space.
0.03user 1.01system 0:02.62elapsed 40%CPU (0avgtext+0avgdata 0maxresident)k
0inputs+0outputs (0major+224minor)pagefaults 0swaps
p500:~#
REISERFS V3
p500:~# mkreiserfs -q /dev/hde1
mkreiserfs 3.6.19 (2003 www.namesys.com)
A pair of credits:
Continuing core development of ReiserFS is mostly paid for by Hans Reiser from
money made selling licenses in addition to the GPL to companies who don't want
it known that they use ReiserFS as a foundation for their proprietary product.
And my lawyer asked 'People pay you money for this?'. Yup. Life is good. If you
buy ReiserFS, you can focus on your value add rather than reinventing an entire
FS.
Chris Mason wrote the journaling code for V3, which was enormously more useful
to users than just waiting until we could create a wandering log filesystem as
Hans would have unwisely done without him.
Jeff Mahoney optimized the bitmap scanning code for V3, and performed the big
endian cleanups.
p500:~#
Both extended filesystem revisions take a backseat to their
counterparts.
ReiserFS takes a VERY long time to mount the filesystem. I included
this test because I found it actually takes minutes to hours
mounting a ReiserFS filesystem on a large RAID volume.
People always complain about how hard drive manufacturers equate
1000 kilobytes as a megabyte, well the filesystem is also part of
the problem!
Benchmark Set 2 of 4
In the first test, ReiserFSv3 continues to lead the pack, with
ReiserFSv4 and JFS not far behind.
ReiserFSv4 is now the slowest filesystem to search for files,
previously, it had been XFS.
XFS is no longer the slowest filesystem for removing many files.
However, EXT2 and EXT3 still win by far.
Similar to the first test, EXT2 and EXT3 lag behind the other
journaling filesystems.
Contrary to the first set of benchmarks I ran, it appears XFS has
slightly improved, ReiserFSv4 is now the slowest with ReiserFSv3
behind it. Also in the previous test, EXT3 had suffered a huge
performance hit in this area, it is now comparable to EXT2.
It appears ReiserFS v3 and v4 have some serious issues deleting
large numbers of directories.
In the first benchmark test, EXT2 won the test, now XFS is the new
leader.
This benchmark represents how fast the tar ball can be read from
each file system. Surprisingly, XFS now exceeds EXT3.
ReiserFSv3 won the last benchmarking round; however, EXT2 and EXT3
now dominate this test.
The best journaling file system here used to be ReiserFSv3;
however, JFS now wins the benchmark.
ReiserFSv3 used to be the winner, it is now ousted by EXT2 and
EXT3.
The biggest difference here is most of the filesystems have evened
out compared to the first benchmarking test.
This test has remained relatively the same.
Once again, mostly the same; however, it is important to note that
the performance of EXT2 and EXT3 are much closer this time.
EXT2 and EXT3 take the biggest hit up to about 4096 bytes which is
surprising.
EXT2 and EXT3 now outperform ReiserFSv3. In most of these
benchmarks thus far, ReiserFSv4 is the slowest; however, here we
see that V4 is about 12 seconds faster than V3.
JFS continues to lead this test with EXT2 and EXT3 not far
behind.
The following represents the combined test times.
Benchmark Set 3 of 4
The following is the CPU utilization for this test.
The following is the CPU utilization for this test.
The following is the CPU utilization for this test.
The following is the CPU utilization for this test.
The following is the CPU utilization for this test.
The following is the CPU utilization for this test.
The following is the CPU utilization for this test.
The following is the CPU utilization for this test.
The following is the CPU utilization for this test.
The following is the CPU utilization for this test.
The following is the CPU utilization for this test.
The following is the CPU utilization for this test.
The following is the CPU utilization for this test.
The following is the CPU utilization for this test.
The following is the CPU utilization for this test.
The following is the CPU utilization for this test.
The following is the CPU utilization for this test.
Here is a line chart of representing all of the test times.
Benchmark Set 4 of 4
Here is a composite of the total test time for all tests.
File Benchmark II Data
Seconds Elapsed
Test
Task
EXT2
EXT3
JFS
REISERv3
REISERv4
XFS
001
Touch 10,000 Files
48.25
48.25
34.59
33.59
34.08
37.47
002
Find 10,000 Files
0.03
0.03
0.03
0.03
0.07
0.04
003
Remove 10,000 Files
0.16
0.16
1.64
1.84
2.98
2.51
004
Make 10,000 Directories
49.76
49.87
34.32
33.74
34.68
37.17
005
Find 10,000 Directories
0.65
0.65
0.63
1.07
1.46
0.72
006
Remove 10,000 Directories
1.66
1.67
3.58
43.48
119.42
5.39
007
Copy Tarball from Other to Current Disk
5.17
5.15
5.74
5.12
7.34
4.26
008
Copy Tarball from Current to Other Disk
6.96
7.00
6.97
6.89
8.21
6.69
009
UnTAR Kernel 2.6.14.4 Tarball
14.92
15.19
27.64
26.92
21.45
40.81
010
TAR Kernel 2.6.14.4 Source Tree
14.05
14.08
13.05
33.49
25.82
36.19
011
Remove Kernel 2.6.14.4 Source Tree
2.47
2.64
6.17
5.65
10.15
9.10
012
Copy 2.6.14.4 Tarball 10 Times
39.48
38.29
39.13
45.15
62.16
46.34
013
Create a 1GB File
15.02
15.02
15.12
15.96
25.40
15.87
014
Copy a 1GB File
36.87
36.51
38.54
47.60
50.63
41.25
015
Split 10M File into 1000 Byte Pieces
57.26
57.77
2.99
4.35
2.95
4.87
016
Split 10M File into 1024 Byte Pieces
28.73
28.97
2.24
4.04
2.61
4.01
017
Split 10M File into 2048 Byte Pieces
7.02
6.98
1.39
2.26
1.55
1.95
018
Split 10M File into 4096 Byte Pieces
1.85
1.83
0.67
1.05
0.99
0.98
019
Split 10M File into 8192 Byte Pieces
0.58
0.58
0.36
0.56
0.62
0.57
020
Copy 2.6.14.4 Kernel Source Tree
10.02
10.06
35.76
31.64
20.17
43.42
021
CAT 1GB File to /dev/null
18.90
18.59
18.00
37.33
21.37
18.70
CPU Utilization
Test
Task
EXT2
EXT3
JFS
REISERv3
REISERv4
XFS
001
Touch 10,000 Files
99.00
99.00
99.00
99.00
99.33
99.00
002
Find 10,000 Files
94.00
93.00
94.00
95.00
97.00
95.66
003
Remove 10,000 Files
98.00
98.66
73.66
99.00
99.00
91.66
004
Make 10,000 Directories
98.00
97.33
99.00
99.00
99.66
99.00
005
Find 10,000 Directories
99.00
99.00
99.00
99.00
99.00
99.00
006
Remove 10,000 Directories
99.00
99.00
88.66
99.00
99.00
97.00
007
Copy Tarball from Other to Current Disk
74.66
74.66
76.00
74.66
61.33
92.33
008
Copy Tarball from Current to Other Disk
60.00
59.33
59.33
62.00
86.00
62.66
009
UnTAR Kernel 2.6.14.4 Tarball
42.33
41.33
27.33
53.00
80.00
26.00
010
TAR Kernel 2.6.14.4 Source Tree
44.00
43.66
51.33
26.66
48.66
21.00
011
Remove Kernel 2.6.14.4 Source Tree
39.66
36.66
33.00
89.33
88.33
63.66
012
Copy 2.6.14.4 Tarball 10 Times
79.33
80.66
93.33
74.33
73.00
90.33
013
Create a 1GB File
56.00
55.66
67.33
57.00
50.00
64.33
014
Copy a 1GB File
42.00
42.00
47.00
37.33
52.00
49.33
015
Split 10M File into 1000 Byte Pieces
99.00
99.00
64.33
96.33
98.00
86.33
016
Split 10M File into 1024 Byte Pieces
99.00
99.00
77.33
97.66
99.00
97.00
017
Split 10M File into 2048 Byte Pieces
99.00
99.00
64.00
96.66
99.00
97.33
018
Split 10M File into 4096 Byte Pieces
99.00
99.00
69.33
99.00
99.00
97.33
019
Split 10M File into 8192 Byte Pieces
99.00
99.00
87.00
89.66
99.00
97.66
020
Copy 2.6.14.4 Kernel Source Tree
65.33
65.00
21.33
41.33
70.33
25.33
021
CAT 1GB File to /dev/null
26.33
27.00
27.33
36.66
46.33
30.00
File Benchmark I Data
Conclusion
With the second round of filesystem benchmarks, I hope everyone
is now satisfied with the benchmarks using the 2.6 kernel. What I
gleam from these benchmarks is both EXT2 and EXT3 are now roughly
the same speeds in the majority of the tests. It also appears the
XFS has improved in the majority of the tests. ReiserFSv3 has
slowed in many of the tests with ReiserFSv4 being the slowest in
most of the tests. It is important to note that JFS has improved in
some of the tests. Personally, I still choose XFS for filesystem
performance and scalability.
This article describes a Linux module that replicates its input
on all of its outputs, a so called "fanout" or "one to many"
multiplexer.
Purpose: The purpose of fanout is to give Linux a simple
broadcast IPC.
Our own purpose for writing the module was to distribute log
messages to one or more processes that want to be notified when an
event occurs. We use /dev/fanout, a web server, and XMLHttpRequest
on a web client to build an alarm system with multiple web
interfaces running simultaneously. One nice feature of our alarm
system is that the web interfaces don't use polling but still
update automatically when a new alarm system message arrives.
Common Approaches to Broadcast: The two most common
broadcast mechanisms in Linux are signals and UDP packets. You can
broadcast a signal to a group of related processes using the kill
command with a PID of zero. This works well if all of the processes
are related and if the program knows what action is required on
your signal.
Signals will not work for our application since there is no way
to directly route a signal from a web server to a web client, and
because web servers do not know that we want to redraw certain web
screens on a particular signal.
We can also broadcast events using UDP or TCP. We've built event
servers which accept TCP connections and broadcast event
information down each accepted connection. We use XMLHttpRequest to
request a PHP page that opens the TCP connection and waits for the
event. While this approach works well, it requires yet another
process and has the slight extra burden of an additional TCP
connection for each web client.
A Better Broadcast Approach: A better approach would be
to have something like a FIFO, but instead of having all of the
listeners compete for the single copy of the input message, have
all of the listeners get their own copy. Consider the following
bash dialog:
The message appears only once, since only one instance of the
cat command is given the fifo output. Now let's consider the same
experiment using fanout:
cat /dev/fanout &
cat /dev/fanout &
cat /dev/fanout &
echo "Hello World" > /dev/fanout
Hello World
Hello World
Hello World
The message now appears once for each of the three listening cat
commands. We use bash commands just to illustrate what fanout does.
Its real power lies in letting many different programs get
identical copies of a data stream.
Which fails: send or receive? No matter how hard we try
to avoid it, one day we'll find a reading process that can not keep
up with the writing process. Allocating more memory postpones the
problem but does not eliminate it. When this problem occurs we have
two choices: apply back pressure to the writer causing the writer
to block, or let the readers miss some output.
The problem with blocking the writing process is that you may
affect other parts of the system. Our original purpose was to build
an alarm system and we chose to route all event notifications
through syslogd. Since we have /dev/fanout as a target in the
syslog.conf file, blocking the writer would block syslogd and
defeat the whole purpose of our alarm system.
The author of fanout very deliberately chose to cause the reader
to fail when it can not keep up. Data is stored in a circular
buffer and if a reader can not keep up with the writer, it will
eventually ask for data that is no longer in the circular buffer.
The fanout device returns an EPIPE error to the reader when this
happens. In our application for /dev/fanout we are happy to protect
syslogd at the expense of the web clients when we are forced to
choose one over the other.
The source code to the fanout module is available as a
compressed tarball fanout.tgz,
or you can pick up the individual files, fanout.c and Makefile.
Build the module with the following commands:
cd /usr/src/linux
tar -xzf fanout.tgz
cd fanout
make
When you install the module you can set the size of the circular
buffer and can set the verbosity of the printk messages. The
default buffer size is 16k and the default debug level is 2. A
debug level of 3 traces all calls in the module and a debug level
of 0 suppresses all printk messages. Here is an example that
overwrites the default values for buffer size and debug level:
insmod ./fanout.ko buf_sz=8192 debuglvl=3
Fanout uses a kernel assigned major number so you need to look
at /proc/devices to see what was assigned. The following lines
create all ten of the possible instances of a fanout device.
MAJOR=`grep fanout /proc/devices | awk '{print $1}'`
mknod /dev/fanout c $MAJOR 0
mknod /dev/fanout1 c $MAJOR 1
mknod /dev/fanout2 c $MAJOR 2
mknod /dev/fanout3 c $MAJOR 3
mknod /dev/fanout4 c $MAJOR 4
mknod /dev/fanout5 c $MAJOR 5
mknod /dev/fanout6 c $MAJOR 6
mknod /dev/fanout7 c $MAJOR 7
mknod /dev/fanout8 c $MAJOR 8
mknod /dev/fanout9 c $MAJOR 9
If all has gone well, the "Hello World" example given above
should now work for you.
How /dev/fanout Works
This section is a high level design review of the fanout module.
We explain the design and architecture, and relate specific lines
of code in the module to the overall design.
The key to understanding how fanout works is to know how a
little about how read() works. If you were to open a disk file and
make five read() calls with each call reading a thousand bytes, you
would expect the next read to give you the data starting with byte
5000. Internally, the operating system keeps a counter, called
f_pos, that remembers where you are in the file. Once
you've read the first 5000 bytes, you don't normally want to read
them again, and since you aren't likely to ask for them again,
fanout can forget them. The mechanism used to remember only the
most recent data is a circular queue.
The fanout device uses the count variable to keep track
of how many bytes have been written so far. At quiescence, the
readers have all read count bytes (count and
f_pos are equal), and the readers are now asking for data
starting at *offset (which also equals count).
When a writer adds data to the queue, the count
variable is incremented by the amount added. Each of the readers
must now wake and read the bytes between *offset and
count. After adding data to the queue, a writer wakes any
sleeping readers with the call to wake_up_interruptible()
in fanout_write().
Buffer overflow: One of the fundamental decisions to make
in a design is what to do when a reader can not keep pace with the
writers. In many designs you would apply flow control to the
writers to slow them down to keep pace with the slowest reader. The
fanout device, however, returns an error to the slow reader.
Specifically, the reader gets an EPIPE error when it requests data
that is no longer in the circular buffer (i.e. *offset <
count - buf_sz, where buf_sz is the number of bytes
in the circular buffer).
A reader does not immediately get an EPIPE after opening a
fanout device that's been operating for awhile because in the file
open routine, fanout_open(), we explicitly force the
reader to be caught up with the writers. The line of code that does
this is:
filp->f_pos = fodp->count;
Code notes: It is said that programmers can read code and
know what it does, but they can not read a variable and know what
it means. So instead of reviewing the code, we are going to
review the variables.
The fanout module supports up to NUM_FO_DEVS instances
of a fanout device. NUM_FO_DEVS is currently set to ten.
Each instance of a fanout device is described by the following data
structure:
struct fo {
char *buf; /* points to circular buffer */
int indx; /* where to put next char recv'd */
loff_t count; /* number chars received */
wait_queue_head_t waitq; /* readers wait on this queue */
struct semaphore wlock; /* write lock to keep buf/indx sane */
};
Let's look at each of these variables in turn:
buf: The buf variable points to the start of the
buf_sz number of bytes allocated for the circular queue.
The memory is not allocated until the first open() on the device,
and the memory is allocated using kmalloc(). Allocated memory is
not freed until the module is unloaded.
indx: This variable gives the location of where to place
the next byte in the circular queue. It is updated by
fanout_write() as bytes are added to the queue. When indx gets to
buf_sz, it wraps back to zero.
count: This variable is the total number of bytes written
to the device. It is updated only by fanout_write() and a reader
has data to read when count is not equal to *offset.
waitq: When a reader has no new data to read it blocks
until new data is available. Specifically, the reading process
sleeps in a call to wait_event_interruptible(). The
writer's call to wake_up_interruptible() causes the
readers to wake and continue execution with the lines of code
immediately after the wait_event_interruptible().
wlock: While writers are writing to the circular queue,
there is a short time during which the count and indx variables are
not yet consistent with the data in the queue. During this window
of inconsistency another writer might run and inadvertently corrupt
the queue. The wlock mutex prevents this by locking out
other writers while one writer is updating the queue.
One final note on the code is the use of the
*private_data in the file structure. Fanout uses this
variable to store a pointer to the struct fo appropriate
to that file. The FanOut Device Pointer (fodp) is usually retrieved
at the start of a routine with a line of code like this:
Known bugs: While there may be several implementation
bugs, the one possible design bug is that fanout assumes that the
file offset counter never wraps. This should probably be fixed.
Security: In our use of /dev/fanout we let a web server
read directly from it so that web clients can be updated when an
event occurs. Giving the web server direct access to a device file
is considered a security risk. You generally don't want your web
server to follow symbolic links and you don't want the file system
with the web server root directory to allow device nodes in it.
(The file system should be mounted with the nodev option.)
The fear is that if an attacker breaks Perl, PHP, or some other
component of the web server, the attacker might be able be able to
create /dev/hda1, /dev/mem, or some other critical device.
We will be using /dev/fanout in an appliance where, after boot,
we can at least drop the system capability CAP_MKNOD when we drop
the other system capabilities.
Obsolete already? It is widely anticipated that one of
the next releases of the 2.6 kernel will include two new system
calls, tee() and splice(). These calls will probably make obsolete
the approach used to build fanout, and might make /dev/fanout
entirely obsolete. This might be a good thing since, from a
security point of view, it might be better to create a one-to-many
multiplexer as a variant of a FIFO that can be attached to a nodev
mounted file system. More information on tee() and splice() is
available in an article at the Linux Weekly News (http://lwn.net/). The article number is
118750 and you can get to it directly here.
Bob is an electronics hobbyist and Linux programmer. He
is one of the authors of "Linux Appliance Design" to be
published by No Starch Press.
An introduction intended for people with no prior device driver
knowledge
This article is intended for those newbie Linux users who wish
to use their Linux-box for some real work. I will
also share some interesting experiments that I did with my AMD
machine.
INIT
Learning new stuff is fun, but can be a bit frustrating. So, you
want to write a device driver. The name itself is high-tech! You
have some skills in the C programming language and want to explore the
same. Also, you've written a few normal programs to run as processes
in user space, and now you want to enter kernel space - where the
real action takes place. Why Linux device drivers? The answer
is,
For fun
For profit (Linux is HOT right now, especially embedded
Linux)
Because you can! The source is with you.
Although it is possible to learn device driver coding by
reading some books and PDFs written by the masters, this is a
complicated and time-consuming approach. We will take the quick and
easy approach, which is:
Find some pre-written, working code
Understand how this code works
Modify it to suit our needs
Let's make an easy start with some fundamentals.
Stepper motor basics
Stepper motors are special direct-current (DC) motors, typically used in
applications like camera zoom drive and film feed, fax machines, printers,
copying machines, paper feeders/sorters, disk drives and robotics.
A DC stepper motor translates current pulses into motor rotation. A
typical unipolar (single voltage) motor contains four winding coils.
Applying voltage to these coils forces the motor to advance one step. In
normal operation, two winding coils are activated at the same time, causing
the motor to move one step clockwise. If the sequence is applied in
reverse order, the motor will run counterclockwise. The speed of rotation
is controlled by the frequency of the pulses.
A typical full step rotation is 1.8 degrees, or 200 steps per rotation
(360 degrees). By changing the time delay between successive steps, the
speed of the motor can be regulated, and by counting the number of steps,
the rotation angle can be controlled.
Bit Pattern for Full Step Mode
Green
Blue
Orange
Red
Hex Output Value
Step 0
1
0
1
0
A
Step 1
1
0
0
1
9
Step 2
0
1
0
1
5
Step 3
0
1
1
0
6
Hardware ideas
The circuit diagram for the drive is shown below.
The circuit consists of four TIP122 power transistors (T1, T2, T3 and T4),
220Ω resistors (R1, R2, R3 and R4), 3.3KΩ resistors
(R5, R6, R7 and R8), 1N4148 freewheeling diodes (D1, D2, D3 and D4), and
one LM7407 buffer chip (IC1). The 7407 buffer used here is a hex-type
open-collector high-voltage buffer. The 3.3KΩ resistors
are the pull-up resistors for the open-collector buffer. The input for this buffer
comes from the parallel port. The output of the buffer is of higher
current capacity than the parallel port output, which is necessary for
triggering the transistor; it also isolates the circuit from the PC
parallel port and hence provides extra protection against potentially
dangerous feedback voltages that may occur if the circuit fails. The diode
connected across the supply and the collector is used as a freewheeling
diode and also to protect the transistor from the back EMF of the motor
inductance. The motor used in my experiments (and documented here) was an
STM 901 from Srijan
Control Drives.
During normal operation, the output pattern from the PC drives
the buffer, and corresponding transistors are switched on. This
leads to the conduction of current through those coils of the
stepper motor which are connected to the energized transistor.
This makes the motor move forward one step. The next pulse will
trigger a new combination of transistors, and hence a new set of
coils, leading to the motor moving another step. The scheme of
excitation that we have used here has already been shown above.
How do we interface the hardware with the Linux-box?
You can use either the parallel port or the serial port for this
purpose. We will be using parallel port as a digital interface
between PC and the hardware (stepper motor drive). The parallel port
can be considered as a register, and the I/O operations can be done
simply by writing bit patterns (numbers like 0xA, 10, '1010', etc.)
to this register. The base address of parallel port is 0x378. The PC
parallel port is a 25 pin D-shaped female connector in the back of
the computer. It is normally used for connecting computer to
printer, but many other types of hardware for that port are
available.
The original IBM PC's Parallel Printer Port had a total of 12
digital outputs and 5 digital inputs accessed via 3 consecutive
8-bit ports in the processor's I/O space.
8 output pins accessed via the DATA Port
5 input pins (one inverted) accessed via the STATUS Port
4 output pins (three inverted) accessed via the CONTROL
Port
The remaining 8 pins are grounded
To read a byte (8 bits) coming into a port, call inb
(port); to output a byte, call outb (value,
port) (please note the order of the parameters). The data outputs
are provided by an 74LS374 totem-pole TTL integrated circuit, which can
source (+) 2.6 mA and sink (-) 24 mA. The best option for preventing
damage to the port is to use optocouplers; by doing so, the port is
completely electrically isolated from external hardware devices.
What is a module?
Modules are pieces of code that can be loaded into and unloaded from a
running kernel upon demand. They extend the functionality of the kernel
without the need to reboot the system. Device drivers are a class of
modules which allows the kernel to control hardware connected to the system.
In this article, I have written a simple device driver to control a stepper
motor drive; now it is time to log on to your console and start coding your
very first module.
Let's have an unusual start! You have written so many "Hello,
World" programs. So this time something different - "No gates, No
windows, it's open". You will get these words printed on your
console when you insert your first module.
/*mymodule.c - The simplest kernel module.*/
#include <linux/module.h> /* Needed by all modules */
#include <linux/kernel.h> /* Needed for KERN_ALERT */
int init_module(void)
{
printk("<1>No gates, No windows, it's open\n");
return 0;/* A non-0 return means init_module failed; module can't be loaded.*/
}
void cleanup_module(void)
{
printk("Goodbye\n");
}
The "start" function in a kernel module is init_module () which
is called when the module is insmoded into the kernel, and the
"end" (cleanup) function cleanup_module() is called just before it
is rmmoded.
Compiling kernel modules
Kernel modules need to be compiled with certain GCC options to
make them work. In addition, they also need to be compiled with certain
symbols defined. This is because kernel header files need to behave
differently, depending on whether we're compiling a kernel module or
executable.
-C: A kernel module is not an independent executable, but an
object file which will be linked into the kernel during runtime
using insmod.
-O2: The kernel makes extensive use of inline functions, so
modules must be compiled with the optimization flag turned on.
Without optimization, some of the assembler macro calls will fail. This
will cause loading the module to fail, since insmod won't find those
functions in the kernel.
-D_KERNEL_: Defining this symbol tells the header files that
the code will be run in kernel mode, not as a user process.
You can learn more about make utility by reading "man make".
Anatomy of device drivers
There is a lot of documentation on the Web, including PDFs and ebooks,
on device drivers; also, you can download some useful guides from The Linux
Documentation Project website. For the time being, just read these
points carefully; later, you can move on to some detailed references.
A device driver has two sides. One side talks to the rest of
the kernel and to the hardware, and the other side talks to the
user.
To talk to the kernel, the driver registers with subsystems to
respond to events. Such an event might be the opening of a file,
writing some useful data, the plugging in of a pen-drive (USB
device), etc.
Since Linux is a type of UNIX, and in UNIX everything is a file, users
talk with device drivers through device files, which are like a digital
representation of a hardware device.
A stepper is a character device, and thus the user talks to it
through a character device file. The other common type of device file is
block. We will only discuss character device files in this
article.
The user controls the stepper motor through the /dev/stepper
device file
When the user opens /dev/stepper, the kernel calls stepper's
open routine
When the user closes /dev/stepper, the kernel calls stepper's
release routine
When the user reads or writes from or to /dev/stepper - I think
you got the idea...
Now let's examine our code.
#define MODULE
#include <linux/module.h>
#include <asm/uaccess.h>
#include <sys/io.h>
#include <linux/fs.h>
#define LPT_BASE 0x378
#define DEVICE_NAME "stepper"
static int Major,i,j,k;
static int Device_Open = 0;
//static int pattern[2][8][8] = {
// {{0xA,0x9,0x5,0x6},{0xA,0x8,0x9,0x1,0x5,0x4,0x6,0x2}},
// {{0x6,0x5,0x9,0xA},{0x2,0x6,0x4,0x5,0x1,0x9,0x8,0xA}}
//};
static int pattern[2][8][8] = {
{{0xA,0x9,0x5,0x6,0xA,0x9,0x5,0x6},{0xA,0x8,0x9,0x1,0x5,0x4,0x6,0x2}},
{{0x6,0x5,0x9,0xA,0x6,0x5,0x9,0xA},{0x2,0x6,0x4,0x5,0x1,0x9,0x8,0xA}}
};
int step()
{
if(k<8) {
// if(pattern[i][j][k]==0) {
// k=0;
// printk("%d\n",pattern[i][j][k]);
// k++;
// }
// else {
printk("%d\n",pattern[i][j][k]);
k++;
// }
}
else {
k=0;
printk("%d\n",pattern[i][j][k]); /*#####*/
k++; /*#####*/
}
return 0;
}
static int stepper_open(struct inode *inode,struct file *filp)
{
static int counter = 0;
if(Device_Open) return -EBUSY;
printk("Opening in WR mode...\n");
Device_Open++;
MOD_INC_USE_COUNT;
return 0;
}
static int stepper_release(struct inode *inode,struct file *filp)
{
printk("Clossing...\n");
Device_Open --;
MOD_DEC_USE_COUNT;
return 0;
}
static int stepper_write(struct file *file, const char *buffer, size_t len,
loff_t *offset)
{
char *data;
char cmd;
get_user(data,buffer);
switch (cmd=data) {
case 'H':
printk("Reffer README file\n");
break;
case 'h':
printk("Half-Step mode initialized\n");
j=0;
break;
case 'f':
printk("Full-Step mode initialized\n");
j=1;
break;
case 'F':
i=0;
step();
break;
case 'R':
i=1;
step();
break;
// default:
// printk("Give 'H' for Help\n");
// break;
}
return 1;
}
static struct file_operations fops={
open:stepper_open,
write:stepper_write,
release:stepper_release,
};
int init_module(void)
{
Major = register_chrdev(0, DEVICE_NAME, &fops);
if (Major < 0) {
printk("<1>Registering the character device failed with %d
\n",Major);
return Major;
}
printk("<1>Registered, got Major no= %d\n",Major);
return 0;
}
void cleanup_module(void)
{
printk("<1>Unregistered\n");
unregister_chrdev(Major,DEVICE_NAME);
}
The init_module() function is called on the driver's
initialization
The cleanup_module () function is called when the driver is
removed from the system
The init function will register hooks that will get the
driver's code called when the appropriate event happens
There are various hooks that can be registered: file
operations, PCI operations, USB operations, network operations.
Ours is a file operation.
The driver registers a character device tied to a given major
number and a user can create access points corresponding to this
major number.The following command will do it for you:
mknod /dev/stepper c 254 0
How stuff works
A user space program can write commands to the device file to
rotate the stepper motor through a desired angle at desired speed.
The speed of rotation depends upon the delay given in the user
program.
The built in commands for controlling the stepper motor is given
below.
H ----------- Help
h ----------- Half-step mode
f ----------- Full-step mode
F ----------- Rotate one step clockwise
R ----------- Rotate one step anti-clockwise
File operations
The driver makes use of the following device file
operations:
open for allocating resources
release for releasing resources
write the required pattern to the parallel port.
there is no reading in our program, but if you want, you
can read the current pattern at the parallel port.
If you write 'F' once to "/dev/stepper", the motor will rotate
through its minimum step-angle. If you keep on writing 'F' to
"/dev/stepper", it will rotate continuously. The "write" system
call will do this for you.
Also, if you are familiar with shell scripting, you can do the same by
writing a simple shell script. Now you can start talking to the device
/dev/stepper. It will be really interesting if you talk in Linux's language
- I mean a shell script. Just use
simple echo commands as given below:
echo H > /dev/stepper
Do you think that Morpheus is talking to you? Your kernel is replying to
your commands. How's that! Now, you too can feel like you are The One.
Conclusion
I hope I have given you some basics of device driver coding and perhaps
a "small step toward Robotics". Here is a detailed schematic of a
stepper-controlled robotic
arm; feel free to try
it out. One can connect three stepper motors simultaneously to the PC
parallel port and can achieve step-wise mobility; this allows anyone to
start thinking of complex innovative mobility with multi-threaded
programming in Linux. You can also add C functions to our module to enhance
its functionality... the possibilities are endless!
I am a Linux enthusiast living in India. I enjoy the freedom and power that
Linux offers. I must thank my mentor Mr. Pramode C. E. for introducing me to
the wonderful world of Linux.
I completed my B-Tech in Electrical and Electronics Engineering from Govt.
Engineering College, Thrissur (Kerala, India) (2001 - 2005). Presently I am
working in inDSP Audio Technologies Pvt. Ltd, Trivandrum, India as an
Embedded Systems Engineer.
I spend my free time reading books on Linux and exploring the same. My
other areas of interest include device drivers, embedded
systems, robotics and process control.
Part computer programmer, part cartoonist, part Mars Bar. At night, he runs
around in a pair of colorful tights fighting criminals. During the day... well,
he just runs around. He eats when he's hungry and sleeps when he's sleepy.
I didn't get the launderette in on time last month, so
last month's
is available.
Over the past few months there have been quite a few recurring topics.
Two of them have been
the law
and
Web 2.0
(Also, in the latter thread, I mention some XSLT for photo annotations.
Here's
an example
of that)
Fwd: Xteddy. :)
Mon, 28 Nov 2005
From Stefan Gustavson
[Thomas]
I am liking this.
Thanks for the XTeddy fan mail. It's always nice
to hear from people who like him. I don't get more
than a few messages per year about him these days,
but it's nice to see that he's still out there.
The real life XTeddy is a present from my wife,
she got it for me as a stress relief in 1994
when I was a PhD student, and I must say it
still works. He still sits on my desk, or
rather on a shelf just above my desk, in clear
view and ready to comfort me when things get
rough. (Although his mere presence actually
seems to stop things from getting too rough.)
Like most teddy bears, he has a real life name,
and it happen to be "Lufs", which is a cutesy
Swedish bear name whose point gets more or less lost
in translation, but I'll try anyway:
The name "Lufs" means nothing in particular, but the
kind of slow trotting and wobbling walk that real live
bears tend to do when they are not in any hurry is
referred to as "lufsa" (a verb) in Swedish, and when
we were kids, both my wife and I had read a story
by the Swedish author G=F6sta Knutsson about a little
bear cub named "Nalle Lufs", ("Nalle" is an old Swedish
word for "bear", often used as a synonym for "teddy bear".)
I can't remember whether it was me of my wife who
named him. It kind of grew on him more than being
a planned naming. I'm not even sure if we were
consciously aware of that childhood story at the
time, but we both recalled reading it when we saw
it a few years ago.
The XTeddy program was my first and so far only attempt
at writing a native program for X Windows. It makes very
simple use of the Shape extension and a pixmap background,
and the original version was about one page of code.
It has since been extended with better image loading
functions, but the basic window functionality is still
just a shaped window with a background pixmap, and a
simple, low level mouse event handler to move it around.
It was also a counterstatement to "xeyes", the only
other shaped window program that was around in 1994.
I thought it was a bad and ugly demo for a good extension.
Xeyes is kind of cute the first time you try it, but
it is kind of intrusive (someone or something is watching
your every move with the mouse) and therefore has very
little staying power with most users.
XTeddy is rather the opposite to xeyes: Nonintrusive,
motionless unless you pick him up, doesn't really care
what you are doing and watches you, not your work or
lack thereof, in patient silence. He's basically useless,
but cute, and always available.
That was probably more background information than
you ever wanted, but you did ask for it.
[Thomas]
xteddy has been personified into a bot that gives people hugs.
He's very good at that. Good thinking!
Microsoft and open standards
Tue, 06 Dec 2005
From Jimmy O'Regan
"Microsoft has stated on numerous occasions that they believe in and
support open standards. But from my experience, they do this not by
joining existing open standards efforts, but instead by creating
entirely new, parallel (and arguably redundant) "open standards" efforts
around their own technologies."
Up to you whether I'm late, on time, or early for your personal favorite.
[Ben]
I've been running behind on everything - Ulysses is in the final stages
of the repairs, and we're spending all our time sanding, grinding, and
painting (and learning a hell of a lot, particularly about that last;
there's a whole body of science behind it, particularly when you ask as
much of it as we do.) Anyway - happy holidays to everyone, whichever
version you celebrate; may your upcoming year be filled with love, joy,
and happiness!
[Jimmy]
And may you have fewer hurricanes!
And my apologies to Jimmy for the #tag-chat teddybear being asleep on the job.
Apparently he knows how to serve up the brews right proper, but only serves
them correctly on one network. D'oh!
Actually I sit corrected; poor little plushybrains watched his pearl roll
under the couch. I had to unload and restart his script, and then it worked
fine in both places.
[Jimmy]
[18:55] <jimregan> Um... Happy cheesy /topic messages to you all too
[Jimmy] For the record:
* Topic is 'The Answer Gang, happy linuxgazette.net to all penguins
everywhere | +cgianakop> I just wanted to stop in for a few and wish the
gang merry christmas | merry solstice, happy hanukah, and a cheerful xmas
too | xteddy serves eggnog and fine brews | happy gnu year'
[Sluggo]
If I threw xteddy out the window, would I incur the Wrath of Thomas?
Would my Linux questions go unanswered forevermore?
[Jimmy]
Hmm. Wasn't that the little known Egyptian Plague 6.5? Boils in the shape of Xteddy?
is this the verb for "give me" ? I could add it.
[Jimmy]
No, well, kind of... In a bar, you'd say 'proszę <whatever>'. It's
probably better for xteddy to not understand Polish, because of the
amount of grammar you need to know just to ask for something
Well, maybe not. A sample session'd look like this:
<jimregan> xteddy: prosze wodke (vodka please)
<xteddy> jimregan: masz wodke (your vodka)
<xteddy> jimregan: wodki nie ma (out of vodka)
<jimregan> xteddy: prosze piwo (beer please)
<xteddy> jimregan: masz piwo (your beer)
<xteddy> jimregan: piwa nie ma (out of beer)
[Ben]
It means "I would like", if I understand it correctly; not too far off a
similar Russian word, although the usage is somewhat different.
[Jimmy]
Kinda... it means "I request". It's the perfective version
[Jimmy] For those who are not familiar with perfective verbs:
Wikipedia
(as ever) has a good article.
There's precedent. He already does hug in a few foreign languages for
some specific people. As I continue to merge his code bits he'll be a
multilingual teddybear.
Or you could use tule/tuli (1st/3rd person of 'cuddle')
[Jimmy]
[19:03] <jimregan> Hmm. Xteddy nie mowi po polsku
[19:03] * xteddy bounces
he saw his proper name... the trigger.pl script wasn't busted, making the
bear look hard of hearing rather than simply not there.
[Jimmy]
I thought it was something like that
[Jimmy]
[19:03] <jimregan> xteddy: czy mowisz po polsku?
[19:03] <xteddy> :)
What's this mean?
[Jimmy]
"Do you speak Polish?"
[Jimmy]
And there I was thinking xteddy was trying to tell me something
Like what, have a guiness instead ?
[Jimmy]
Nah, like "I think you've had enough, and I think you should give me
your keys. No, I don't care that they're house keys -- you're in no fit
state to operate any form of door".
Anyways, feature request to have the recognized goodies work without "gimme"
is already in the works... I wanted to merge the old features first, but the
gimme was too attractive an idea.
Entirely aside of teddybears, it's a nice warm feeling to see progress,
so I think it was worth it. For giggles, people can try a few types of
snacks, drinks, and baked goods.
Chris G. came in while I was still coding up some of this stuff, and
followed me into #fvwm to see him in a little more action (the regulars
there are pretty found of our bear). He was delighted.
Which is a damn shame, because I've almost got him handling guiness with
proper style too.
[Jimmy]
<jimregan>
I'm off to enjoy nog and partying now...
[Jimmy]
Well... Wesołych Świąt, Maligayang Pasko, Nollaig Shona Daoibh, or just plain Merry Christmas.
sudden burst of on-topic: something's eating those characters, and I'm
mildly sure it's not mutt, I know I've see diacriticals and odd chars in
mail from some people now and then. Did anyone among us get that first
couple of words in correct form, and if so, how do you think it did it?
[Ben]
Various 10646 fonts suck in arbitrary ways; you're probably missing the
glyphs for Polish in whatever you're using. All the stuff in Jimmy's
email displayed fine for me in Mutt. Here are my relevant bits:
I used to have to mess about with LANG and LC_ALL and a whole bunch of
goodies to get Mutt to act right...
[Breen]
This may be a project for me in the new year - I'm currently reading
most mail on shell on a FreeBSD box, using mutt displayed on various
terminals on FC3 and Mac OS X. Getting the correct invocations to
make this all work hasn't been near the top of the list, but this
may be the year...
[Ben]
You're in luck: I still have the wrapper script I used to use to launch
Mutt to read my Russian mail, which contains the previous invocations
(commented out) to do various language-related tweaking. I still use it,
since I like saving attachments to /tmp by default and prefer opening
Mutt in "mailbox" view ('-y').
[Ben]
now, using the above font and $LANG
variable for all of X takes care of it just fine. And ':dig' in Vim
produces a very satisfying result.
About the only language that I had
trouble displaying was Georgian - 'gnu-unifont' handled it, but
'gnu-unifont' sucks when you try to display anything with line-drawing
characters (i.e., Midnight Commander). Oh well; 99.9% functionality is
miles better than none.
[Rick]
How... nostalgic. That seems to have been an instance of an actual
confused AOL user, writing manually from AOL, rather than a spam
forgery or malware mail pretending to be from AOL. (All of the
headers verify this, including SPF, which AOL implements properly.)
What's completely unclear from the information given is why
[email protected] is writing, since her headers show only intra-AOL
mail previously.
Dilbert blog: Winning by Knockout
Sun, 25 Dec 2005
From JimRegan
I always consider myself a winner by knockout whenever someone distorts
my point to something ridiculous and then argues against the ridiculous
thing. That seems like an acknowledgement that my real point is unassailable.
Why else would someone need to invent a whole new point to argue against?
===BEGIN
This is to inform you that, base on our end of year promotion of The
Programmer Charity Foundation carried out on the 15th
,December,'05,the above ticket No. fixed to your email ID surfaced in
the third ballot stake.
You have therefore emerged as a recipient of the third award of two
hundred and fifty thousand american dollars in this annual end of year
promotion
I wonder if they pasted the amount out of a 419 email?
The source of fund is majorly from well meaning companies and
humanitarian spirited industries selected from european community.
Be informed that in line with the sponsors' regulation,you are to
contribute a percentage amount( ten percent minimum) to a recognized
non-governmental charity project in your environ,after collection of
your prize
Any charity or a certain one? What does "my environ" mean?
Application and inquiries should be forwarded to Mrs Mabel Konnindam
via ; [email protected].
Paragraph 2 says I've already won, so why do I need to send an
application?
Accept my heart felt congratulations.
Ms Daisey Gregson
PS:Kindly state your Ticket No in your expected application.
The Programmer Charity Foundation,
Schalktorrenstraat 673b,
8921CH,Nijmegen.
Royal Dutch Federation.
===END
I found this from "The Czechs Have a Word For It":
http://www.bohemica.com/?m=catalog&s=258&a=138 having looked up
"Nedovtipa" ("one who finds it difficult to take a hint"), after seeing
a mention in "The Meaning of Tingo" -- well worth a read.
Some great words are:
"neko-neko", Indonesian for "one who has a creative idea that only makes things worse"
"bakkushan", Japanese for "a woman who appears pretty when seen from behind but not from the front"
"scheissenbedauern", German for "the disappointment one feels when something turns out not nearly as bad as one had hoped" (literally "shit regret")
"tsuji-geri", Japanese for "trying out a new sword on a passer-by"
(It also mentions that the Albanians have 27 words for both eyebrows and
moustaches).
[Heather]
[neko-neko] Might be an amusing name for a wiki about dumb things you shouldn't try at
home.
As a multilingual amusement, neko is japanese for kittycat, and many
kittycats have occasioned exactly this kind of brilliant idea.
It turns out [the Alb?nian words] are just adjectives that are added to the words for
moustache and eyebrows, not separate words.
My favourite Polish word is 'kobietka', the diminutive of the word for
woman, that roughly translates as "little girl pretending to be a
woman". We have an equivalent word for men in Hiberno-English: "maneen".
[Ben]
The Russian equivalent for the latter is "muzhichok";
I know there's a Polish equivalent, but I can't find it. The only
diminutive I've heard applied to men is 'dziewcinka', and that means
'little girl'.
[Ben]
oddly enough -
since I would have expected two closely-related Slavic languages to
share a similar concept - I can't think of a parallel to 'kobietka'.
There's "suchka" ("little bitch", a fond diminutive sorta-insult), but
that's not the same thing.
That's 'suczka' in Polish, so no
[Ben]
Yep, I knew that one.
I assume there's something like 'żoneczka' ('little wife')
[Ben]
No, the diminutive for 'wife' doesn't have any extra connotations
besides the obvious ones.
Oh, I was just translating literally -- no extra connotations here.
You just gotta laugh!!
Fri, 25 Nov 2005
From Pete Savage
Hi all,
I'm sorry I just had to post these here, my father-in-law almost paid
for a Navman ICM 550 off of eBay, but being a shrewd man, he did some
feedback chcking and immediately noticed something was wrong. I looked
at these and oh......my sides doth split. I don't know if they have
constructed a mechanism for creating comments from a load of random
words, but the poor translation says it all.
Oh yeah: works for me. (Only tested in Flock, though)
[Thomas]
So much work, for such a large browser.
For those of us that use
Elinks as their browser, then here's something similar, using "Smart
Prefixes". Essentially:
Options Manager -> Protocols -> URI rewriting -> Smart Prefixes
... from there, one can "Add" a new prefix -- I called mine 'lg'. When
that's done, scroll down to it, and "Edit" it, adding the following to
it:
... the "%s" variable above expands to whatever search term was entered
in. Then click on "Save", and voila. Now one can search LG, by either
pressing 'g' or 't', and typing:
lg: my search term
More information can be found on my own Elinks site here:
Mozilla &c. can do the same thing: bookmark the above URL, and add 'lg'
as the keyword. Searching is similar, but without the colon.
[Thomas]
Well, the colon is optional -- the delimiter is either the first space
after the keyword ("prefix" as I would call it), or a colon.
The point of the file I posted is that it adds the search to the little
search bar at the top of Firefox.
[Thomas]
Yeah - it's very cute.
I suppose it's just preference at the end of
it all.
Nah, it's laziness: I can't be arsed remembering the keywords for
different searches
Crap music
Tue, 29 Nov 2005
From roadtripper8 at 43 Things
[Jimmy] This started
here
where the theme music from "The Heights" was mentioned
[Jimmy]
To where you are.
It's like trying to catch a falling star.
*Don't* blame me -- you started it!
That has to be
the crappiest song ever written. And yet we still remember it!
[Jimmy]
No, I can think of worse
"Barney is a dinosaur..."
"I want to be the very best, like noone ever was"
All TV themes. Eerie.
No, wait... Celine Dion's back catalogue!
Funnily enough, I left my MP3 player at home last Friday, and that
song popped into my head for the first time since the show was on.
Your comment... well, it reopened a fresh wound. Damn you!
Make it stop!
I spoke too soon. You have managed to find songs that really are crap.
Hopefully your revenge won't sneak up on me over the next few days.
'Cause I may have to throw myself in front of a truck if Celine Dion
starts playing in my mental jukebox.
[Jimmy]
It's not hard
to find crap music -- just look at the charts. (Quote: "There's more
evil in the charts than an Al Qaeda suggestion box" -- Bill Bailey)
Not quite unrelated: my sister has been a bit upset with me since MTV
played all of Kelly Clarkson's videos and I told her they sounded like
Diet Coke ads. And she had to admit they did. (At least I didn't have
to admit I thought one of them was catchy).
Oh, and as for poor old Celine: I shared a house with one of my
friends for a year in college--without checking his CD collection
first. 9 CDs, all Celine Dion.
Weirdo.
I roomed once
with a Backstreet Boys fanatic. I when I say fanatic, I mean she
actually put up a poster of them...*IN OUR BATHROOM!*
shudders
[Jimmy]
You have bested me
I can normally think of a smart ass comment for every situation,
but... overload!
Consider it payback
I am the one who had the Barney song going through my head for a day!
Japanese help
Fri, 18 Nov 2005
From Pete Savage
Hi all,
A lot of you seem to be well up on foreign languages.
I need to find out how to "write"
"Lisa, I love you." In Japanese.
I think I'm ok with the Lisa part, needs to be written in katakana as
Risa.
Once again Any help greatly appreciated.
[Kat]
Well...Pete, why do you want to write this in Japanese? I can help you
say this in Mandarin, but the Japanese just don't say this. It sounds
horribly stilted and overblown, even though there is a literal
translation. Even the more commonly used declaration sounds well, kinda
dorky.
So with those caveats,
"Lisa, anata aishiteru" is probably as good as it's going to get. (Lisa,
you(familiar) loving) (If you add in the "I" , it sounds like the emphasis
is on I love you, rather than "you are loved by me".)
"Suki da yo" is what a guy tells his girl, but IMHO it has connotations of
"yeah yeah, I'll TELL you I like you because you asked, but it should
be obvious")
[Jay]
Oh, so Japanese guys are just like American guys. Got it.
Thank you for the reply.
It's for my wife for christmas, she is very fond of the Japanese
culture, in particular Manga and Anime. I wanted to write her almost
like a scroll that I could frame for her for christmas
[Rick]
Well, good for you.
I personally had to sit down, a bit over five years ago, and figure out
how to write?"Deirdre, will you marry me" in Esperanto.
[Thomas]
Wow, it took you all this time?
[Rick]
She, in turn, set herself the task of figuring out the equally daunting
challenge of how to say "Yes" in Irish.
[Jimmy]
Ooh! I just sprayed cereal all over the place! Did she manage to find
something shorter that "I will marry you", or did she go with "is
d=F3cha..." ("I suppose...")
[Rick]
She did indeed go with "I will marry you."
[Sluggo]
I suppose this "I suppose" sounds better than it does in English?
("Why not, I have nothing better to do today?" "Nobody better has
come along yet, so what the hell?")
[Rick]
That does remind me, as it happens, of Deirdre's favourite Irish joke:
John and Mary had known each other, and gone out to dinners and dances,
for well on twenty years. Mary, being rather shy, eventually gets around
to raising the subject, reminding him of this and adding:
"John, don't you think we should be marrying, then?"
"Aye, but who will have us now?"
[Jimmy]
Um... OK, when you were in Ireland, you must have heard the phrase,
"sure why not", or "sure we may as well" (where 'sure' is pronounced
'sher' and not emphasised)... it'd sound like that.
[Sluggo]
I don't remember that but I've heard "sure" alone in Scotland (and in
the movie Local Hero ) . Quiet and monotone. I'm used to a strong
"sure" meaning "I really like the idea",
[Jimmy]
Sure
[Sluggo]
a short but still forceful
sure being concessionary ("OK, that's fine"), and a long up-down-flat
"suurrrre" being ironic ("Sure you're going to the mall" [but I don't
believe it]). A quiet, flat "sure" to me sounds very concessionary,
as in "I don't want to do it but I'll go along with your wishes." I
had to tell myself, "That's not what they mean," and trust the words
rather than the intonation.
[Jimmy]
Um... I'm not sure (sure sure, not sure sure
, but I think the
Scottish use it the same way as we do. It doesn't really mean anything,
it's kind of an introduction to a sentence -- in fact, most of the time
it means you're unsure. Most Irish-type uses could be replaced with
"well" (or even "uh..."): "sure, you can take a later train if you miss
this one".
[Sluggo]
That's a different context. I'm talking about a one-word response to
a proposal or a yes/no question. In Local Hero , when the Texas oil
negotiator gets off the plane in Aberdeen and meets his assistant
Olson, he asks about logistics like "Do you have a car?" Olson
replies, "Sure." The negotiator is surprised that Olson just says it
like a boring fact ("Apples grow on trees") rather than anticipating
that the question imples, "Let's go." So half-exasperatedly he says,
"Well, let's go then." Probably Olson did not mean it that way, but
that's how it sounds to yankee ears, extremely detached, like the
speaker really doesn't care or something. It's hard to describe
because we just don't say "sure" that way, so we interpret it like
other phrases that are said that way.
[Jimmy]
(IIRC, there's a region in Poland (Poznan, possibly) where they do
something similar ("??ucho", I think)).
[Sluggo]
What struck me about Ireland was how so many accents sounded
indistinguishable from American. Only if you listen hard could you
hear faint traces of "foreign" intonation. At least a quarter of the
people I met were like that, if not a third.
[Jimmy]
Heh. You obviously weren't in Cork, North Dublin, Cavan, or rural
Tipperary, to name but a few of the areas with indecipherable accents.
I'm from rural Tipperary, but I rarely stand a chance.
Partly it's because there's a Hiberno-English tendency to speak short
sentences as if they were single words: "bulnfrish" or "blinfrit" are
two renderings I've heard of "bullin' for it"[1] (i.e., horny).
[Sluggo]
Like Mumbles in Dick Tracy.
[Jimmy]
[1] Thankfully, we managed to contain that phrase before it could infect
other areas, though there is still a high risk of breakout.
[Brian]
I would suspect that the easiest route would be to head over to Ireland,
get out in the countryside a bit, stop in pub and ask the first person
you see if they'd like you to buy them a pint. Virtually any answer you
get there should be fairly equivalent to "Yes!".
.brian (the empirical linguist)
[Sluggo]
Just be sure not to say "I will accept a beer" when you meant "I will
marry you".
[Jimmy]
Well, you know, think of Vegas weddings and it's not much of a stretch...
So, the more I read of this "Meaning of Tingo" book, and the
accompanying blog, the less I doubt the veracity of anything I read in
it,
[Ben]
Do you mean "less" or "more"? Those double negatives are tricky.
As
to "veracity", it doesn't apply to books; veracity is a habit, not an
absolute measurement. "Accuracy", maybe?
[Jimmy]
sigh Yeah. I'd just woken up, and my brain still hasn't started working
yet.
[Jimmy]
especially as the only Irish word so far is: "nabocklish: don't
meddle with it", which is... well, that may be a Hiberno-English word
in some part of the country, but "ná bac leis" means "don't pay
attention to *him*".
[Ben]
Ya gotta figure: in a book like that, effect is very important, so
bending the truth a bit to achieve it, well, it's not really that big
of a stretch...
[Jimmy]
Plus, it has to be taken into account that linguists are at the mercy
of the sense of humour of the person they are questioning; especially
difficult on the internet, where you can't see if they're having
difficulty keeping a straight face (one of the Philipinos at work told
me that "putang ina mo" means "hello", for example. If you're really
good friends with the person you're talking to, maybe...)
[Jimmy]
So, Kat, can you confirm that "ariga-meiwaku" means "an act someone does
for you that you didn't want to have them do and tried to avoid having
them do, but they went ahead anyway, determined to do you a favour, and
then things went wrong and caused you a lot of trouble, yet in the end
social conventions required you to express gratitude", because I can
think of several times where that would have summed things up
[Kat]
Other than the fact that I know this word as "arigato meiwaku", yes,
that's about the gist of it. "meiwaku" means bother/annoyance/imposition.
Of course the etymology of "thank you" in Japanese is peculiarly Japanese
in concept as well. Quoting from someone quoting the sci.lang.japan faq:
The word derivations are different too. Arigatou is related to
arigatai .kind, welcome. and arigatagaru .be thankful., which conveys a
grateful feeling for something that was done in favor of the one using the
word. The first kanji is aru (. Unicode 6709) .exist, happen. and the
second one, gatou < katai (. Unicode 978F) means .hard, difficult..
What would be most appropriate in this instance
[Kat]
Eek! That's really sweet, but in a Japanese context it's even more
bizarre. Declarations of love like that are meant to be private in
Japan, so something that would be framed and on a wall... Aiee.
[Jimmy]
At least he's not going for a tattoo
[Kat]
I'm not going there. I can't afford the bus ticket back.
[Jimmy]
Heh. I've been planning to geta tattoo of my son's name in Ogham. After
8 years of research, I'm reasonably confident that what I've chosen is
his name and not, say, "Price reduced for a limited time only" or some
such.
[Kat]
The trick now is to make sure it says "name", rather than "nayyun" or some
such close but not quite thing.
I'm still trying to figure out how someone got "Opoka" out of "Okopnik".
[Sluggo]
My Russian roommate Was Valeriy Pronin (vah-LEHR-ee PRO-neen) but the
border guards anglicized it to Valerie Pronine. So not only was he
stuck with a girl's name but people pronounced the last name
"pro-nine".
Then he married an Irish-American girl and changed his name to Michael
Sean Kennedy. That really throws people.
I went to Russia and his family met me at the airport. I was
expecting the Pronins but found the Dmitrochenkos. Turns out his
nickname was his given name. He and several buddies had changed
their name to Valeri Pronin after a buddy by that name died. I was
irritated that he hadn't told me his family's name was different than
his, because if his brother hadn't recognized me at the airport I'd be
looking around for Pronins and never have found them. Which was scary
because it was my first time abroad and Russia is not a very familiar
place. ("What if I get to my hostel at midnight and it's closed?")
Another friend was named Chris Norman. I went to visit his cousin in
Russia. Since it was his cousin I expected a different name. They
met me at a metro station in Moscow so
it was easy to find them. (I still don't like taking Russian suburban
trains alone. So easy to take the wrong train, and good luck
recognizing the station when they announce it.) Later in St Pete I
saw posters for Chris Norman, a musician, so I don't know if he did
something funny with his name too.
[Ben]
Heh. That would be a local dockmaster (from the UK, originally), with an
interesting policy on spelling:
(me) -- "Just backspace until you get to 'O'."
(him) -- "Naow, naow, mite. Oi *never* goes backwards, only forwards."
[clickety-clickety-click]
"There, 'at should do it!"
[Kat]
I'd swear it was a hand-written receipt, though.
That's okay, at least it wasn't like having one's drycleaning filed under
"rat".
[Kat]
Would she go for a Chinese hanzi (i.e. looks like Japanese kanji) thing
instead?
What you'd want in that case is "Wo ai ni", which is just fine.
Yes that'd be fine, what is the literal translation?
[Kat]
I love you, in Mandarin Chinese.
I should state rather strongly at this moment that I think you should find
a Chinese calligrapher to do this, as most people who are not learned in
the writing of Chinese characters make an embarrassing botch of it. You
can try googling "kanji tattoo" to see what most native speakers think of
the currently trendy usage of kanji.
[Rick]
Using a language in a culturally inappropriate way can actually be an
art form, y'know.
[Jay]
"Somehow, I knew who said this, without even looking at the attribution."
[Sluggo]
Exactly, and haikus have developed an independent life in English that
doesn't always fit with the Japanese tradition.
[Rick]
The interdependencies of language and mind are always fascinating,
as I started to realise when I learned French and realised that there
were particular modes of thinking that come naturally when "thinking in
French" but not in English, and vice-versa. (I'm straining to remember
examples, and, unfortunately, failing.)
[Ben]
I can't swear a tenth as well in English as I can in Russian. It doesn't
roll off the tongue, it doesn't sound natural, and... it's not polite.
%->
I love the russian langauge, don;t know squat, just like the way it sounds
I wonder if there are other phrases that may write better if you know
what I mean? Sound more traditional, even though you said declarations
like this are private, they must be "said" ?
I know not. I understand little.
[Kat]
You could do "Lisa daisuki" (Lisa (is) (my) favorite), which has a certain
"adolescent carved on a tree" charm to it.
I suppose the traditional thing would have been to compose a cryptic
impromptu haiku.
[Rick]
There you go! Pete, if I were you, I'd fire up my mad haiku (or at least
senryu) skillz.
[Heather]
Speaking as a girl here a haiku sounds sweet
I have a haiku
Beauty stealing breath,
Grace compared to angels high,
Always in my heart.
[Sluggo]
That's good. She'll know what it means. it's like the one we have
about Tux. Hints at it without explicitly saying it.
Bottom of the world
Fat, dark and handsome
Herring taste great
Now I need someone to show me what it is in Japanese
I need it written, so symbols, not just the words
If anyone has any clue, please let me know
[Kat]
Languages unfortunately are tied to cultures, and don't do well as simple
word substitutions.
[Rick]
Except as a form of comedy, e.g., the gentle art of "speaking Latin like
a native":
You're fired.
Ego te demitto.
Look out, I'm going to barf!
Cave, vomitorus sum!
Oh! Was I speaking Latin again?
Vah! Denuone Latine loquebar?
Your fly is open.
Braccae tuae hiant.
You're beautiful!
Pulcher es!
Your mother is so old, she speaks Latin.
Tua mater tam antiquior ut linguam Latine loquatur.
Show me the money.
Monstra mihi pecuniam.
Luke, I am your father.
Luke, sum ipse patrem te.
You don't know the power of the dark side.
Potestatem obscuri lateris nescis.
I think Elvis is still alive.
Credo Elvem ipsum etaim vivere.
Fuck you and the horse you rode in on.
Futue te, et ipsum caballum.
I have a catapult. Give me all the money, or I will fling an enormous
rock at your head.
Catapultam habeo. Nisi pecuniam omnem mihi dabis, ad caput tuum saxum
immane mittam.
I have a terrible hangover.
Crapulam terriblem habeo.
Your toga is backwards.
Tua toga suspina est.
We're off to see the wizard, the wonderful wizard of Oz.
Imus ad magum Ozi videndum, magnum Ozi mirum mirissimum.
Only you can prevent forest fires.
Solum potestis prohibere ignes silvarum.
I scream, you scream, we all scream for ice cream.
Clamo, clamatis, omnes clamamus pro glace lactis.
Stand aside, plebians! I am on Imperial business!
Recidite, plebes! Gero rem Imperialem!
I hope we'll still be friends.
Spero nos familiares mansuros.
God, look at the time! My wife will kill me!
Di! Ecce hora! Uxor mea necabit!
You know, the Romans invented the art of love.
Romani quidem artem amatoriam invenerunt.
Nobody dances sober unless he's insane.
Nemo saltat sobrius nisi forte insanit.
Nu, everyone's a comedian.
Quisque comoedum est.
[Heather]
For the record this made me giggle out loud:
> Oh! Was I speaking Latin again?
> Vah! Denuone Latine loquebar?
I swear I could hear Rick saying this in my head...
[Sluggo]
Of course I couldn't resist translating these to Esperanto.
Ho! Cxu mi parolis latine refoje?
But more colloquially:
Ho! Cxu mi krokodilis latine refoje?
"to crocodile" comes from a character in a children's TV show. The
crocodile kept babbling in his native language at Esperanto events.
[Ben]
I don't suppose you recall the Russian humor gazette, "Krokodil", or
"Krokodil Gena" (a cartoon croc who later featured as the butt of many
jokes; most of these were, unusually for Russian jokes, characterized by
a certain innocent sort of humor.) For some reason, Russians seem to
associate crocs with humor.
[Sluggo]
I've seen it. That doesn't mean I understand the jokes.
I remember one political cartoon. One side of a chessboard was all
lined up orderly; the other side was squabbling. One from the unruly
side goes up to the other and says, "U vas yeschyo korol' s korolevoy?
A u nas uzhe yest' parliament." (You still have a king and queen?
We have a parliament.)
[Heather]
> Luke, I am your father.
> Luke, sum ipse patrem te.
[Sluggo]
Luk, mi estas via patro.
Not "Luke" because "luko" means skylight, so "luke" means skylight-ly.
"luk" alone would be a preposition or interjection, but since there's
no such word it's safe for a foreign name. The accusative would be
"Luk'on", the standard way to add a suffix to a non-Esperantized name.
[Heather]
> You don't know the power of the dark side.
> Potestatem obscuri lateris nescis.
That was pretty good too.
[Sluggo]
Vi ne scias pri la povo de la malhela flanko.
[Heather]
But this combo takes the cake:
> I have a catapult. Give me all the money, or I will fling an enormous
> rock at your head.
> Catapultam habeo. Nisi pecuniam omnem mihi dabis, ad caput tuum saxum
> immane mittam.
[Sluggo]
Mi havas katapulton. Donu al mi cxiun vian monon, aux mi jxetos
grandegan rokon kontraux vian kapon.
[Heather]
> I have a terrible hangover.
> Crapulam terriblem habeo.
[Sluggo]
Mi havas teruran postebrion.
[Heather]
Final translation?
Go ahead, shoot me. I won't notice, because the chariot racers of Saturn
already ran me over.
[Sluggo]
Nu, pafu min! Ne gravos al mi, cxar la cxaraj konkursantoj jam superkuris min.
Oops, "cxaro" (chariot) looks like a nounization of "cxar"
(for/because). Perhaps it slipped into the language without people
noticing. Also, I substituted "it doesn't matter to me" (ne gravos al
mi) for "I won't notice" (mi ne konscios) because it sounds more
typical.
[Heather]
But how do you say:
Argh, I cannot get my wireless to work! Hand me that ubuntu disc.
[Sluggo]
Fusx, mi ne povas funkciigi la radiofonon! Donu al mi la diskon de Ubuntu.
[Ben]
Yeah, I often say that - at least the first word - when I'm feeling that
kind of frustration. Only you've misspelled it.
[Sluggo]
That's a different word: fik.
[Sluggo]
fusx: exclamation saying you're too scatterbrained to do something
right, or something just isn't working out.
[Ben]
Yah, I use it that way too. A lot.
[Sluggo]
funkciigi: to cause to work.
The most amusing phrase is:
Ho, kio jenas en mia posxo? Cxu molaso? Diable. Dacxjeto! [1]
Well, what's this in my pocket? Molasses? Damn. Davey!
jen: behold, voila. Turned into a verb.
diable: devil-ly
Dacxjeto: from "Davido" (David). "cxj" makes an affectionate
nickname. "et" is a diminutive, in this case implying a child.
[1] From Being Colloquial in Esperanto by David Jordan.
[Rick]
As we say in California:
"Habetis bona deum."
[Sluggo]
Perhaps look for an expression that's similar in English and Japanese
rather than the closest translation to "I love you". I don't know
Japanese but maybe something like "Lisa is my favorite" or "Lisa is
the one". Even if it doesn't say all of "I love you", she'll remember
the unspoken part every time she sees it. And when a Japanese guest
sees the scroll, maybe they'll think, "I wouldn't say that but it
sounds pretty cool."
[Kat]
While you're not far wrong in principle, I think what you're missing is
that any sort of declaration like that is by its very nature (of being a
public declaration) somewhat juvenile from a Japanese perspective. It's
not just about the wording.
Now, doing the equivalent of building the Taj Mahal, that would translate
just fine.
[Jimmy]
"We have to include a lot of adjectives and adverbs to get across
details of people's feelings, while Japanese verbs often contain these
subtleties already. One result of this is that Westerners make strange
blunders in Japanese because they are unaware of which emotion the verb
they have chosen conveys."
It's not that "love" has unusual subtext, it's the action of declaration
is sort of...Hmm. It's like "I'm going to kiss you now". That would be
weird, yes?
[Jay]
Not if you're going to Antioch.
[Sluggo]
Maybe just "Lisa" then, or "Lisa the painter" or "Lisa --
mathemetician" or whatever she's good at. Then it can look like a
simple gift rather than a "declaration".
[Kat]
Oh, now that would be more than a simple gift, it would be very very
appropriate. Even better would be getting her a seal that she could sign
her work with.


![[BIO]](misc/cover/ubuntu.png)
![[BIO]](misc/cover/gnu.png)
![[BIO]](../gx/2002/note.png) Heather got started in computing before she quite got started learning
English. By 8 she was a happy programmer, by 15 the system administrator
for the home... Dad had finally broken down and gotten one of those personal
computers, only to find it needed regular care and feeding like any other
pet. Except it wasn't a Pet: it was one of those brands we find most
everywhere today...
Heather got started in computing before she quite got started learning
English. By 8 she was a happy programmer, by 15 the system administrator
for the home... Dad had finally broken down and gotten one of those personal
computers, only to find it needed regular care and feeding like any other
pet. Except it wasn't a Pet: it was one of those brands we find most
everywhere today...
 AOL emulator
AOL emulator Just Bad and Wrong... yet cool
Just Bad and Wrong... yet cool

 Greetings from Heather Stern
Greetings from Heather Stern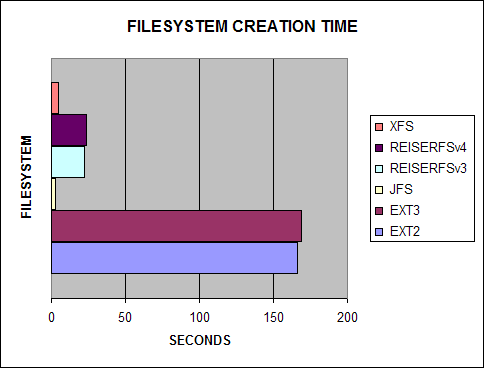
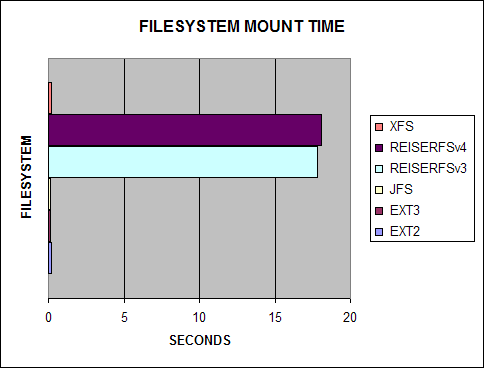
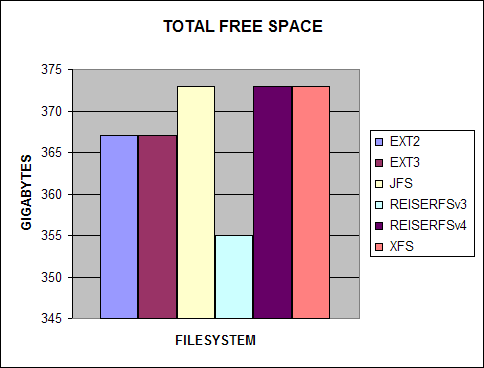
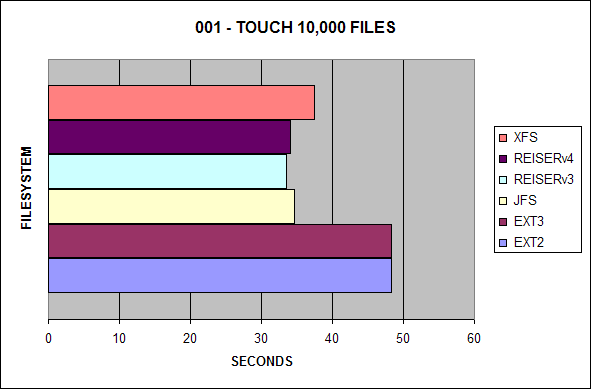
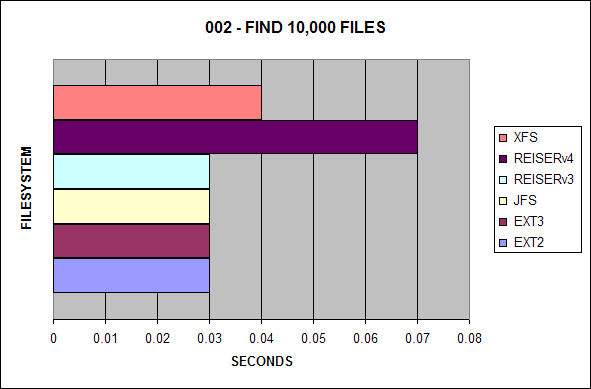
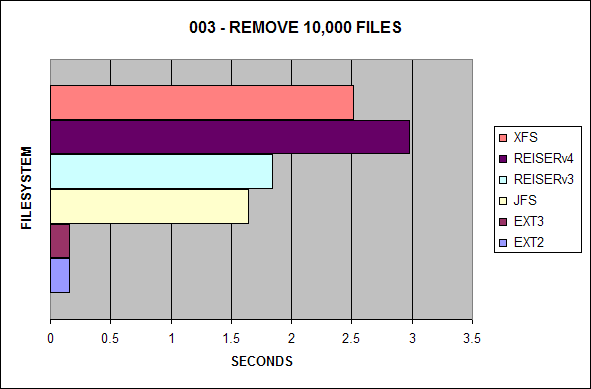
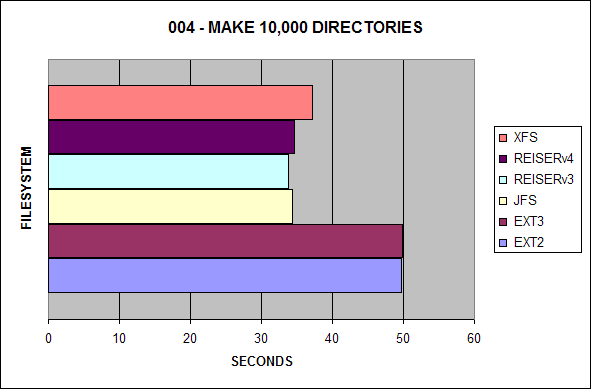
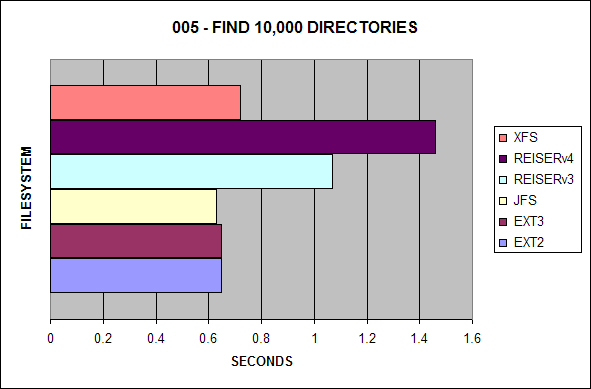
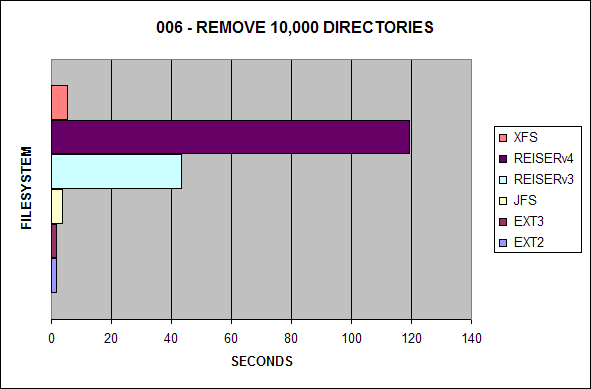
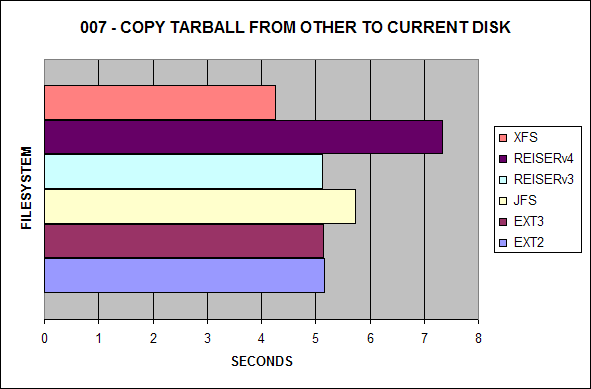
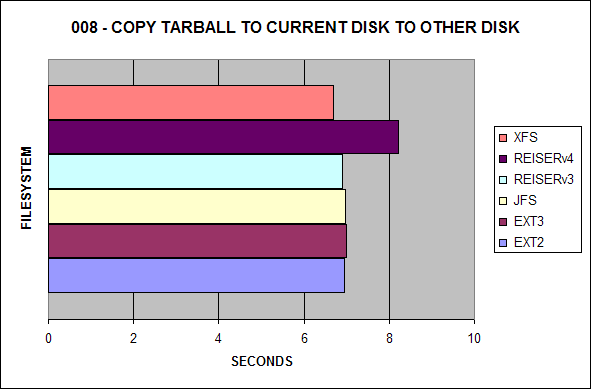
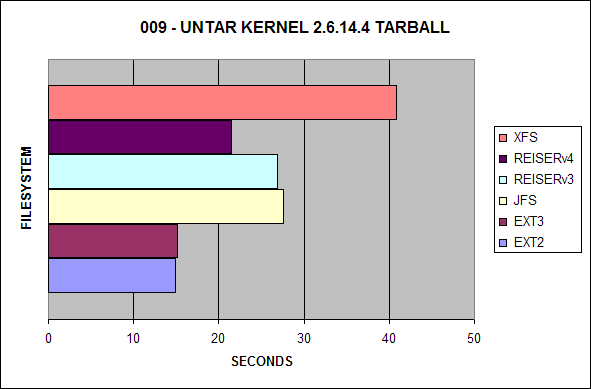
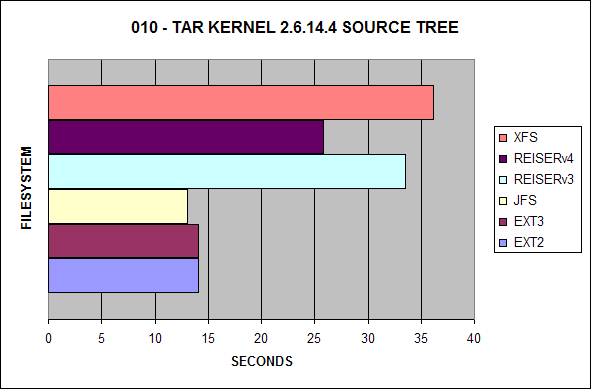
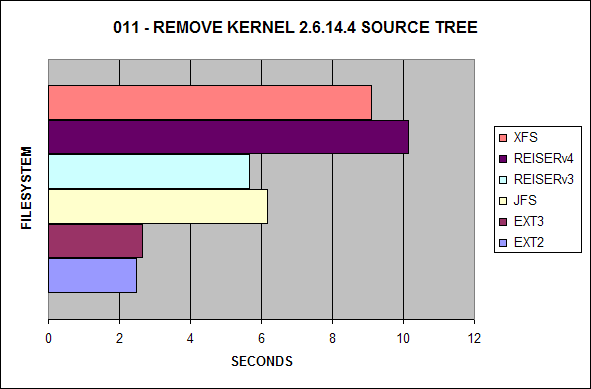
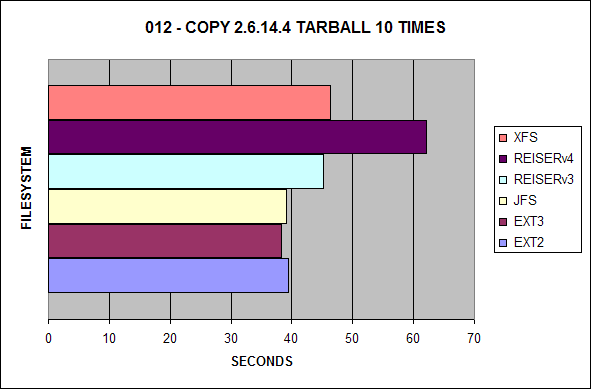
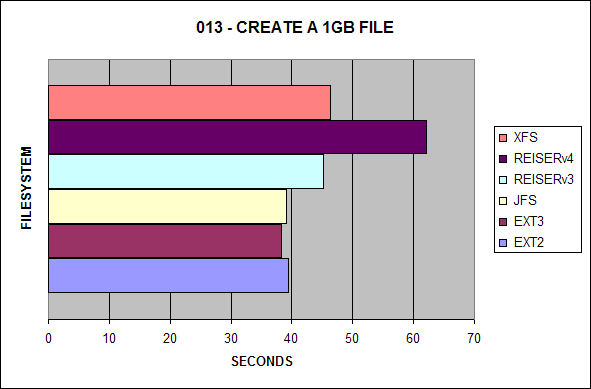
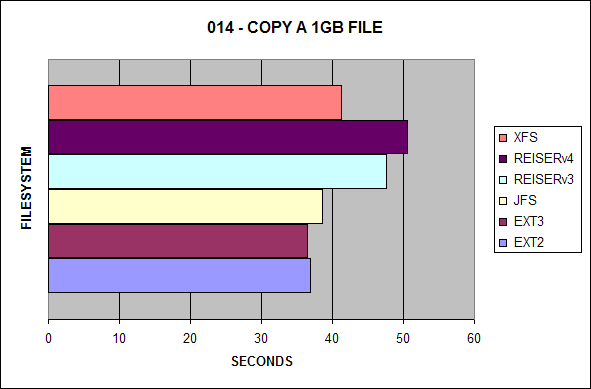
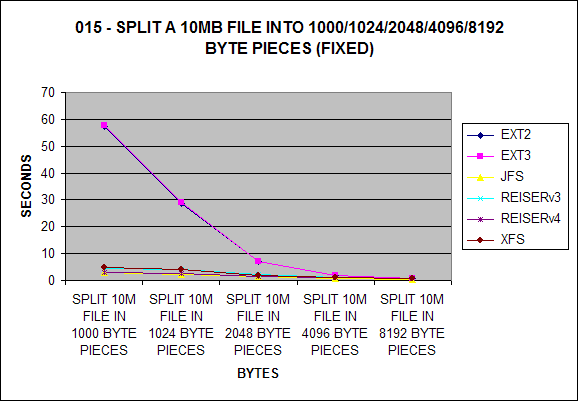
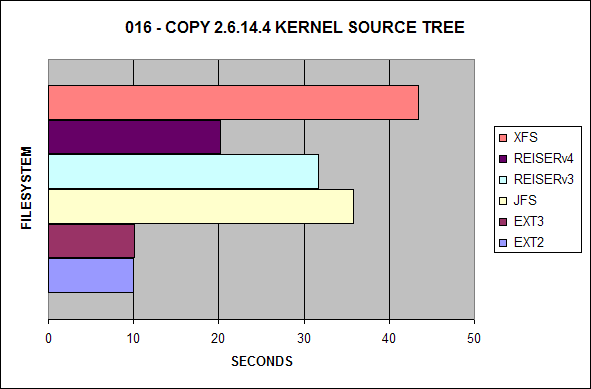
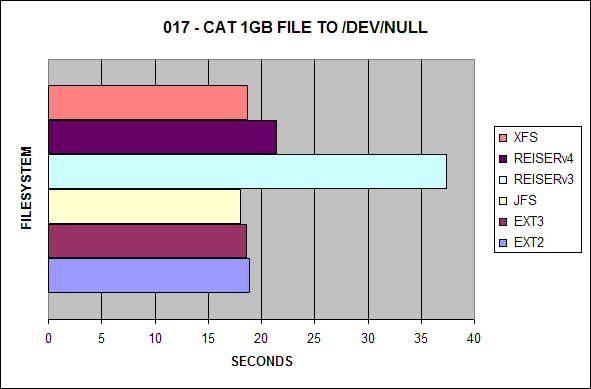
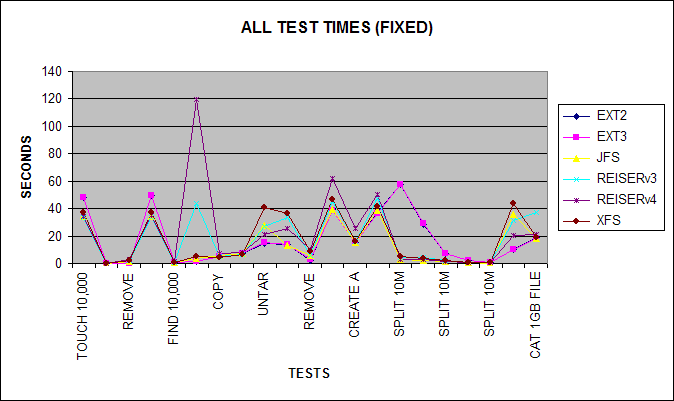
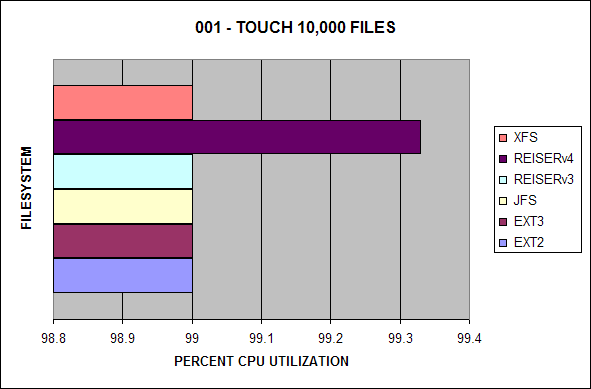
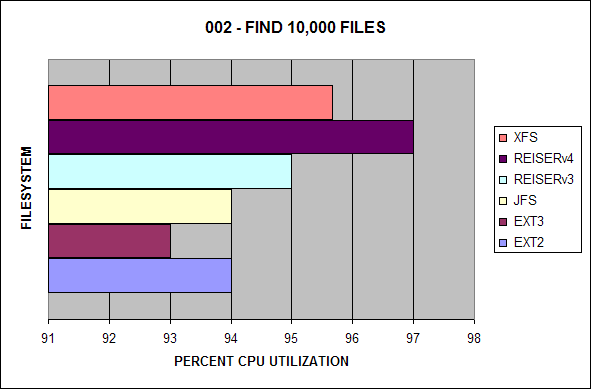
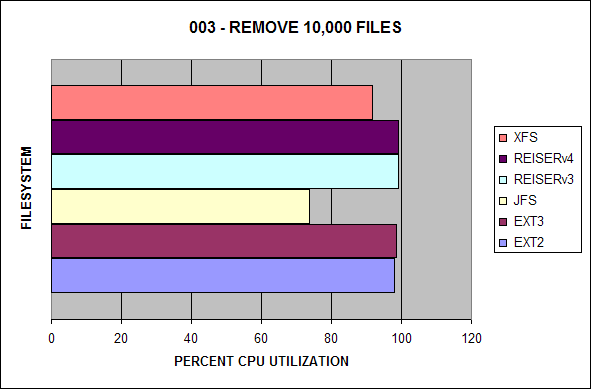
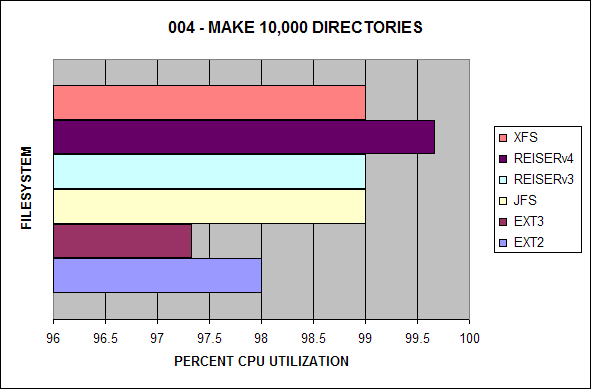
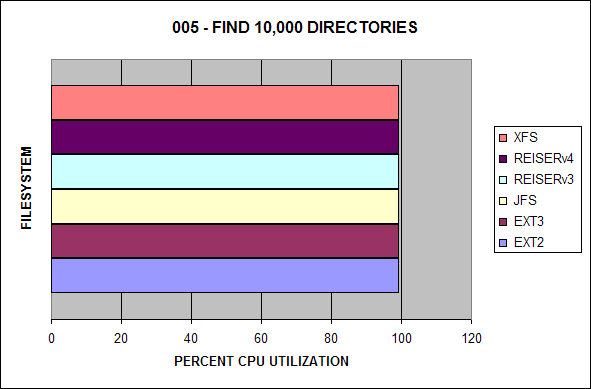
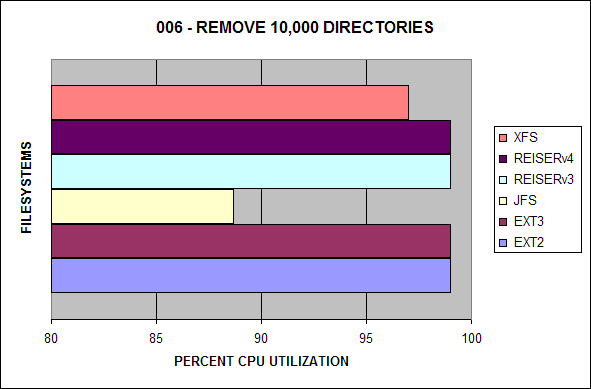
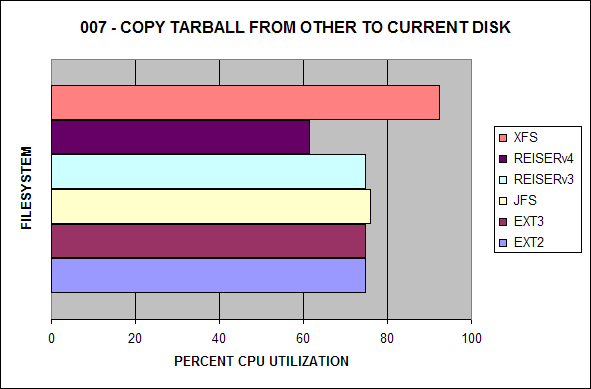
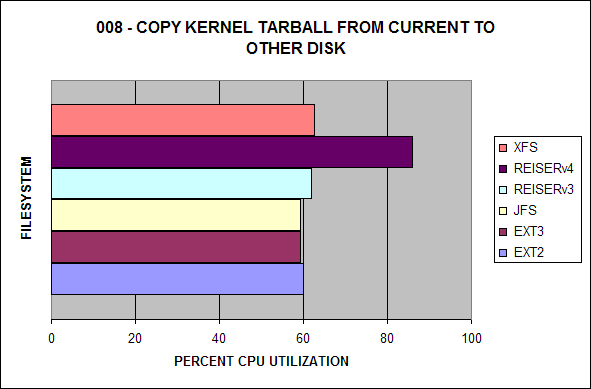
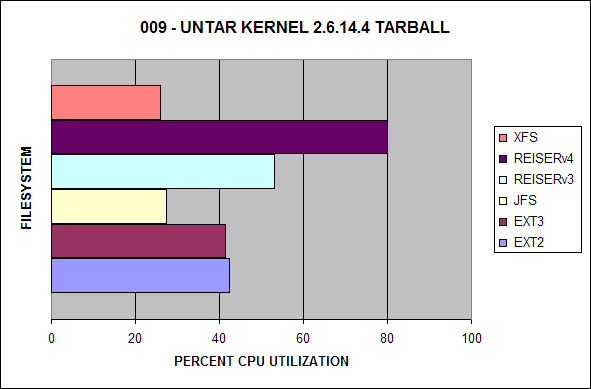
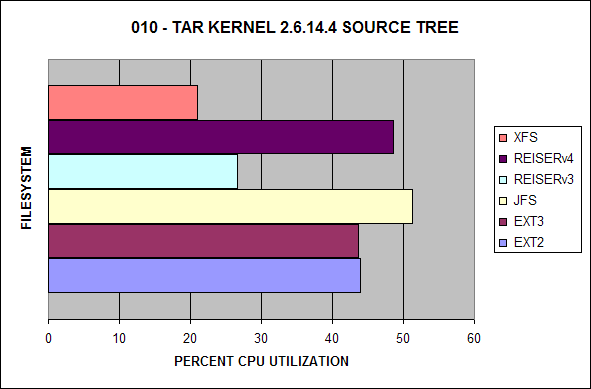
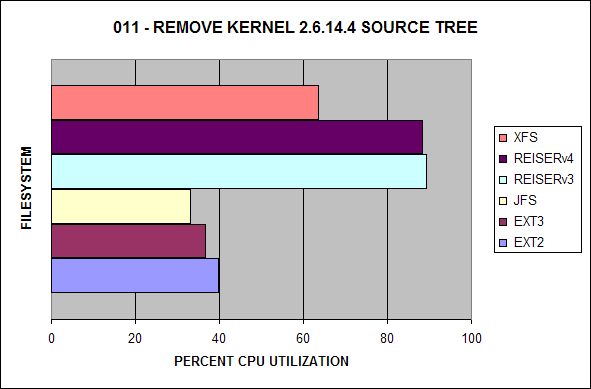
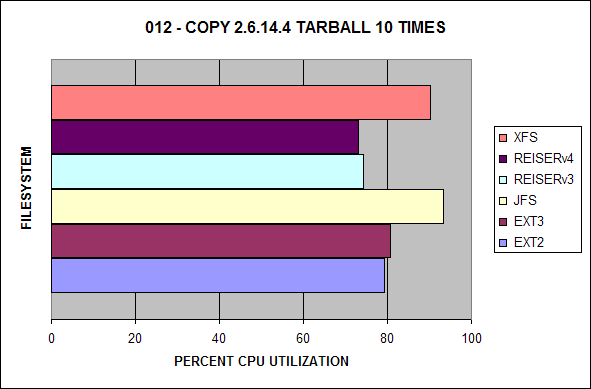
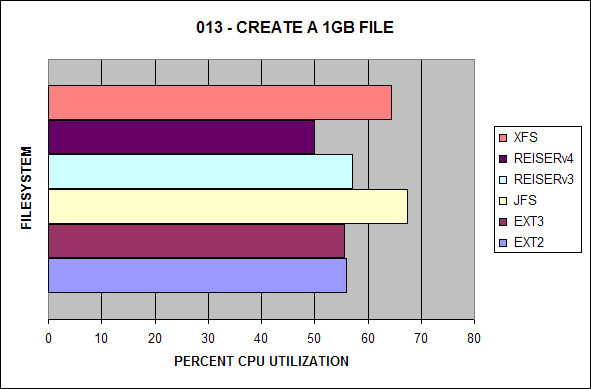
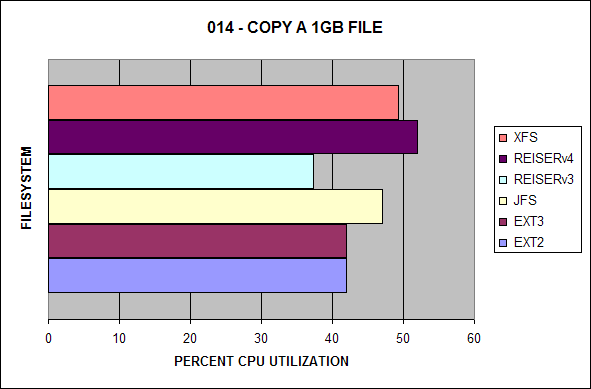
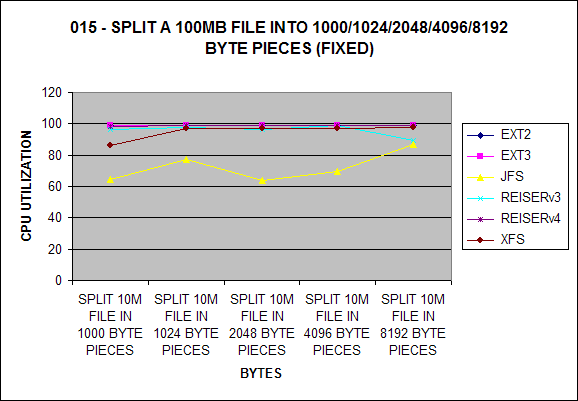
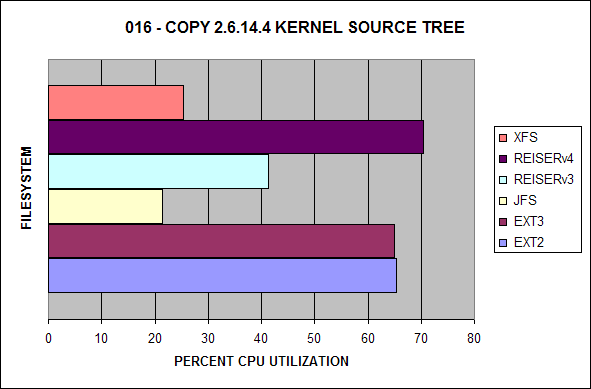
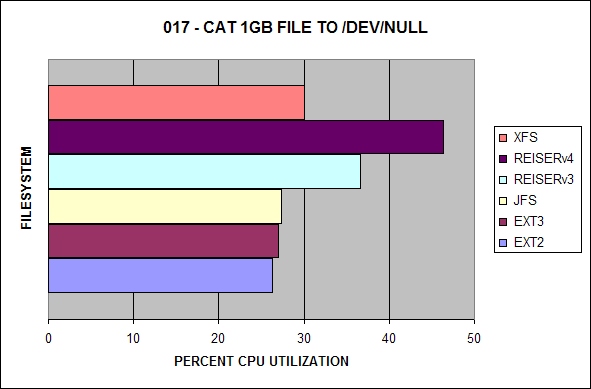
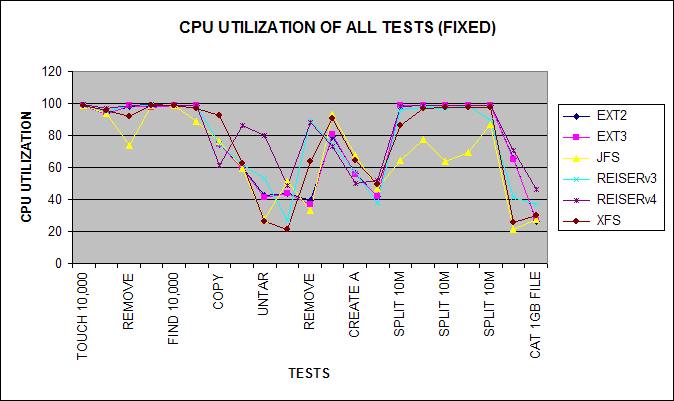
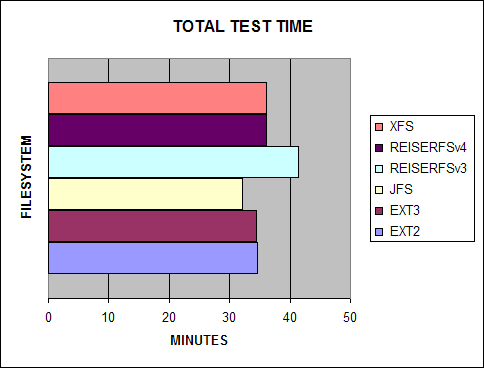

![[BIO]](../gx/authors/smith.jpg)
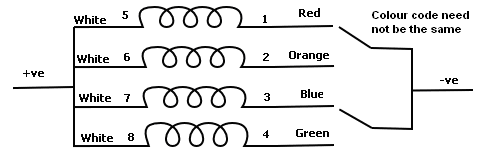
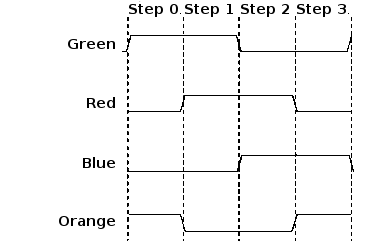
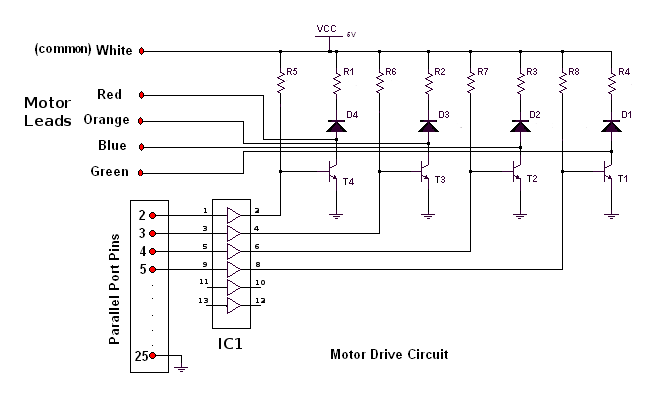
![[BIO]](../gx/authors/sreejith.jpg)

{kind=link}
{kind=link}
{kind=link}